Retired Document
Important: OpenCL was deprecated in macOS 10.14. To create high-performance code on GPUs, use the Metal framework instead. See Metal.
Memory Objects in OS X OpenCL
OpenCL uses memory in a different way than conventional programs do. This chapter introduces memory buffers and images as they are used by OpenCL applications. See Creating and Managing Image Objects In OpenCL and Creating and Managing Buffer Objects In OpenCL for specifics about managing image and buffer memory respectively.
See Using IOSurfaces With OpenCL for specifics about using IOSurfaces with OpenCL.
Overview
Like all computational processes, processes that run on OpenCL devices consist of:
-
Data
The data accessed by OpenCL instructions exists as
cl_imagememory objects and memory buffers. Use image objects for representing two- or three-dimensional images (see Creating and Managing Image Objects In OpenCL). Use buffer objects to contain other types of generic data (see Creating and Managing Buffer Objects In OpenCL). -
Instructions in an OpenCL program that manipulate data.
For many devices (such as GPUs), the OpenCL memory is housed in a physically distinct piece of silicon. For other devices , the device memory is physically on the same chip. Regardless of its physical location, device memory can only be read and written by the OpenCL kernel code and host memory can only be read and written by the host.
In other words, even if host and OpenCL memory are physically contiguous, host memory is distinct from OpenCL memory. Kernels can only access data in the memory of OpenCL devices. The host computer can read and write to device memory, but only to set it up and retrieve results. During computation, a device looks only in device memory, and the host stays out of its way.
When data has been passed to the kernel by the host, the data resides on the OpenCL device at the time of execution. A kernel cannot read or write to the host memory; it can only access data in the device’s own separate memory area.
Memory Visibility
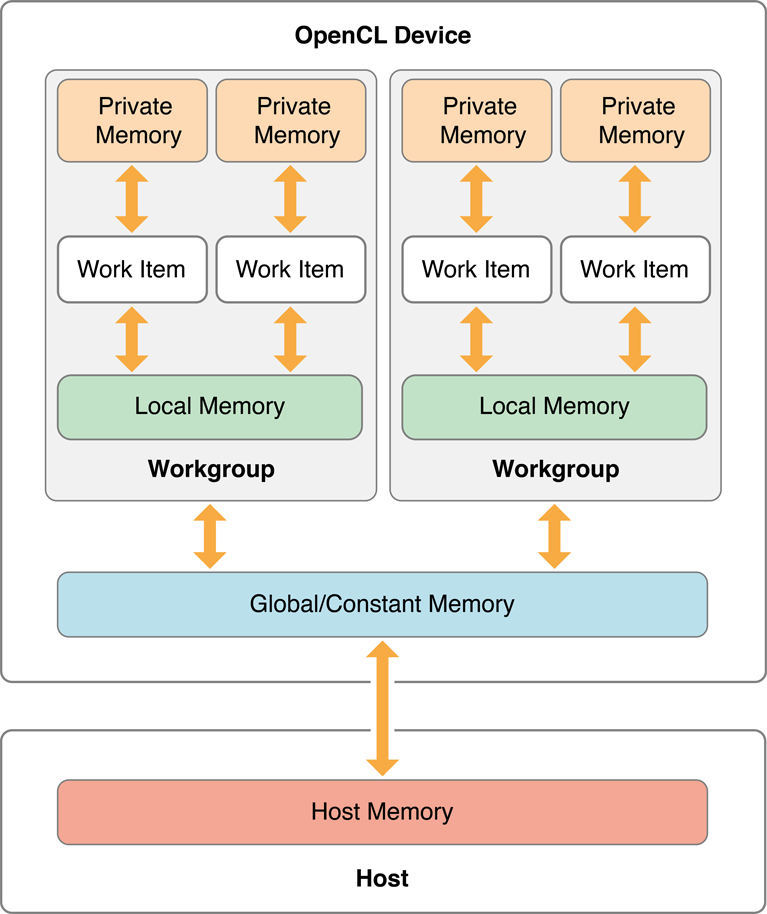
In a typical multi-device environment, memory is distributed between devices. No device can access all memory. Figure 7-1 illustrates the memory spaces in an OpenCL system. Each memory space has different visibility to the host and the kernel.
