-
Secure your app: threat modeling and anti-patterns
It's more important than ever to consider vulnerabilities and potential threats and recognize where you should apply safeguards in your app. Understand how to identify potential risks through threat modeling and how to avoid common anti-patterns. Learn coding techniques and how to take advantage of platform-supplied protections to help you mitigate risk and protect people while they're using your app.
Resources
Related Videos
WWDC20
-
Search this video…
Hello and welcome to WWDC.
My name is Richard Cooper, and this session is all about how you can make your applications more secure, protecting the data and resources users entrust to you. Here at Apple, we're passionate about ensuring applications handle data correctly, respecting users' privacy, and that software is designed to be robust against attack to ensure that that effort isn't undermined. My team works with software and hardware teams within Apple to help them improve the security of what we're building and find issues in things we've already built.
We'd like to share with you some of the techniques we found useful. In this talk, we're going to cover some ideas about how you can think about security in the context of your application.
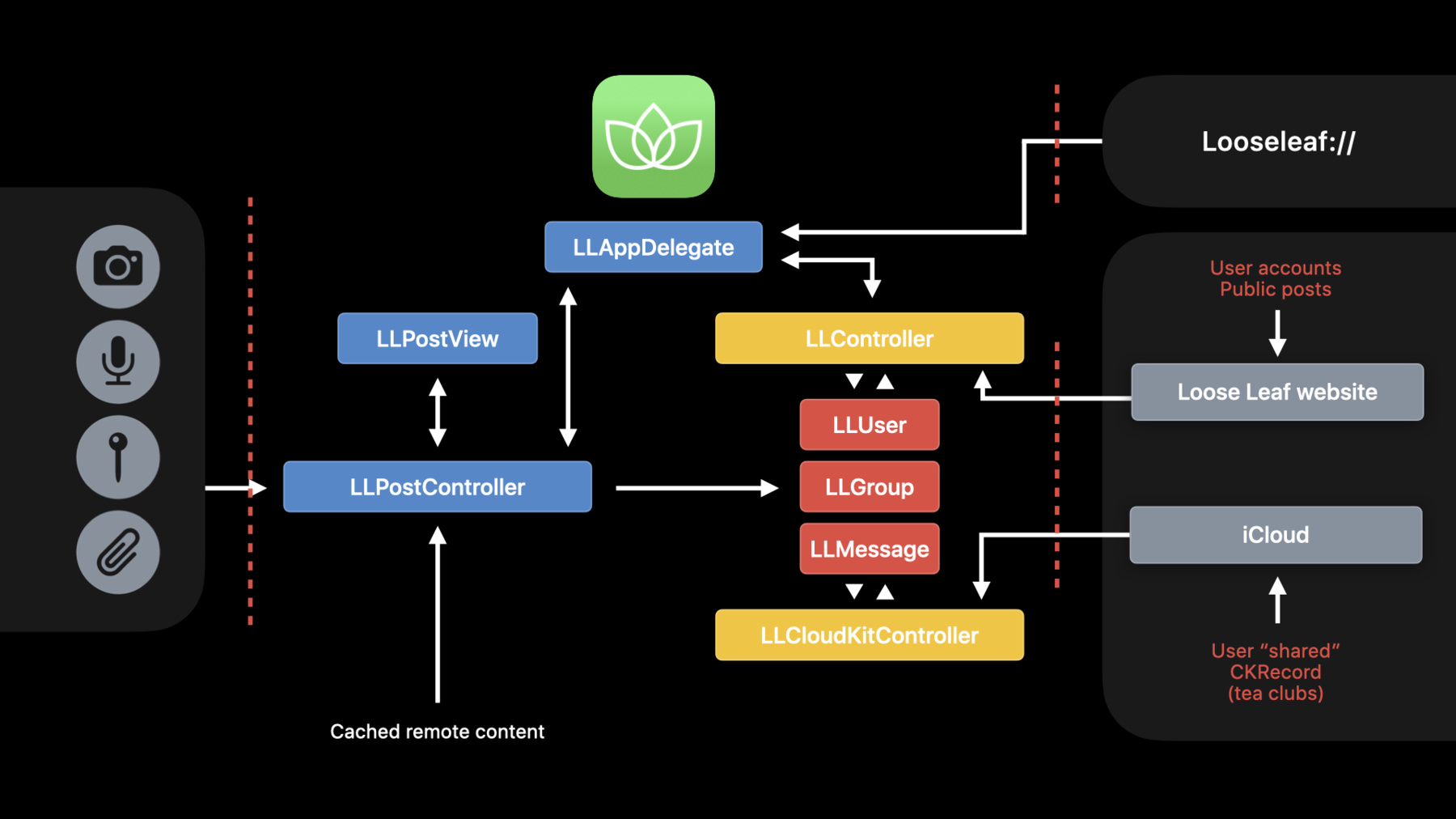
To do this, we're going to talk about threat modeling, how to identify untrusted data, and go over some common mistakes we see people making. To help visualize the problem, we're going to use a simple hypothetical application called Loose Leaf.
