-
Beyond the basics of structured concurrency
It's all about the task tree: Find out how structured concurrency can help your apps manage automatic task cancellation, task priority propagation, and useful task-local value patterns. Learn how to manage resources in your app with useful patterns and the latest task group APIs. We'll show you how you can leverage the power of the task tree and task-local values to gain insight into distributed systems.
Before watching, review the basics of Swift Concurrency and structured concurrency by checking out “Swift concurrency: Behind the scenes” and “Explore structured concurrency in Swift” from WWDC21.Chapters
- 0:56 - Structured concurrency
- 3:11 - Task tree
- 3:44 - Task cancellation
- 5:26 - withTaskCancellationHandler
- 8:36 - Task priority
- 10:23 - Patterns with task groups
- 11:27 - Limiting concurrent tasks in TaskGroups
- 12:22 - DiscardingTaskGroup
- 13:53 - Task-local values
- 16:58 - swift-log
- 17:19 - MetadataProvider
- 18:58 - Task traces
- 19:46 - Swift-Distributed-Tracing
- 20:42 - Instrumenting distributed computations
- 23:38 - Wrap-up
Resources
Related Videos
WWDC23
WWDC22
WWDC21
-
Search this video…
♪ ♪ Evan: Hi, my name is Evan. Today, we are going beyond the basics of structured concurrency, exploring how structured tasks can simplify realizing useful behaviors. Before we get started, if you're new or want to review structured concurrency, feel free to watch the "Explore structured concurrency in Swift" and "Swift concurrency: Behind the scenes" sessions from WWDC 2021.
Today, we will review the task hierarchy, and how it unlocks automatic task cancellation, priority propagation, and useful task-local value behaviors.
Then we will cover some patterns with task groups to help manage resource usage.
Finally, we'll look at how all of these come together to facilitate profiling and tracing tasks in a server environment.
Structured concurrency enables you to reason about concurrent code using well-defined points where execution branches off and runs concurrently, and where results from that execution rejoin, similar to how "if"-blocks and "for"-loops define how control-flow behaves in synchronous code. Concurrent execution is triggered when you use an "async let", a task group, or create a task or detached task.
Results rejoin the current execution at a suspension point, indicated by an "await".
Not all tasks are structured.
Structured tasks are created using "async let" and task groups, while unstructured tasks are created using Task and Task.detached. Structured tasks live to the end of the scope where they are declared, like local variables, and are automatically cancelled when they go out of scope, making it clear how long the task will live.
Whenever possible, prefer structured Tasks. The benefits of structured concurrency discussed later do not always apply to unstructured tasks.
Before we dive into the code, let's come up with a concrete example.
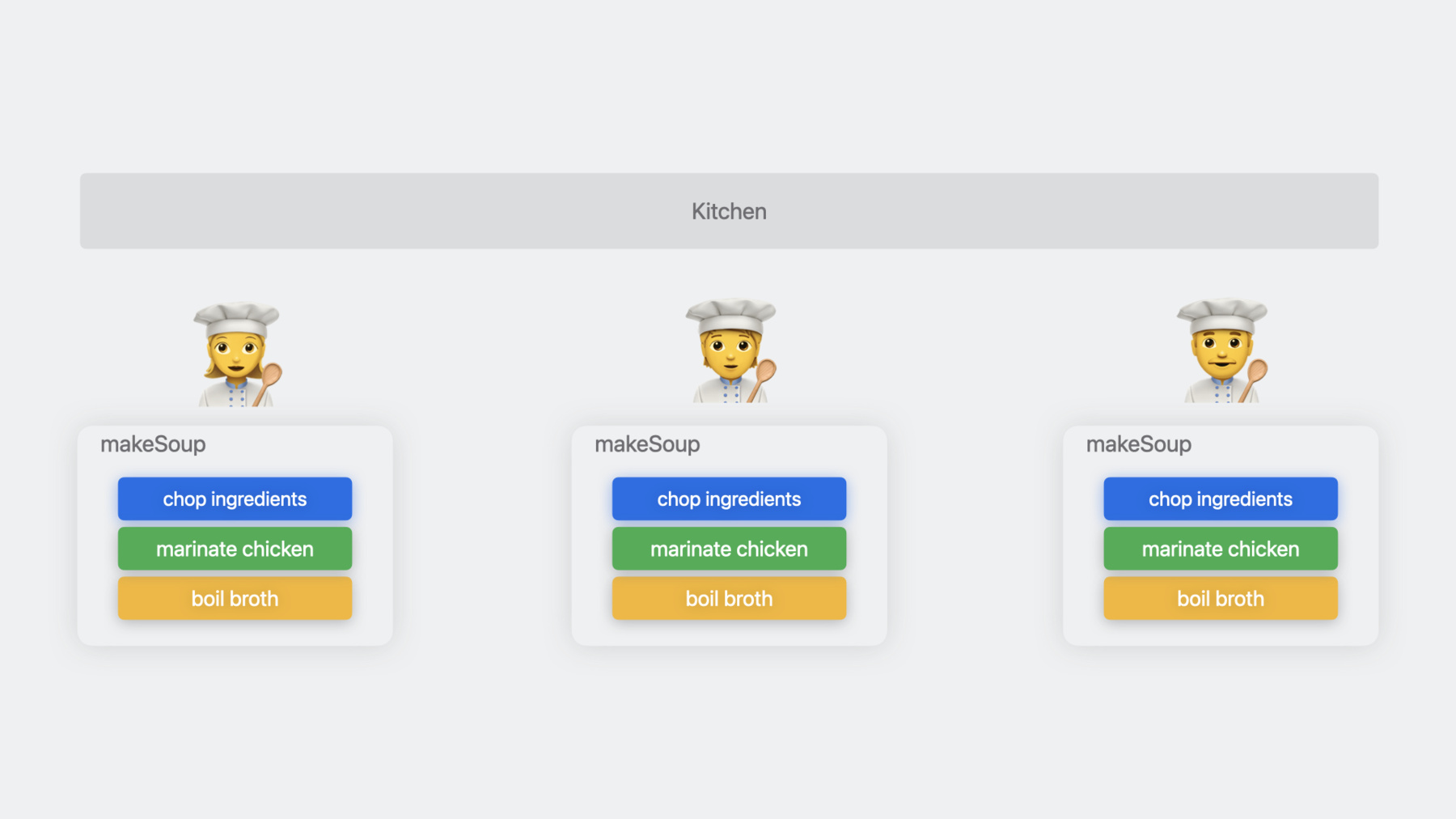
Suppose we have a kitchen with multiple chefs preparing soup. Soup preparation consists of multiple steps.
The chefs have to cut ingredients, marinate chicken, bring the broth to a boil, and finally, cook the soup before it is ready to serve. Some tasks can be performed in parallel, while others must be done in a specific order.
Let's see how we can express this in code.
For now, we'll focus on the makeSoup function.
