Retired Document
Important: OpenCL was deprecated in macOS 10.14. To create high-performance code on GPUs, use the Metal framework instead. See Metal.
Creating and Managing Buffer Objects In OpenCL
The OpenCL programming interface provides buffer objects for representing generic data in your OpenCL programs. Instead of having to convert your data to the domain of a specific type of hardware, OpenCL enables you to transfer your data as-is to an OpenCL device via buffer objects and then operate on that data using the same language features that you are accustomed to in C.
Because transmitting data is costly, it is best to minimize reads and writes as much as possible. By packaging all of your host data into a buffer object that can remain on the device, you reduce the amount of data traffic necessary to process your data.
Allocating Memory For A Buffer Object In Device Memory
To create a buffer object in device memory call:
void * gcl_malloc(size_t bytes, void *host_ptr, cl_malloc_flags flags)
The gcl_malloc function is very similar to the C language malloc function. The gcl_malloc function returns an opaque pointer to a device memory buffer.
If insufficient memory exists on the device to satisfy the request, this function returns NULL.
Parameter | Description |
|---|---|
| The size in bytes of the allocation request. |
| Pointer to a host-side buffer which will be used to initialize the memory allocation if |
| Bitfield which consists of 0 or more memory flags discussed in Section 5.2.1 of the OpenCL 1.1 Specification. If you specify some combination of |
Converting a Handle To a cl_mem Object For Use With a Standard OpenCL API
If you are going to be using a standard OpenCL API call, you’ll need a cl_mem object. To create a cl_mem object, call the gcl_malloc function to allocate the memory, then call the gcl_create_buffer_from_ptr function to convert the handle gcl_malloc returns for use with the standard OpenCL API. Call:
cl_mem gcl_create_buffer_from_ptr(void *ptr)
This function is required only in cases where you will be using the standard OpenCL API alongside the gcl_ entry points. It returns a cl_mem object suitable for use with the standard OpenCL API.
It accepts a ptr parameter—a pointer created by the gcl_malloc function and returns a corresponding cl_mem object suitable for use with the standard OpenCL API.
The code will look something like this:
void* device_ptr = gcl_malloc(…); |
cl_mem device_mem = gcl_create_buffer_from_ptr(device_ptr); |
// Do stuff with device_ptr and device_mem. |
clReleaseMemObject(device_mem); |
gcl_free(device_ptr); |
Parameter | Description |
|---|---|
| A pointer returned by the |
Accessing Device Global Memory
To access the device global memory represented by a given pointer that was created by calling the gcl_malloc function, call:
void *gcl_map_ptr(void *ptr, cl_map_flags map_flags, size_t cb); |
The gcl_map_ptr function provides functionality similar to that of the OpenCL standard clEnqueueMapBuffer function. It returns a host-accessible pointer to the memory represented by a device memory pointer that is suitable for reading and writing. You can use this as an alternative to the various gcl_ copy functions to access the device global memory represented by a given pointer that was created by a call to the gcl_malloc function.
Parameter | Description |
|---|---|
| Pointer into the device memory which is to be mapped. This pointer is created by the |
| Bitfield specifying |
| Number of bytes of the buffer to map. (cb stands for 'count in bytes'). |
Copying Buffer Objects
When you allocate device memory using the gcl_malloc function, you need not create it on a device-specific dispatch queue. But when the time comes to actually use the memory, either for a kernel execution or a copy of some sort, OpenCL needs to know which device you intend to use.