We've got high hopes for Loose Leaf and expect it to become the leading social platform for hot, cold and bubble tea drinkers. Perhaps even coffee too.
To make this happen, we're gonna support these great features: We want social networking so you can share your activity with the world, the ability to use the camera to take photos to post but also to create live-action pouring videos.
We also want to support private tea clubs, allowing you to talk with just your friends. Finally, we're going to have the ability to support longer form reviews, pairings, etcetera.
Whilst it's quite a simple example, it has many features in common with popular applications. The first thing you want to do when looking at your app is to stand back and think about the threat model. Threat modeling is the process of thinking about what can go wrong in the context of security, and it is important, as it allows you to consider what risks you face and what you can do to mitigate them.
We're not going to describe a specific formal process, as for many developers, learning and following one simply wouldn't be practical.
Instead, we're going to describe some strategies you can use for threat modeling and which will help you think about security and risk. So, how do we do this? One of the key things your application has are assets.
These aren't the assets you would find in an Xcode asset catalog, but the things the user might consider valuable, sensitive, or private. Camera and microphone, location data, contact information, and photos and files are all really good examples of assets, and why we've been working hard over the last few years to provide platform-level protection of many of these things.
As a general rule, if the user was required to grant access, it's an asset.
In doing so, they are delegating control of it to you, so you need to concern yourself with how to protect it. But there are other things which also represent assets.
Opinions and views which users enter into your application are a hugely important asset.
Whilst platform protection can help, it's a class of asset where you need to be particularly careful and ensure to adopt those protections. Now, no threat model would be complete without attackers.
These can be the obvious ones: criminals who want to steal from your users or competitors who want to undermine your platform, but we should also consider other classes of attacker who might have different levels of access. Romantic partners and family members are good examples of these.
So you should ask yourself, "How do I protect against these attackers?" This is important, as they often have vastly different levels of access to a device, both physically and through shared accounts. Whilst you might not think Loose Leaf is interesting to these attackers, if we have access to useful assets and are as successful as we intend to be, we can become a target. Attackers regularly attack social media, banking, productivity, dating apps, and even games, so nobody is immune.
In general, who the attacker is is actually less important than what capability they have and how that can be used to affect us.
To help us visualize what data the attacker can control and where it goes in our application, we recommend doing a data flow diagram. To start, draw out where the data stores in your system are.
In our case, we've got some information hosted on our website. We're going to use that for public posts, account information, etcetera.
Some information is also stored in CloudKit, allowing us to have decentralized tea clubs...
and a cache, which is going to store local versions of posts and images. Ultimately, these are gonna be the places where user sensitive information is persisted.
Next, we should add in system resources we leverage. We should also think about other ways data might be able to make its way into our application.
In our case, we have a URL handler, which allows links to be passed to us.
Finally, we need to decide where the security boundaries should be in our system.
Placement of these is really important, as it provides the basis for all the decisions we're gonna make about what we do and don't trust. The key question to ask yourself here is, where can attackers influence my application, what data is attacker-controlled, and how can they use that to gain access to our assets? In our case, we're going to place a boundary here, between the system resources and our app.
Whilst we trust the system, the content is uncontrolled.
For example, a file selected by the user might have come from an untrusted source, so if we process its content, we need to be careful.
Custom document formats being a great example of where this can happen.