-
Private memory is memory that can only be accessed by one work item.
The host has no ability to read or write private memory, nor can other work items.
-
Local memory is memory that work items within a workgroup can share. Local memory is useful if more than one work item in a group needs to access a particular chunk of global memory. You can write your OpenCL program so that one work item loads data from global memory to local memory; the rest of the work items that need that piece of data can then access the local copy.
It takes GPU devices much less time to access local memory than to access global memory. The host has no ability to read or write local memory.
-
Global memory is the (relatively) massive chunk of device memory that all work items can "see". Any work item can read/write to a buffer declared to be in global memory.
The host can also read and write to global memory.
-
Constant memory is a specialized section of global memory used for data that you know will not change throughout the execution of your kernel. It is usually more limited in size than other types of global memory, but is faster to access on many devices than other global memory.
The host can read and write to constant memory.
For example, an OpenCL kernel executes on a separate memory space from the host that calls it. In order for the kernel to access the data it is to process, the data must be moved into the device’s memory. However, transferring data between memory areas to allow different devices to work can result in considerable overhead. To optimize performance, minimize the amount of data transferred.
The host specifies the memory space for a given buffer when it declares each kernel argument.
Memory Consistency
Changes a work item has made to global or local memory may not immediately become visible to other work items within a workgroup. A system’s consistency tells you when changes a work item has made to global or local memory become visible to other work items within a workgroup.
OpenCL uses what is called a relaxed memory consistency model, which means that:
-
Work items can access data within their own private, local, constant, and global memory spaces.
-
Work items can share local memory during the execution of a workgroup. However, memory is only guaranteed to be consistent after defined synchronization points.
If a work item needs to read something that another work item has written, call the barrier built-in function in your OpenCL kernel code at the point where you want the memory to be consistent:
barrier(CLK_LOCAL_MEM_FENCE);
barrier(CLK_GLOBAL_MEM_FENCE);
barrier(CLK_LOCAL_MEM_FENCE | CLK_GLOBAL_MEM_FENCE);
The barrier will stop any work item at the point where it calls the barrier until all other work items have "caught up". That's why it works: every work item in the workgroup has written its memory by the time it reaches the barrier, so you can safely read anything any work item in the group has written.
Memory Management Workflow
Figure 7-2 illustrates the basic memory management workflow in OpenCL.
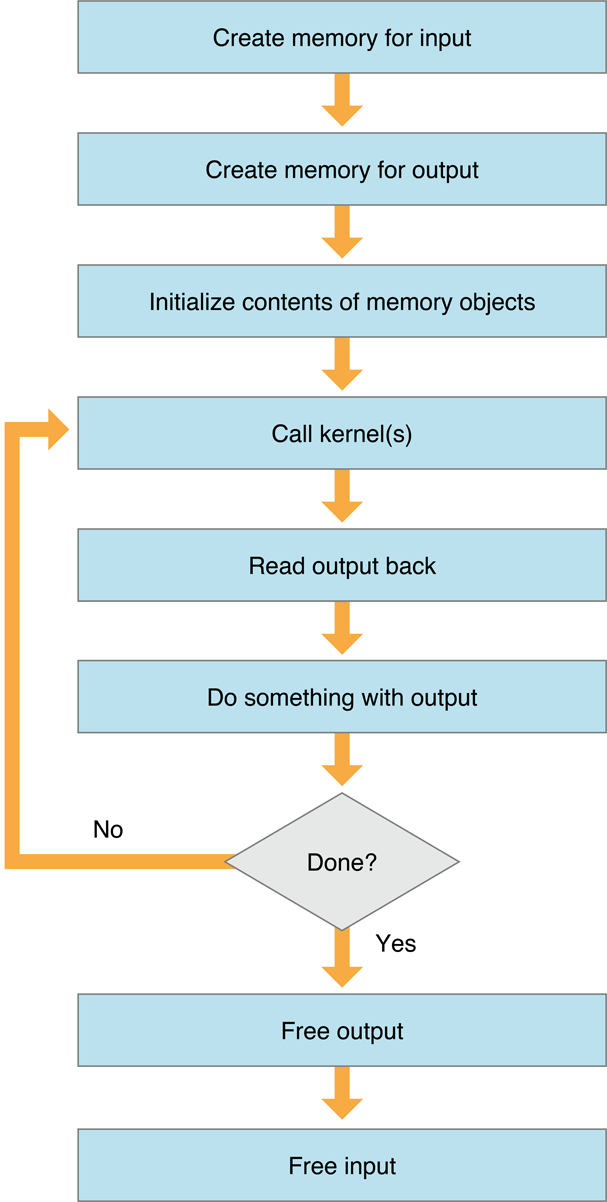
The basic memory workflow with OpenCL is:
-
The host creates memory objects for use by OpenCL.
