-
Control training in Create ML with Swift
With the Create ML framework you have more power than ever to easily develop models and automate workflows. We'll show you how to explore and interact with your machine learning models while you train them, helping you get a better model quickly. Discover how training control in Create ML can customize your training workflow with checkpointing APIs to pause, save, resume, and extend your training process. And find out how you can monitor your progress programmatically using Combine APIs.
If you're not already familiar with Create ML and curious about training machine learning models, be sure to watch “Introducing the Create ML App.”Resources
Related Videos
WWDC21
WWDC20
WWDC19
-
Search this video…
Hello and welcome to WWDC.
Hello. My name is Lizi, and I'm a machine learning manager on the Create ML team. Today I'm thrilled to introduce a set of new APIs for checkpointing and asynchronous training in Create ML. To make sure we're all on the same page, let's talk about the Create ML app and the Create ML framework. The Create ML app is great. If you want to easily create models without a single line of code, I encourage you to start there.
Under the hood, the app is powered by a rich and easy-to-use API: the Create ML framework. For macOS Big Sur, we're bringing you a set of powerful and flexible APIs for controlling your training workflow. These will enable you to customize the way you create machine learning models and leverage all the same technology that powers the app. With that, let's start by reviewing the training process.
If you want to train a model, the first thing you have to do is collect some data.
You also want to look at all the training options available to you. If you are using Create ML, you can always accept the default parameter settings, but it doesn't hurt to understand what the options mean.
Next, preprocessing. Some tasks require extracting features or transforming data into the right structure. For example, raw audio may be transformed by taking its spectrogram or video may have keypoints extracted from every frame.
Then, training. This is the fun part. And we'll spend some time looking at this in depth, so let's leave it at that for now.
Next, we evaluate the model by presenting it with new data. Here, it's important to use a different set of data that the model hasn't seen during training. This will help you determine if your model is generalizing instead of memorizing training examples. At this point, you may realize that your model is not quite what you expect. Maybe it needs more data. Maybe it needs a different set of training parameters. Or maybe it just needs to train a bit longer. Model development is an iterative process, so you can return to setup or train until your model meets your needs.
Once you are satisfied, you can use your trained model to perform predictions. At this point, you're ready to deploy. With the training process in mind, let's talk about control. Training control is mainly having the ability to pause and resume, but also the ability to observe and alter the training process while it's happening.