Other local applications are also untrusted to us, so we'll place a security boundary at the URL handler, as the data provided may be malicious.
We're also going to place another boundary between our app and all of its remote assets. Even though it's our code which should've written the data into these remote stores, that might not be the case. An attacker may have written software to craft a malicious post. With this understanding of where attackers can influence our system, we should think about architectural ways to secure it. This is particularly relevant here, on the connection between our app and our website.
We at Apple have provided a generic mechanism for strengthening these connections called App Transport Security.
ATS ensures that all connections your application makes via the URL system offer sufficient protection to user data as it transfers over the Internet. ATS is on by default, but to make use of it, you need to ensure you use the higher level APIs like NSURLSession and friends.
As such, you should make development policies to ensure their use over lower-level APIs.
You also want to make sure you don't ship with any ATS features disabled in your Info.plist.
Equally, you want to think about the format you use to store data, both on the server and locally.
In general, you want to choose a format which is simple to parse and easy to validate.
plist and JSON are both good choices, balancing flexibility against security. Formats where you can perform schema validation, though, are ideal, as these provide strong checking and centralized logic.
We also want to think about how to protect user data in these stores. Is CloudKit protection sufficient for a tea club, or should we also be manually encrypting the data ourselves? When we laid out our security boundaries, we didn't place one between the local cache and the app.
Our reasoning here is that we shall validate the data on the way into the app, and any locally-stored copy can be trusted. On iOS, this is a strongly enforced guarantee, as other apps can't change our local files. But on macOS, that's not true. So we may need to reconsider how we protect this data if we plan to support macOS.
We should also think about third-party dependencies. What libraries are we using, is their approach to security consistent with ours, and is testing sufficient to allow quick updating of these dependencies? Now that we've found ways to mitigate risk architecturally, let's have a look inside our application at the implementation. In our app, there are three main classes of object: those responsible for retrieving data from external sources, those responsible for parsing that data and converting it into a model, and those responsible for displaying the data to the user.
What we want to do is identify which is which, and where the highest risk areas are, as these are the parts which will most directly work with attacker-controlled data, and thus, where we need to be most careful.
Data stored on remote servers is one of our highest risks. The information stored on our website can be created by any attacker, so we need to take a lot of care when handling it.
Data in our tea club, though, can only be modified by its members. CloudKit ensures that.
Here, the set of attackers is more restricted, and so the level of risk depends on which attackers we consider part of our threat model.
We can now follow this data flow through our system and get a corresponding risk profile.
Components responsible for transferring the data have some risk. And this is particularly true where you have an interactive connection with an untrusted entity.
But those which process the data and are responsible for its validation are the highest risk. Note we've excluded the servers here, as they're out of scope for this discussion.
We can do this process for our whole app and get a view of where risk lives, where we need to be most paranoid, and where we're most likely to make mistakes which will result in security issues. So to recap: Identify what assets your system has and think about how you can design to protect them, particularly how to protect your data in transit and at rest.
Identify where attackers can influence your application, tracing that data through the system so you can understand where the high-risk components are and can plan to mitigate issues that might occur during implementation.
Now, over to Ryan to talk a bit more about untrusted data. Thanks, Coops. So, before we even begin to secure our applications, we have to be able to identify how untrusted data is getting in. Well, what is untrusted data? It's simple. We're gonna always assume that external data is untrusted unless you're in control of it. And when you're not sure if you're in control of it, assume the worst. Let's see some simple examples now of how untrusted data can get into our apps.
You may not realize it, but if your app uses custom URL handling, the URL is completely untrusted and can come from anywhere, even from someone you don't expect sending it to a user over iMessage.
Similarly, if you have a custom document format, there may be vulnerabilities in parsing it that could compromise your application.