Copying Data From Device or Host Memory To Host or Device Memory
To copy data from either device or host memory to either host or device memory, call:
void gcl_memcpy(void *dst, const void *src, size_t size); |
Parameter | Description |
|---|---|
| A pointer that points to the memory into which the bytes will be copied. It can either be a regular host pointer, or it can be a device memory pointer created by the |
| A pointer to the memory that is to be copied. As with the |
| The amount of memory in bytes to copy from |
| |
Performing a Generalized Buffer-To-Buffer Copy
To perform a generalized buffer-to-buffer copy which accommodates the case where the buffer data is conceptually multidimensional, call:
void gcl_memcpy_rect( |
void *dst, |
const void *src,
const size_t dst_origin[3],
const size_t src_origin[3],
const size_t region[3],
size_t dst_row_pitch,
size_t dst_slice_pitch,
size_t src_row_pitch,
size_t src_slice_pitch); |
This function provides functionality similar to that of the OpenCL standard clEnqueueCopyBufferRect function; it copies a one-, two-, or three-dimensional rectangular region from the src pointer to the dst pointer, using the respective origin parameters to determine the points at which to read and write. As shown in Figure 9-1, the region parameter specifies both the size and shape of the area to be copied.
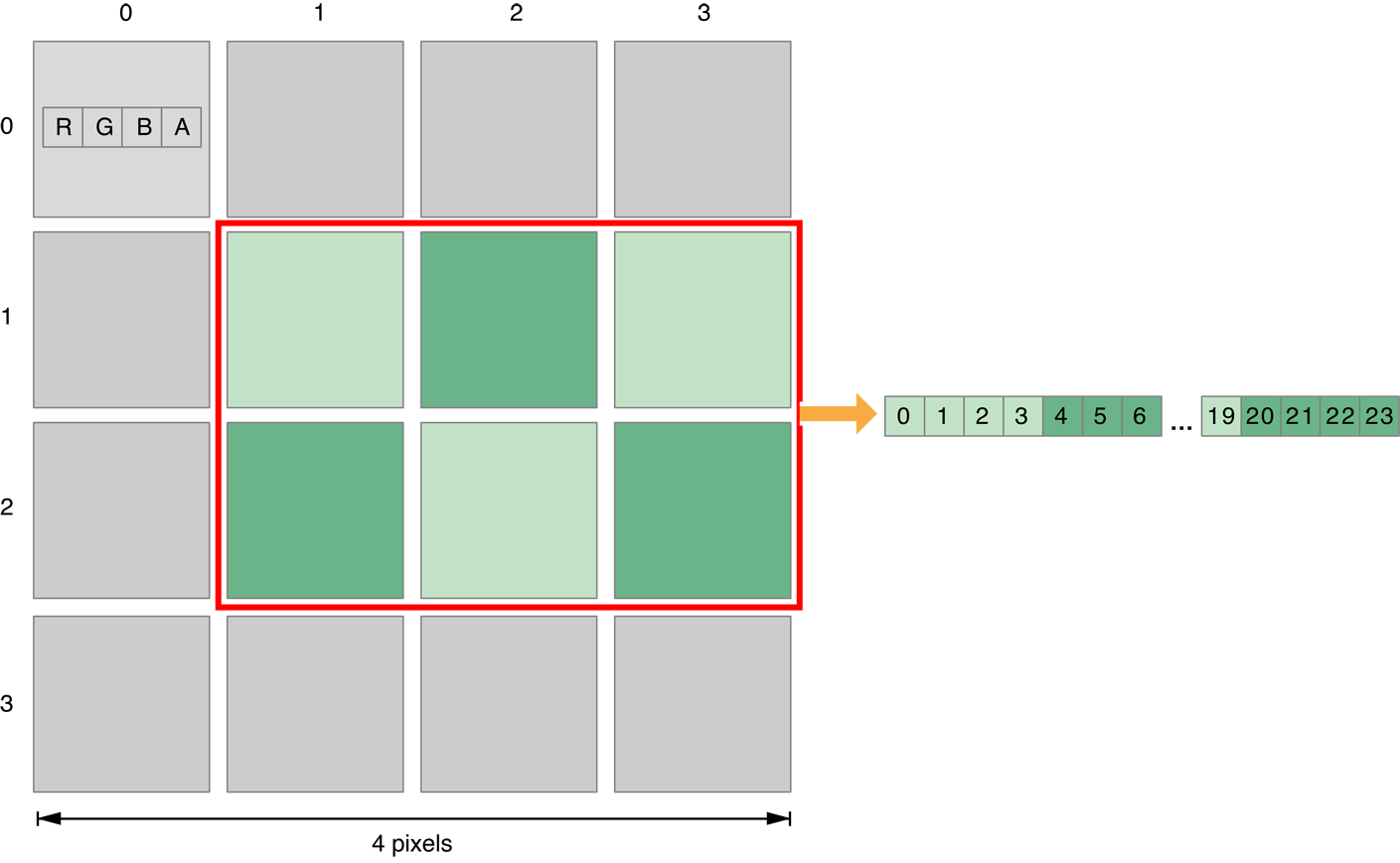
Since this is a buffer to buffer copy, all parameters are in bytes.