And you can stop training at any point.
Why is this important? Training a machine learning model takes time. In particular, training an object detection model can take five hours. Imagine you were training and after several hours, training stops because it reached the maximum number of iterations.
But then you realize that the loss was still decreasing, and there was still room to converge to a better model. Without training control, you would have to start from scratch and choose a larger number of maximum iterations. But now you can continue from where training stopped.
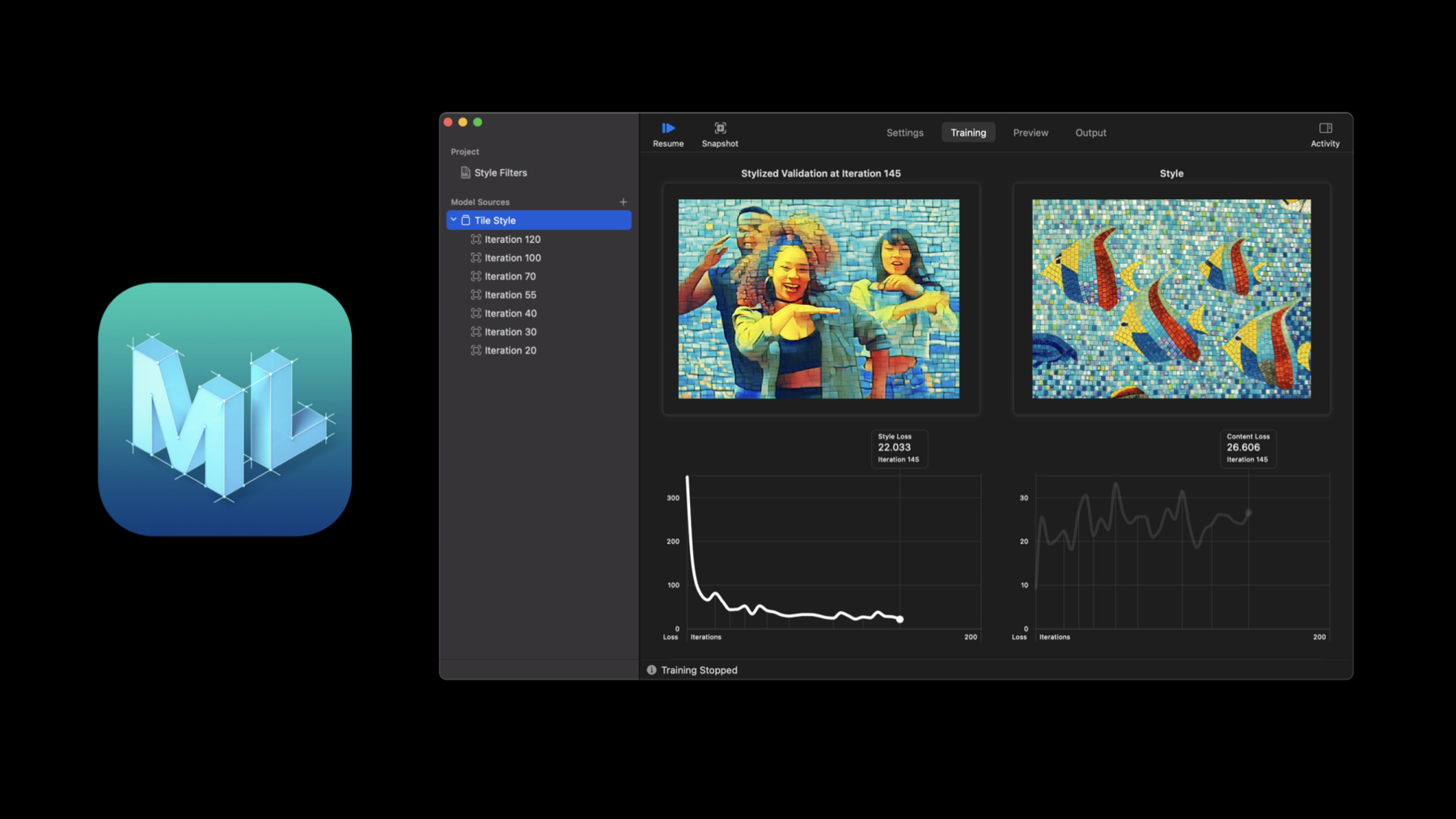
Another reason this is important is results are specific to what you are trying to achieve. Using a built-in mechanism to evaluate the model will not necessarily give the best results for your specific use-case. This is particularly true in Style Transfer where the quality of a model is subjective. For instance, here, the model is applying the fish mosaic style to the photo of the dancers. It's up to you to decide when this is good enough and stop training. Also, choosing when to stop is specific to your needs. Maybe you need a model for a prototype and don't want to spend too much time on it. Or maybe this is an important model and you are willing to spend extra time training to achieve the best result possible. Using training control, you can define custom stopping criteria, meaning you are not limited to the number of iterations. You may have a target accuracy for an image classifier, or you may have a specific amount of time you can allow for training.
Training control is available in the Create ML app. But with the API, you can customize this behavior to your needs. Let me show you.
Before, you would call a model constructor, time would stop, and a trained model would be returned.
With the new asynchronous API, you can now call the train method which returns a job.
The train method takes the usual training parameters as well as a sessionParameters argument which lets you specify the cadence of reports and total number of iterations. You can always omit the arguments to use the defaults.
The first argument to sessionParameters is the sessionDirectory. This directory will be created if it doesn't already exist. In subsequent invocations, the contents of the directory will be used to resume a previous session. If you want to start a new session, simply delete the directory or choose a new location.
The next two arguments control the cadence of progress reports and checkpoints. Smaller intervals will give more frequent updates, but may come at a performance cost.
The last argument is the total number of iterations. Training will stop at this iteration number. But don't worry, you can always increase this number in subsequent calls to train, and you can always stop before this number of iterations is reached.
The job returned from train is an instance of MLJob which represents an active training job. It contains a progress publisher, a checkpoint publisher and a result publisher.
These leverage the Combine framework, which you can learn more about in "Introducing Combine" and "Combine in Practice" from WWDC19.