The first action we want to take is to figure out all the data entry points so we can begin to see how the untrusted data is being handled by our application. Now that we've already done our data flow diagram, we should have this information available. This is just an example and is by no means an exhaustive list of every entry point that iOS and macOS exposes to your application. Most commonly, our application probably deals with some amount of networking. This represents the highest relative risk for handling untrusted data, as an attacker can target a user without needing to be in physical proximity to the user's device. This can be in the form of talking to your server over HTTPS, peer-to-peer communication, such as real-time video calling, or even Bluetooth communication. In our example, Loose Leaf has a few features which process untrusted data from over the network. And because we care about the privacy and security of tea fanatics, we've implemented end-to-end encryption for all of our device-to-device messaging. Now, we won't get into exactly how to implement encrypted messaging, but it's critical that we understand an intrinsic property of these types of security technologies when we're developing secure applications. Encryption does not imply the message is trusted and valid. To put that simply, I can know with cryptographic guarantees that the message is from my friend, but that doesn't mean my friend isn't trying to hack me. The contents of an encrypted message are still untrusted data. Okay, so we know our application gets some messages over the network. And then typically we'll do some message processing here. That could be some decryption or verifying a cryptographic signature, for example.
Then it will get to the point where our application will want to read the contents of that message. And now our job is to look at these messages and figure out what's trusted, what's untrusted, and then we'll be able to see how we're using the untrusted data. So we might take a look at our protocol and find that this sender e-mail address is a verified sender address. In our example, this is cryptographically verified, so it can't be spoofed and can't be something that we don't expect. So we can trust this.
Then we look at the message identifier and find that it's partially controllable. When we say something is partially controllable, we typically mean that it's bound to some range of values or some specific type. For example, this has to be a UUID, but someone could still send us any valid UUID.
Then we look at the message payload and find that it's completely sender-controlled. This means that they can send us any arbitrary message payload, and it might not even be in the format that our application expects.
So with anything that's sender-controlled, we have to make sure that we validate and sanitize this untrusted data before using it. Okay. So far, we've seen how to identify and classify untrusted data. Now, let's look at some common ways for how untrusted data can be mishandled, so you can learn how to find bugs like these in your own applications.
We're gonna look at a path traversal bug here, which is a very common type of security bug that you may find in your own application.
Now, in Loose Leaf, we have the ability to send photos of your tea latte art to your friends, and it looks like this is the code that handles that.
In this example, we're taking the downloaded photo, and the goal here is to move that into a temporary directory so we can use it before the system deletes the downloaded file.
The first thing we want to do is look at what comes in to the method here. Our goal is to figure out what's trusted, what's untrusted, and see how we're handling the untrusted data.
So we take a look at our method here and find that this incoming resource URL is a random file name. It's generated locally on the device when the file is downloaded from the Internet. It can't be influenced by the sender, so we can trust that.
Then we look at the fromID here. That's the verified sender address. In our example, this is cryptographically verified, and so it can't be spoofed and it can't be something we don't expect. So we can trust that.
Then we take a look at the name here, and this is completely sender-controlled. This is what they're telling us the name of the file is, but they can send us any arbitrary string here. So let's see how we're using it.
We take the name and pass it into appendingPathComponent to try and build this destination path in our temporary directory. What happens if they send us this string with any number of these backtracking components at the beginning of it? Now they've managed to traverse outside of our temporary directory, and when we copy the file, we'll be copying it into whatever arbitrary location the sender has given us. So, obviously, this is pretty bad, as it can overwrite potentially sensitive files accessible in our application's container.
So you might take a look and go, "Okay, I'll just take the lastPathComponent here." And in this example, that would work. It would give you the safe file name. But it will also return this if the last components are the backtracking ones. So we can still potentially overwrite sensitive files for our application.
Another mistake we can make using lastPathComponent is if you build the URL manually using URLWithString, because lastPathComponent will still return this if the slashes have been encoded with percent encoding. And when we go to use the URL, it will decode the percent encoding, so they've still managed to make us traverse outside of our intended directory.
So, what's the correct way to do this? We'll take lastPathComponent on the file name and then make sure that there's actually still a file name there. We'll make sure it's not equal to these special path components. Otherwise we bail out and refuse to process the file. And we also have to make sure to use fileURLWithPath, which will add additional percent escapes so we're not vulnerable to these kinds of percent encoding attacks.
So, what have we learned from this? Don't use remotely controllable parameters in file paths. It's so easy to get this wrong. If you have to, use lastPathComponent along with additional validation and sanitization, as shown in our example.