You may find yourself creating unstructured Tasks to add concurrency to your functions, and awaiting their values when necessary.
While this expresses which tasks can run concurrently and which cannot, this is not the recommended way to use concurrency in Swift. Here is the same function expressed using structured concurrency. Since we have a known number of child tasks to create, we can use the convenient "async let" syntax. These tasks form a structured relationship with their parent task. We will talk about why this is important shortly.
makeSoup calls a number of asynchronous functions.
One of them is "chopIngredients", which takes a list of ingredients and uses a task group to chop all of them concurrently.
Now that we are familiar with makeSoup, let's take a look at the task hierarchy. Child tasks are indicated by the colored boxes, while the arrows point from parent task to child task.
makeSoup has three child tasks for chopping ingredients, marinating chicken, and boiling broth.
chopIngredients uses a task group to create a child task for each ingredient. If we have three ingredients, it too will create three children.
This parent-child hierarchy forms a tree, the task tree.
Now that we've introduced the task tree, let's start identifying how that benefits our code. Task cancellation is used to signal that the app no longer needs the result of a task and the task should stop and either return a partial result or throw an error.
In our soup example, we may want to stop making a soup order if that customer left, decided they wanted to order something else, or it's closing time.
What causes task a cancellation? Structured tasks are cancelled implicitly when they go out of scope, though you can call "cancelAll" on task groups to cancel all active children and any future child tasks.
Unstructured tasks are cancelled explicitly with the "cancel" function.
Cancelling the parent task results in the cancellation of all child tasks.
Cancellation is cooperative, so child tasks aren't immediately stopped.
It simply sets the "isCancelled" flag on that task. Actually acting on the cancellation is done in your code.
Cancellation is a race.
If the task is cancelled before our check, "makeSoup" throws a "SoupCancellationError".
If the task is cancelled after the guard executes, the program will carry on preparing the soup.
If we are going to throw a cancellation error instead of returning a partial result, we can call "Task.checkCancellation", which throws a "CancellationError" if the task was cancelled. It's important to check the task cancellation status before starting any expensive work to verify that the result is still necessary. Cancellation checking is synchronous, so any function, asynchronous or synchronous, that should react to cancellation should check the task cancellation status before continuing. Polling for cancellation with "isCancelled" or "checkCancellation" is useful when the task is running, but there are times when you may need to respond to cancellation while the task is suspended and no code is running, like when implementing an AsyncSequence. This is where "withTaskCancellationHandler" is useful.
Let's introduce a shift function.
The cook should make soups as orders come in until the end of their shift, signaled by a task cancellation.
In one cancellation scenario, the asynchronous for-loop gets a new order before it is cancelled. The "makeSoup" function handles the cancellation as we defined earlier, and throws an error.