MLJob also provides a cancel method so you can stop training easily at any point. To give you an idea, here is how you would use the result publisher to get a trained model. First, you register a sink on the result publisher. Its first closure is invoked on completion and receives a success or failure result. It also receives an error in the failure case, so you should handle errors here.
The second closure receives the final model when training is complete.
Finally, you store the subscription until you are done with it.
You can observe progress such as the fraction completed, the current training iteration, total number of iterations, and custom metrics such as the current loss or accuracy value.
For example, you can observe and print progress by accessing the progress publisher on MLJob. Note that this is the standard instance of Progress from Foundation. To access custom metrics, we first register a sink closure. As a precaution, we capture the job weakly to avoid retain cycles.
Next, we ensure the job still exists and create an instance of MLProgress. The MLProgress helper type allows us to access custom metrics from an instance of Foundation Progress. Note that there may be cases where an instance of MLProgress cannot be initialized yet, such as when a new session is just created or a new phase is starting. We handle that by returning early.
Then we can access all progress information like the current item and total number of items. In feature extraction, the item refers to the current file or record being processed. For training, it refers to the current iteration number. And finally, we can get training metrics. Metrics are only available in the training phase, and are specific to each task. Some tasks have accuracy while others have loss or other metrics. If you provided validation data, you may also be able to access validation metrics. Now let's take a look at how you can train a model using the new asynchronous APIs.
I've been really interested in training a few Style Transfer models after watching "Build Image and Video Style Transfer Models in Create ML," so I've started setting up my model creation workflow in Playgrounds. Here, I have a few different styles images I can use in my resource bundle and I also have some validation images of different artists that I'd like to stylize.
Back in my Playground, I first specified URLs to the style image and validation image that I want to use.
One nice thing about Playgrounds is it allows me to visualize my data inline as I go. For example, I can see the style that I've designated and validation image that we'll use.
The next thing I'll do is specify a dataSource to define our training data and I'll pass list the styleImageURL and contentDirectory and then proceed to initialize parameters we need to set up our session.
I'll first initialize MLTrainingSessionParameters that takes a sessionDirectory. I can also provide a reportInterval to specify the number of iterations between progress reports, a checkpointInterval to specify the number of iterations between checkpoints, and iterations to extend training.
Next, I'll set up my model parameters.
Now we're ready to begin training.
To start the training process, I'll call the train method on the type of model I want to create.
Here, I'll provide my dataSource, trainingParameters...
and sessionParameters.
This returns an instance of MLJob.
MLJob contains a results publisher. We can use the results publisher to receive errors that occur during training and access the model once we're done.
I can also use the job to control and observe training while it's happening. For example, if I want to access progress programmatically, I can do so by using the progress publisher. And since this is an instance of Foundation Progress, I'm going to specify that we want the fractionCompleted by providing a key path to that property.
Next, I'll call sink which will return a cancellable that we can later use to terminate the subscription. Beyond the fractionCompleted, I can also access metrics specific to the ML model I am trying to train. To do this, I'll initialize an instance of MLProgress from the instance of Foundation Progress. I can then access specific metrics such as the style loss and content loss across iterations. And with the power of Xcode Playgrounds, when I hit "train," I can visualize progress as it's happening.
And in Playgrounds, I can view this as the latest value or a graph as it trains across iterations. Pretty cool.
New this release is also the ability to control the training process with pausing, resuming and extending. To stop, all I need to do is call cancel on the job.
To resume, it's as simple as calling train with the same session directory as I used before.
It's almost automatic. Now that you've seen how to train a model using the new asynchronous APIs, I want to introduce checkpoints. With checkpoints, you can capture the state of your model over time. You can use them to see how training progressed and easily compare against previous results. Also, if you decide that a checkpoint needs a bit more training, you can use it to resume where you left off.
MLCheckpoint is the struct that represents either a training or feature extraction checkpoint.
Unlike in other frameworks, MLCheckpoints are created automatically when using the new asynchronous APIs, and they're easy to resume from. All you need to do is provide a sessionDirectory where you are starting a new session or continuing an existing one. This is great in environments such as Playgrounds so you can iterate without losing progress.
Let's go back to the training process for a moment. I want to zoom into two of these phases: preprocessing and training. These are the two phases where checkpoints are generated.
Let's start with preprocessing.