And always make sure to use fileURLWithPath, which will add additional percent escapes to your file paths so you're not vulnerable to these same percent encoding attacks. But generally, just try and avoid this pattern if you can. Just use a temporary file path with a locally-generated and random file name. Some actions you can take right now are to check for all uses of untrusted strings being passed into the following methods. Another example of mishandling untrusted data is uncontrolled format strings. So, we might have some method like this in our application, where we get a request message from a device and then generate a response from it and send the response back to them.
We're going to do the same exercise here. We want to look at our method and figure out what's trusted and what's not trusted, and then figure out how we're using the untrusted data.
So we look into it and find out that this name is the local user name on the device. It's generated locally and can't be influenced at all by the sender, so we can trust this.
But then this request they're sending us is again the sender-controlled payload. They can send us any arbitrary request message, so we can't trust that.
So let's see how we're using that parameter. Well, we're taking the request, and then we're grabbing this localized format string off the request and passing it to NSLocalizedString. So the goal here is to generate the correct response in the user's local language on the device.
But again, this is just an arbitrary string, so they can send us anything here, even if we can't localize it. Now when we pass it to string with format, there won't be enough arguments here to correctly format the string.
So what ends up happening is, we'll actually be leaking the contents of the stack and sending that back to the person. This can potentially reveal sensitive information from your application's memory, or in some cases, it can even allow an attacker to take control over the execution of your application. So we definitely want to avoid this.
So what have we learned from this? Never use or generate a format string specifier from untrusted data. There's actually no correct way to do this, so just avoid this if you can. Don't try and validate or filter the format specifier either. You'll probably get it wrong.
Make sure that you don't have the format-security compiler flag disabled. It is on by default, but make sure you're not disabling it for a section of code. But we have to be aware there are some cases this will not catch. For example, the one we just looked at won't actually give you a compiler warning because in some cases, the compiler can't do anything to reason about the format string if it's not a string literal.
You also have to be extra careful with format strings in Swift, because Swift doesn't have the level of compiler validation for format strings as C or Objective-C has.
So in Swift, you want to use string interpolation wherever possible. Sometimes you have to use format strings, such as when you're building these localized strings. We just have to be extra vigilant not to introduce bugs like this.
Some actions you can take right now are to check for all uses of untrusted strings being passed into the following methods as format specifiers. So we've looked at two common security issues so far that are generally easy to find when you know what you're searching for. But it's not always straightforward. A lot of the time you'll find logic issues that untrusted data can take advantage of to make your code flow in unexpected directions. The first one of these we'll look at is state corruption issues.
In Loose Leaf, we've added the ability to enter a live stream brewing session with your tea club members. To do this, we follow an invite-based session state machine here, where I can invite someone to a brewing session, and if they accept, we'll end up in this connected state, where I might share a live stream from my device's camera.
Let's dive in a little deeper here and look at what will transition us between these states.
So I can send someone an invite, and I'll end up in this inviting state and they'll end up in the invited state.
If they accept the invite, we'll both end up in this connected state and might now share this connected socket between our devices.
But what happens if I send someone an invite but also send them an inviteAccept message? Can I force them into this connected state without them actually having accepted our invitation? Well, let's take a look at the code here for this.
Now that we understand the difference between trusted and untrusted data, we should be able to go through here quickly and see that this is the verified sender address, and I can trust this. And this is the sender-controlled message, so I can't trust that.
So what's happening here is we're taking the type out of the message and dispatching it to some other handler based on the type of message.
But again, this comes from the sender-controlled payload, so they can still send us any message type here. Now, in this case, we want to look at the inviteAccept message, so let's jump into the handle there.
It looks like we're checking that the session exists based on the session identifier that the sender gave us, and then we're setting the state to "connected." It looks like in this case, the sender can actually force us into this connected state. We're probably missing a check here. We probably want to check that we're actually in the inviting state and are expecting to receive an "invite accept" message before transitioning.
So, is this enough? Well, probably not. There's probably some other checks that we want to do, some state invariant that has to be true before proceeding. So in this case, we want to ensure that the inviteAccept message that will transition us is coming from someone we actually invited.
So what have we learned here? We want to define clear state invariants that must be true before proceeding. But as we saw, this can be really subtle and easy to get wrong. In our example, it wasn't just as simple as checking that we're in the correct state, and there were other properties we needed to validate before proceeding.