As with the OpenCL standard clEnqueueCopyBufferRect function, copying begins at the source offset (src_origin) and destination offset (dst_origin). Each byte of the region's width is copied from the source offset to the destination offset. After each width has been copied, the source and destination offsets are incremented by their respective source and destination row pitches.
After each two-dimensional rectangle is copied, the source and destination offsets are incremented by the source (src_slice_pitch) and destination (dst_slice_pitch) slice pitches respectively.
Parameter | Description |
|---|---|
| Pointer to the memory to which the bytes will be copied. It can be either a regular host pointer or a device memory pointer created by the |
| Pointer to the memory that is to be copied. As with the |
| Offset, in bytes, which specifies where in the destination buffer writing should start. It is calculated as:
|
| Offset, in bytes, which specifies where to begin reading in the source buffer. It is calculated as:
|
| The two- or three-dimensional region to copy. |
| The length of each row in bytes to be used for the memory region associated with |
| After each two-dimensional rectangle is copied, the source and destination offsets are incremented by the source ( |
| The length of each row in bytes to be used for the memory region associated with |
| After each two-dimensional rectangle is copied, the source and destination offsets are incremented by the source ( |
Releasing Buffer Objects
To avoid memory leaks, free buffer objects when they are no longer needed. Call the gcl_free function to free buffer objects created using the gcl_malloc function.
void gcl_free(void *ptr); |
Parameter | Description |
|---|---|
| Handle of the buffer object to be released. |
Example: Allocating, Using, and Releasing Buffer Objects
In the Listing 9-1, the host creates one input buffer and one output buffer, initializes the input buffer, calls the kernel (see Listing 9-2) to square each value in the input buffer, then checks the results.
Listing 9-1 Sample host function creates buffers then calls kernel function
#include <stdio.h> |
#include <stdlib.h> |
#include <OpenCL/opencl.h> |
// Include the automatically-generated header which provides the |
// kernel block declaration. |
#include "kernels.cl.h" |
#define COUNT 2048 |
static void display_device(cl_device_id device) |
{ |
char name_buf[128]; |
char vendor_buf[128]; |
clGetDeviceInfo( |
device, CL_DEVICE_NAME, sizeof(char)*128, name_buf, NULL); |
clGetDeviceInfo( |
device, CL_DEVICE_VENDOR, sizeof(char)*128, vendor_buf, NULL); |
fprintf(stdout, "Using OpenCL device: %s %s\n", vendor_buf, name_buf); |
} |
static void buffer_test(const dispatch_queue_t dq) |
{ |
unsigned int i; |
// We'll use a semaphore to synchronize the host and OpenCL device. |
dispatch_semaphore_t dsema = dispatch_semaphore_create(0); |
// Create some input data on the _host_ ... |
cl_float* host_input = (float*)malloc(sizeof(cl_float) * COUNT); |
// ... and fill it with some initial data. |
for (i=0; i<COUNT; i++) |
host_input[i] = (cl_float)i; |
// Let's use OpenCL to square this array of floats. |
// First, allocate some memory on our OpenCL device to hold the input. |
// We *could* write the output to the same buffer in this case, |
// but let's use a separate buffer. |
// Memory allocation 1: Create a buffer big enough to hold the input. |