In this phase, we take data elements, such as individual files or rows in a table, and process each one of them. Progress is measured by how many of these elements have been processed.
Every few elements, we store the current progress as a checkpoint. We only keep the last preprocessing checkpoint since this phase is strictly additive.
The training phase is also an iterative process. The model improves in discrete steps called iterations. An iteration consists of running a batch of data through the network, computing the loss and updating the weights.
A training checkpoint is the state of the model at a particular iteration. Unlike preprocessing, training preserves all checkpoints you create. As training progresses, we also get metrics such as loss or accuracy. These metrics are stored along with the checkpoints to help you identify them.
Let's look at some code. Here is an example of how you would use the checkpoints publisher. All checkpoints are automatically saved to the session folder. But this publisher gives you a chance of generating custom metrics, generating a model, or stopping training altogether. It's a chance for you to act on new checkpoints as they are created.
For instance, this is how you can generate a model from a checkpoint. Once you have a model, you can save it to disk or use it to make predictions.
Note that you can only create a model from training checkpoints, not feature extraction checkpoints, so you should check its training phase.
You can make checkpoints during the feature extraction phase for image classification, sound classification and action classification. Training checkpoints are available for action classification, object detection, Style Transfer and activity classification. Now let's talk about sessions. Think of a session as the aggregate of all checkpoints and their metadata. This is represented by the MLTrainingSession type. It lets you query details like when the session was created, the current training phase, and the current iteration number.
If you want to access the session directly, you can use the restoreTrainingSession method on a model type.
From that, you can do things like access the loss values. You can also remove checkpoints that you don't need anymore, freeing up disk space. Now let's take a look at checkpoints in action.
We already saw how you could observe progress and results from an instance of MLJob while training a Style Transfer model in Playgrounds. Back in our same Playground, we can see that MLJob contains a checkpoints publisher that we can use to observe checkpoints over time. For Style Transfer, I can access the stylized validation image on each checkpoint to help us visualize how our model is progressing as it trains.
To do this, I can use compactMap to transform the checkpoint into a form we need and then map the image URLs into NSImages.
I'm then going to call sink to attach a subscriber to the checkpoints publisher and store the AnyCancellable return type to our subscriptions list.
And now we can see our stylized validation image over time as the model trains, directly inline. But wouldn't it be great if we could take things even further? Well, now, using SwiftUI, we can easily render more in the Xcode Playgrounds Live View.
The first thing I'll do is to find a new view object and pass it images of our style image, stylized validation image and original validation so we can compare how our model is performing over time. And since we're using UI, I'll receive this on the main queue and then I'll set the Playground Live View so we can populate the results there.
And the Live View comes to life! Now we can visualize our model as it trains along with our reference style and the validation image, thanks to the new checkpointing and asynchronous training APIs.
Let's recap what we saw in this session. We learned how to train a model using the new asynchronous APIs available in Create ML. We learned about checkpoints and how to use them to generate models and resume training. And lastly, we saw how to use Combine publishers to get progress reports and handle results. So where do you go from here? I encourage you to leverage these new tools if you need to customize your training workflow. Training control allows you to control not just your model quality, but the entire training process, whether you are developing models, automating workflows or creating models on demand in your macOS apps. Thank you, and enjoy the rest of WWDC.