And we want to bail out early on and refuse to proceed if any of these checks fail, as we don't want our code to go in unexpected directions that could potentially modify the state. Another common logic bug you might find is piggybacking on untrusted data.
So in our application, we might do a lot of message processing, where we take some JSON data the sender gave us from over the network and create a dictionary from it that has this remote entry on it.
Then after we're done processing, we tack on this other entry to the dictionary. And now you pass that dictionary to another part of your application, perhaps to modify the UI or the database.
And when it gets to that part of your application and it's time to use it, now we have to figure out what's trusted on it before we use it. So you might take a look at the dictionary and go, "This is the remote entry. And I know this is the sender-controlled entry because I know it's sent over the Internet. But this other entry, can I trust that?" Well, you might think you can, because you know it's generated locally by your application, so it can't be sender-controlled. But it turns out, of course we can't trust it because it comes from the sender-controlled message. And they can give us this entry as well. And if they can force our application to go down some unexpected path where it doesn't also tack on this other entry, then when it gets time to use this message, we have no idea whether it came from the remote sender or if it was generated locally. So we have to assume that we can't trust it.
Let's take a look at an example of this. We've added the ability to react to someone's live tea-brewing session, and you can even attach an image of your reaction to show them what you think.
So it looks like we created this Reaction object from the JSON data.
And if there was some image data attached, we write it to a local file URL during the message processing and then set that as the imageURL on the reaction object.
We then pass it to our ViewController to display it. So let's take a look at what happens there.
If the imageURL is non-nil, we'll display it...
then remove the image we wrote to disk once it's finished displaying. But because we're taking the imageURL off of the same object that's created with the untrusted data, we've given an attacker the ability to delete arbitrary files that are accessible from our application's container.
Because what will happen if someone sends us this message with the imageURL already set in it is we'll skip over this block of code because the image data wasn't set and go straight to displaying it here. But because the imageURL was set, we'll try and show whatever is at the file path, but actually we'll end up deleting whatever file was specified in the JSON.
So what have we learned from that? You want to separate trusted and untrusted data into completely different objects. Don't try and combine them into a single object, because what you'll be doing is introducing ambiguity between trusted and untrusted parameters. We always want it to be very clear what's untrusted so that we can audit our use of the untrusted data and make sure it's always validated and sanitized before we use it. Now I'll hand it back over to Coops to talk about NSCoding. Thanks, Ryan. NSCoding, and its more modern NSSecureCoding companion, have been around for a long time and provide the valuable capability to serialize and deserialize complex graphs of objects.
It's the kind of thing we might use for storing parsed data into our local cache, or for a custom document format. We're going to cover some of the mistakes which we see and which are particularly dangerous if the archive comes from untrusted data.
To start, please stop using NSUnarchiver. It's been deprecated for ages and isn't suitable for data coming from an untrusted source.
What you want to be using is NSKeyedUnarchiver.
Much like NSUnarchiver, it allows you to pack and unpack graphs of objects, but it has the ability to be used securely.
NSKeyedUnarchiver has also been around for a while, so there are deprecated ways of using it. Many of you may be using it in these ways, unaware that you're leaving your software and your users exposed to attack. The top set of methods here are the ones you should be using. The bottom ones are all legacy, and if you're still using, you should migrate away from as soon as possible.
The naming of the two sets is very close, but all the deprecated ones are named "with" rather than "from." The reason we deprecated these methods is that they're incompatible with secure coding. You might not fully understand what secure coding is, so let's look at the problem it solves.
Without secure coding, when you take an archive and call unarchiveObjectWithData, it unpacks an object graph for you.
In this example, we're expecting to get back an array of strings.
The problem here is that the types of objects created are specified inside the archive. If that comes from an untrusted source or can be modified by an attacker, any NSCoding-compliant object can be returned.
What this means is an attacker might modify the archive and cause us to unpack a completely unexpected class, like WKWebView.
Although this object might not conform to the interface we expect, and you may even perform a type check, a security issue still remains, as any bugs reachable by an attacker during the un-archiving of the class will have triggered already. Secure coding resolves these issues by restricting the compatible classes to those which implement the secure coding protocol and requires that you specify the classes you expect at each call site.