// Notice that we use the flag 'CL_MEM_COPY_HOST_PTR' and pass the |
// host-side input data. This instructs OpenCL to initialize the |
// device-side memory region with the supplied host data. |
void* device_input = |
gcl_malloc(sizeof(cl_float)*COUNT, host_input, |
CL_MEM_COPY_HOST_PTR); |
// Memory allocation 2: Create a buffer to store the results |
// of our kernel computation. |
void* device_results = gcl_malloc(sizeof(cl_float)*COUNT, NULL, 0); |
// That's it -- we're ready to send the work to OpenCL. |
// Note that this will execute asynchronously with respect |
// to the host application. |
dispatch_async(dq, ^{ |
cl_ndrange range = { |
1, // We're using a 1-dimensional execution. |
{0}, // Start at the beginning of the range. |
{COUNT}, // Execute 'COUNT' work items. |
{0} // Let OpenCL decide how to divide work items |
// into workgroups. |
}; |
square_kernel( |
&range, (cl_float*) device_input, |
(cl_float*) device_results ); |
// The computation is done at this point, |
// but the results are still "on" the device. |
// If we want to examine the results on the host, |
// we need to copy them back to the host's memory space. |
// Let's reuse the host-side input buffer. |
gcl_memcpy(host_input, device_results, COUNT * sizeof(cl_float)); |
// Okay -- signal the dispatch semaphore so the host knows |
// it can continue. |
dispatch_semaphore_signal(dsema); |
}); |
// Here the host could do other, unrelated work while the OpenCL |
// device works on the kernel-based computation... |
// But now we wait for OpenCL to finish up. |
dispatch_semaphore_wait(dsema, DISPATCH_TIME_FOREVER); |
// Test our results: |
int results_ok = 1; |
for (i=0; i<COUNT; i++) |
{ |
cl_float truth = (cl_float)i * (cl_float)i; |
if (host_input[i] != truth) { |
fprintf(stdout, |
"Incorrect result @ index %d: Saw %1.4f, expected %1.4f\n\n", |
i, host_input[i], truth); |
results_ok = 0; |
break; |
} |
} |
if (results_ok) |
fprintf(stdout, "Buffer results OK!\n"); |
// Clean up device-side memory allocations: |
gcl_free(device_input); |
// Clean up host-side memory allocations: |
free(host_input); |
} |
int main (int argc, const char * argv[]) |
{ |
// Grab a CPU-based dispatch queue. |
dispatch_queue_t dq = gcl_create_dispatch_queue(CL_DEVICE_TYPE_CPU, NULL); |
if (!dq) |
{ |
fprintf(stdout, "Unable to create a CPU-based dispatch queue.\n"); |
exit(1); |
} |
// Display the OpenCL device associated with this dispatch queue. |
display_device(gcl_get_device_id_with_dispatch_queue(dq)); |
buffer_test(dq); |
fprintf(stdout, "\nDone.\n\n"); |
dispatch_release(dq); |
} |
Listing 9-2 Sample kernel squares an input array
// A very simple kernel which squares an input array. The results are |
// stored in another buffer, but could just as well be stored in the |
// 'input' array -- that's a developer choice. |
// Note that input and results are declared as 'global', indicating |
// that they point to allocations in the device's global memory. |
kernel void square( global float* input, global float* results ) |
{ |
// We've launched our kernel (in the host-side code) such that each |
// work item squares one incoming float. The item each work item |
// should process corresponds to its global work item id. |
size_t index = get_global_id(0); |
float val = input[index]; |
results[index] = val * val; |
} |
Copyright © 2018 Apple Inc. All Rights Reserved. Terms of Use | Privacy Policy | Updated: 2018-06-04