The host requests that memory be set aside for it on the device. The host can ask for as many memory objects as it wants and gets them as long as there is memory available. You can create separate memory objects for input and output, but that is not a requirement. A single buffer object could be used for both input and output, provided this makes sense for your algorithm. Images, however, are more restricted. An image can be used for either input or output in a kernel, but not both at once.
-
The host initializes the contents of the memory objects.
The host can pass data to the device to be stored in its memory objects. This is data that can be processed by the kernel. The host can also instruct the device to leave some memory objects uninitialized so that when the kernel runs on the device, it can fill these memory objects with output.
The host instructs the device to execute the kernel, passing it the memory objects it has created on the OpenCL device as arguments. The host does not wait while the kernel works, but continues doing other work.
-
The kernel runs on the device, processing data, producing output.
-
The host reads results from the memory objects.
When the host detects that the kernel has completed its tasks, it copies the results from kernel memory into memory the host can access.
-
The host destroys the memory objects.
Once all kernels that need the memory objects have been run, the host instructs the device to free up the memory it had set aside for the kernel to use. For example, in a scenario where one buffer is used for input to many kernels, each of which runs many times, the host code frees the memory when every kernel execution that needed that memory object has been enqueued. You can specify a finalizer for objects. The finalizer will be called by the garbage collector when it destroys the object. See Setting the finalizer.
Setting the finalizer
You can specify a finalizer, a function member of a reference class that is called automatically by the garbage collector when destroying an object. To specify the finalizer which OpenCL will invoke when the memory specified by the object parameter is to be deallocated, call:
void gcl_set_finalizer(void *object, |
void (*gcl_pfn_finalizer)(void *object, void *user_data), |
void *user_data); |
|
Parameter |
Description |
|---|---|
|
|
The buffer or image memory object to which the finalizer is to be attached. |
|
|
Callback function that will be executed by the garbage collector when it is destroying the specified
|
| The |
|
|
|
Listing 7-1 is an example of how you would use the gcl_set_finalizer function.
Listing 7-1 Using gcl_set_finalizer
// This is the finalizer function you want OpenCL to call when the object is freed. |
void my_finalizer(void* memObj, // This is a pointer to the object whose |
// destruction triggered calling of this |
// finalizer. |
void* importantData // Pointer to data the finalizer will use. |
) |
{ |
// do something with memObj |
// do something with importantData |
} |
... |
void main() { |
// Do stuff ... |
void* my_mem_object = gcl_malloc(128, NULL, 0); // GCL memory object |
struct foo *special_data = |
(struct foo*)malloc(sizeof(struct foo)); // Some program-specific data |
// Specify your finalizer callback. |
gcl_set_finalizer(my_mem_object, // Call the finalizer function when |
// my_mem_object is about to be freed. |
my_finalizer, // In particular, call the my_finalizer function |
// when my_my_object is about to be freed. |
special_data // Pass this special_data to the my_finalizer |
// function before my_mem_object is freed. |
); |
// Do more stuff ... |
// ... |
// and then, at some point, free the my_mem_object. |
gcl_free(my_mem_object); // Before the my_mem_object object is actually freed, |
// OpenCL will call my_finalizer, and pass it |
// my_mem_object and special_data. |
} |
Parameters That Describe Images and Buffers in OS X OpenCL
Several functions that manipulate images and buffers in the OpenCL API accept origin, region, and row pitch parameters.