This information is used inside the KeyedUnarchiver to perform validation before the decoding is even attempted.
Doing this drastically reduces the number of classes which can be leveraged by an attacker and thus reduces the attack surface.
But even with this, there are a number of common mistakes we see. Let's take a look at some.
In this simple example, we're using secure coding to retrieve an array of objects.
The issue here is that we've specified NSObject in the allowedClasses set.
Secure coding will decode objects which conform to its protocol and are either in the allowedClasses set or a subclass of one specified. As all objects derive from NSObject, this allows any secure coded object to be decoded, undermining the attack surface reduction which secure coding gave us. This is a simple example which is easy to spot, but we also see this happening in more complex cases, where class lists get passed through multiple layers of framework and end up being supplied to a KeyedUnarchiver method.
Another similar pattern is this. A string is decoded from the archive. That string is then used to look up a class via NSClassFromString, the resulting class used as the allowedClass for the extraction of an object.
Hopefully the issue here is obvious to people.
Both the className and thus the resulting allowedClass are under attacker control.
As such, they can easily pass the name of a specific class or even NSObject and bypass the benefits of secure coding. So how do we solve these problems? If possible, simply use a restricted, static set of classes, making sure to avoid classes which are the base for large hierarchies to reduce the number of classes available to an attacker. What about the case where you do want to support dynamic classes? One of the most common places we see this is where support for plug-ins is required.
In this case, we recommend creating the allowedClass list dynamically, but from trusted data. The easiest way to do this is where your plug-in supports a protocol. Thus you can simply enumerate all the classes that the runtime knows about and create a set of those which conform to the protocol.
This can then be safely used with secure decoding, as the class list is outside the attacker's control. To summarize, migrate your code away from all the deprecated methods and classes, avoid using NSObject or overly generic base classes, and use a static allowedClass list wherever possible.
And when you can't, generate it from trusted data.
Another good alternative is to avoid it completely and use things like Swift Codable or a less flexible encoding format like plist, JSON or protobuf.
You can act on this information right away by searching your codebase for use of these items in areas which deal with untrusted data. Another problem which plagues high-risk code is memory corruption.
Whenever using Objective-C or Swift's UnsafePointer, it's possible to introduce memory safety issues. These are particularly prevalent when parsing untrusted data, be it from a buffer, a string, or out of a structured archive.
Let's take a look at some examples.
As we've talked about already, security issues arise when untrusted data is mistaken for trusted data.
In this example, we're unpacking the CloudKit record for a private tea club. The first thing we do is copy the bytes of the UUID into an iVar.
If we take a look at each element, we can see that the CKRecord is trusted, as it's generated by CloudKit. But the data fields retrieved from it are under attacker control. So we can't trust that they contain a fixed amount of data.
The problem here is that the length of the data is under attackers' control, but the size of the UUID iVar is fixed.
As such, if the supplied NSData contains more than the UUID can hold, attacker-controlled data will be written out of bounds.
To see why this can be a problem, we need to look at what will happen.
In the object which contains the UUID, we can see that the next iVar is the path to the local cache. Now, this field isn't set from the CloudKit record. Thus, overflowing the UUID allows an attacker to gain control of a field they shouldn't have the ability to.
The memcpy will cause attacker-controlled data to be written into UUID as intended, but as the size is too great, it will overflow into localCachePath.
With this, they can reconfigure the cache for the group, causing files to be downloaded and overwriting the users' local preferences.
Using various techniques, attackers can use these kind of bugs to get code execution inside your application, which gives them access to all your users' data and access to all the resources that were granted to you.
The obvious fix for this would be to use sizeof(_uuid), but this exposes a different problem, as, if the attacker supplies less data than expected, the memcpy will read off the end of "data," causing other user secrets in memory to be disclosed into the UUID field.
When the app syncs that information back to the server, it will encode that user data and return it to the attacker.
The correct fix is to validate that the object we retrieved is an NSData and check its length is an exact match. This prevents both the overwrite of the destination and the overread of the source.
Whilst this is a simple example, extra care should always be taken when parsing untrusted data, particularly where the format is complex or nested.
Always validate lengths, as even casting a C structure onto a buffer will disclose user information if there is insufficient data.