-
-
4:39 - Synchronous training
let model = try MLActivityClassifier(...) -
4:47 - Asynchronous Training
let job = try MLActivityClassifier.train(..., sessionParameters: sessionParameters) -
4:58 - Setting up training parameters
// Session parameters can be provided to `train` method. let sessionParameters = MLTrainingSessionParameters( sessionDirectory: sessionDirectory, reportInterval: 10, checkpointInterval: 100, iterations: 1000 ) let job = try MLActivityClassifier.train(..., sessionParameters: sessionParameters) -
6:21 - Register a sink to receive model
// Register a sink to receive the resulting model. job.result.sink { result in // Handle errors } receiveValue: { model in // Use model } .store(in: &subscriptions) -
7:07 - Getting training progress
// Observing progress details job.progress.publisher(for: \.fractionCompleted) .sink { [weak job] fractionCompleted in guard let job = job, let progress = MLProgress(progress: job.progress) else { return } print("Progress: \(fractionCompleted)") print("Iteration: \(progress.itemCount) of \(progress.totalItemCount ?? 0)") print("Accuracy: \(progress.metrics[.accuracy] ?? 0.0)") } .store(in: &subscriptions) -
8:55 - Demo 1: Setup
let style = NSImage(byReferencing: styleImageURL) let validation = NSImage(byReferencing: validationImageURL) var iterations = 500 var progressInterval = 5 var checkpointInterval = 5 let sessionDirectory = URL(fileURLWithPath: "\(NSHomeDirectory())/\(experimentID)") let sessionParameters = MLTrainingSessionParameters(sessionDirectory: sessionDirectory, reportInterval: progressInterval, checkpointInterval: checkpointInterval, iterations: iterations) let trainingParameters = MLStyleTransfer.ModelParameters( algorithm: .cnn, validation: .content(validationImageURL), maxIterations: iterations, textelDensity: 416, styleStrength: 5) -
10:03 - Demo 1: Training
var subscriptions = [AnyCancellable]() let job = try MLStyleTransfer.train(trainingData: dataSource, parameters: trainingParameters, sessionParameters: sessionParameters) job.result.sink { result in print(result) } receiveValue: { model in try? model.write(to: sessionDirectory) } .store(in: &subscriptions) -
10:51 - Demo 1: Progress
job.progress .publisher(for: \.fractionCompleted) .sink { completed in _ = completed guard let progress = MLProgress(progress: job.progress) else { return } if let styleLoss = progress.metrics[.styleLoss] { _ = styleLoss } if let contentLoss = progress.metrics[.contentLoss] { _ = contentLoss } } .store(in: &subscriptions) -
12:04 - Demo 1: Cancel & Resume
job.cancel() let resumedJob = try MLStyleTransfer.train( trainingData: dataSource, parameters: trainingParameters, sessionParameters: sessionParameters) resumedJob.progress .publisher(for: \.fractionCompleted) .sink { completed in _ = completed guard let progress = MLProgress(progress: resumedJob.progress) else { return } if let styleLoss = progress.metrics[.styleLoss] { _ = styleLoss } if let contentLoss = progress.metrics[.contentLoss] { _ = contentLoss } } .store(in: &subscriptions) resumedJob.result.sink { result in print(result) } receiveValue: { model in try? model.write(to: sessionDirectory) } .store(in: &subscriptions) -
14:26 - Observing checkpoints
let job = try MLActivityClassifier.train(..., sessionParameters: sessionParameters) // Register for receiving checkpoints. job.checkpoints.sink { checkpoint in // Process checkpoint } .store(in: &subscriptions) -
14:50 - Generating a model from a checkpoint
// Generate a model from a checkpoint guard checkpoint.phase == .training else { // Not a training checkpoint, can't create model yet. return } let model = try MLActivityClassifier(checkpoint: checkpoint) try model.write(to: url) -
15:40 - Working with a session
let session = MLObjectDetector.restoreTrainingSession(sessionParameters: sessionParameters) let losses = session.checkpoints.compactMap { $0.metrics[.loss] as? Double } -
15:48 - Removing checkpoints from a session
let session = MLObjectDetector.restoreTrainingSession(sessionParameters: sessionParameters) // Save space by removing some checkpoints session.removeCheckpoints { $0.iteration < 500 } -
16:13 - Demo 2: Visualizing Style Transfer Checkpoints
job.checkpoints .compactMap { $0.metrics[.stylizedImageURL] as? URL } .map { NSImage(byReferencing: $0) } .sink { image in let _ = image } .store(in: &subscriptions) -
16:24 - Demo 2: Visualizing Checkpoints with SwiftUI + Live View
job.checkpoints .compactMap { $0.metrics[.stylizedImageURL] as? URL } .receive(on: DispatchQueue.main) .map { NSImage(byReferencing: $0) } .sink { image in let _ = image let view = VStack { Image(nsImage: image) .resizable() .aspectRatio(contentMode: .fit) Image(nsImage: style) .resizable() .aspectRatio(contentMode: .fit) Image(nsImage: validation) .resizable() .aspectRatio(contentMode: .fit) }.frame(maxHeight: 1400) PlaygroundSupport.PlaygroundPage.current.setLiveView(view) } .store(in: &subscriptions)
-