In Figure 7-3, the memory that contains the image is represented by the striped rectangle bounded by the width and the height, and includes the solid-colored region in its center. The region (represented by the solid pink rectangle bounded by the region width and region height), specifies the shape and size of the part of the image you want to manipulate. In other words, the region is just a certain amount of memory which lives at a given offset (or origin) into the image. The origin is the (x,y,z) position of the region within the image.
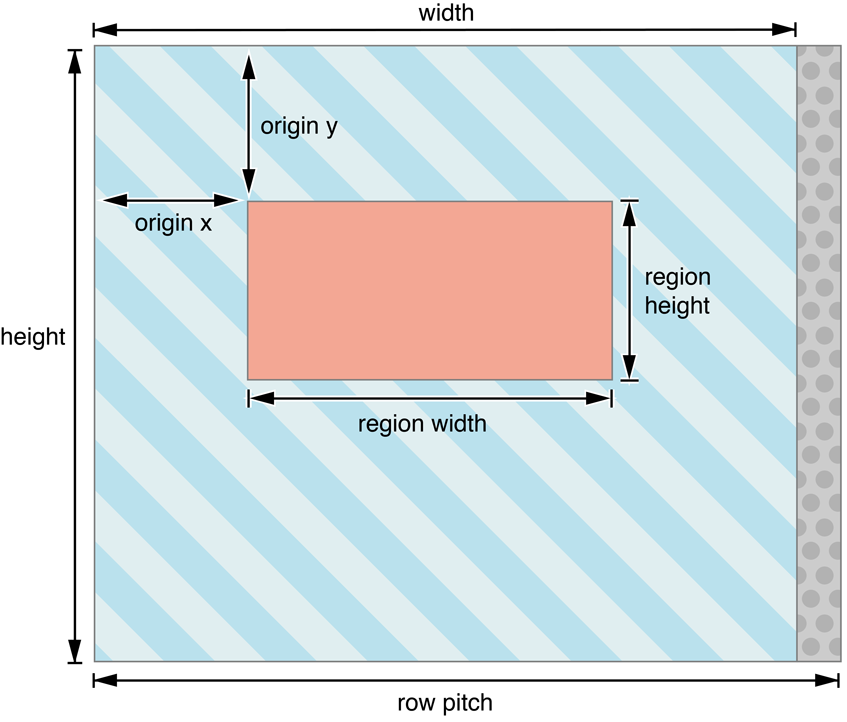
The row pitch is the width of the receiving area. The row pitch is the length in bytes in one row of the image. Usually, the row pitch is equal to the width in pixels of the image times the size of each pixel, in bytes. But sometimes, for performance reasons, it helps to use a bigger memory region to store the image than is strictly necessary. This is illustrated in Figure 7-3, where the row pitch is a bit larger than the image width. For example, if the image were 1000 pixels wide, and each pixel was 4 bytes, your row_pitch would be 4000 bytes. But it might be more efficient for the hardware to process 4096 bytes per row, in which case you could specify the row_pitch parameter as 4096.
The slice_pitch parameter used in some OpenCL multidimensional buffer manipulation functions such as gcl_memcpy_rect (see Creating and Managing Buffer Objects In OpenCL) is the size in bytes of a 2D slice that forms one layer of a 3D image. In other words, the slice pitch is the number of bytes in the row pitch multiplied by the number of bytes in the height of the image. Set the slice_pitch parameter to 0 if image is two-dimensional.
The slice pitch value must be greater than or equal to the row pitch multiplied by the height. If you specify the slice_pitch parameter as 0, OpenCL calculates the appropriate slice pitch to be the row pitch multiplied by the height.
Copyright © 2018 Apple Inc. All Rights Reserved. Terms of Use | Privacy Policy | Updated: 2018-06-04