Another case where we need to be careful is when dealing with integers, as these have a habit of overflowing.
In this example, further down the same method, we extract an NSData with UNICHAR characters and a count from a separate field. As before, we should look at which data is trusted.
In this case, both name and count are untrusted, as they've come from attacker-controlled data.
Now, the developer has foreseen the danger of blindly trusting the count, and so validates it against the length of the data. But there's a problem. The attacker actually controls both sides of this comparison, and there exists a set of values where the assumptions the developer made are no longer correct.
In this case, if an attacker passes a zero-length string for "name" and 80 million hex for nameCount, the integer will overflow and the "if" statement will fail.
This will result in a very large read off the end of "name," potentially disclosing user data. The fix is to add a comprehensive validation check, checking the type and the length.
But most importantly, use of the os_overflow method to perform the arithmetic.
In this case, we've used os_mul_overflow. For those which don't know about them, os_overflow is a really useful set of functions which allow safe handling of numbers and robust detection of under- and overflow conditions. Use is simple. Just replace your arithmetic operation with the relevant os_overflow method. We've provided ones for add, subtract and multiplication, using both two and three parameters.
On overflow, they return non-zero. Using these makes it easy to ensure that calculations using attacker-controlled values can be performed safely.
So to summarize, always validate length and consider all cases. Too big, too small, it should be just right.
When working with numbers, be wary of arithmetic, as if you're not using os_overflow functions, there's a high risk you'll make a mistake.
Finally, seriously consider using Swift for these high-risk code paths, though remember to avoid the use of UnsafePointer and other raw memory manipulation features. In closing, hopefully this talk has given you some ideas of how to think about security and some examples of common pitfalls to try and avoid. Security is a huge topic, and it's hard, because as we've seen, the smallest error can be enough to compromise your entire application.
But by understanding where the risk is, designing to mitigate it and taking care when handling untrusted data, we can massively reduce the chances of things going wrong. Thanks for coming.
-
-
16:34 - Path traversal
func handleIncomingFile(_ incomingResourceURL: URL, with name: String, from fromID: String) { guard case let safeFileName = name.lastPathComponent, safeFileName.count > 0, safeFileName != "..", safeFileName != "." else { return } let destinationFileURL = URL(fileURLWithPath: NSTemporaryDirectory()) .appendingPathComponent(safeFileName) // Copy the file into a temporary directory try! FileManager.default.copyItem(at: incomingResourceURL, to: destinationFileURL) } -
22:26 - State management
func handleSessionInviteAccepted(with message: RemoteMessage, from fromID: String) { guard session = sessionsByIdentifier[message.sessionIdentifier], session.state == .inviting, session.invitedFromIdentifiers.contains(fromID) else { return } session.state = .connected session.setupSocket(to: fromID) { socket in cameraController.send(to: socket) } } -
30:56 - Safe dynamic allowedClasses
NSSet *classesWhichConformToProtocol(Protocol *protocol) { NSMutableSet *conformingClasses = [NSMutableSet set]; unsigned int classesCount = 0; Class *classes = objc_copyClassList(&classesCount); if (classes != NULL) { for (unsigned int i = 0; i < classesCount; i++) { if (class_conformsToProtocol(classes[i], protocol)) { [conformingClasses addObject: classes[i]]; } } free(classes); } return conformingClasses; } -
34:23 - Buffer overflows
@implementation - (BOOL)unpackTeaClubRecord:(CKRecord *)record { ... NSData *data = [record objectForKey:@"uuid"]; if (data == nil || ![data isKindOfClass:[NSData class]] || data.length != sizeof(_uuid)) { return NO; } memcpy(&_uuid, data.bytes, data.length); ... -
36:06 - Integer overflows
@implementation - (BOOL)unpackTeaClubRecord:(CKRecord *)record { ... NSData *name = [record objectForKey:@"name"]; int32_t count = [[record objectForKey:@"nameCount"] unsignedIntegerValue]; int32_t byteCount = 0; if (name == nil || ![name isKindOfClass:[NSData class]] || os_mul_overflow(count, sizeof(unichar), &byteCount) || name.length != byteCount) { return NO; } _name = [[NSString alloc] initWithCharacters:name.bytes length:count]; ...
-