In another scenario, the cancellation may take place while the task is suspended, waiting on the next order.
This case is more interesting because the task isn't running, so we can't explicitly poll for the cancellation event.
Instead, we have to use the cancellation handler to detect the cancellation event and break out of the asynchronous for-loop. The orders are produced from an AsyncSequence.
AsyncSequences are driven by an AsyncIterator, which defines an asynchronous "next" function.
Like with synchronous iterators, the "next" function returns the next element in the sequence, or nil to indicate that we are at the end of the sequence. Many AsyncSequences are implemented with a state machine, which we use to stop the running sequence.
In our example here, when "isRunning" is true, the sequence should continue emitting orders. Once the task is cancelled, we need to indicate that the sequence is done and should shut down.
We do this by synchronously calling the "cancel" function on our sequence state machine.
Note that because the cancellation handler runs immediately, the state machine is shared mutable state between the cancellation handler and main body, which can run concurrently. We'll need to protect our state machine.
While actors are great for protecting encapsulated state, we want to modify and read individual properties on our state machine, so actors aren't quite the right tool for this.
Furthermore, we can't guarantee the order that operations run on an actor, so we can't ensure that our cancellation will run first. We'll need something else. I've decided to use atomics from the Swift Atomics package, but we could use a dispatch queue or locks.
These mechanisms allow us to synchronize the shared state, avoiding race conditions, while allowing us to cancel the running state machine without introducing an unstructured task in the cancellation handler.
The task tree automatically propagates task cancellation information. Instead of having to worry about a cancellation token and synchronization, we let the Swift runtime handle it for us safely.
Remember, cancellation does not stop a task from running, it only signals to the task that it has been cancelled and should stop running as soon a possible.
It is up to your code to check for cancellation.
Next, let's consider how the structured task tree helps propagate priority and avoid priority inversions.
First, what is priority, and why do we care? Priority is your way to communicate to the system how urgent a given task is. Certain tasks, like responding to a button press, need to run immediately or the app will appear frozen.
Meanwhile, other tasks, like prefetching content from a server, can run in the background without anyone noticing.
Second, what is a priority inversion? A priority inversion happens when a high-priority task is waiting on the result of a lower-priority task.
By default, child tasks inherit their priority from their parent, so assuming that makeSoup is running in a task at medium priority, all child tasks will also run at medium priority.
Let's say a VIP guest who comes to our restaurant looking for soup.
We give their soup a higher priority to ensure we get a good review.
When they await their soup, the priority of all child tasks is escalated, ensuring that no high-priority task is waiting on a lower-priority task, avoiding the priority inversion.
Awaiting a result from a task with a higher priority escalates the priority of all child tasks in the task tree.
Note that awaiting the next result of a task group escalates all child tasks in the group, since we don't know which one is most likely to complete next.
The concurrency runtime uses priority queues to schedule tasks, so higher-priority tasks are selected to run before lower-priority tasks.
The task keeps the escalated priority for the remainder of its lifetime.
It's not possible to undo a priority escalation.
We effectively satisfied our VIP guest with a speedy soup delivery and got a good review, so our kitchen is starting to get popular now. We want to ensure we're using our resources effectively and noticed that we're creating a lot of chopping tasks.
Let's investigate some useful patterns for managing concurrency with task groups.
We only have space for so many cutting boards.
If we chop too many ingredients simultaneously, we'll run out of space for other tasks, so we want to limit the number of ingredients getting chopped at the same time.
Going back to our code, we want to investigate the loop creating the chopping tasks.
We replace the original loop over each ingredient with a loop that starts up to the maximum number of chopping tasks.
Next, we want the loop collecting results to start a new task each time an earlier task finishes.
The new loop waits until one of the running tasks finish and, while there are still ingredients to chop, adds a new task to chop the next ingredient.
Let's distill this idea down to see the pattern more clearly.
The initial loop creates up to the maximum number of concurrent tasks, ensuring that we don't create too many.
Once the maximum number of tasks is running, we wait for one to finish.
After it finishes and we haven't hit a stopping condition, we create a new task to keep making progress.
This limits the number of concurrent tasks in the group since we won't start new work until earlier tasks finish.
Earlier, we talked about chefs working in shifts and using cancellation to indicate when their shift was over.
This is the Kitchen Service code handling the shift.
Each cook starts their shift in a separate task.
Once the cooks are working, we start a timer. When the timer finishes, we cancel all ongoing shifts.
Notice that none of the tasks return a value. New in Swift 5.9 is the withDiscardingTaskGroup API. Discarding task groups don't hold onto the results of completed child tasks. Resources used by tasks are freed immediately after the task finishes.
We can change the run method to make use of a discarding task group.
Discarding task groups automatically clean up their children, so there is no need to explicitly cancel the group and clean up.
The discarding task group also has automatic sibling cancellation.
If any of the child tasks throw an error, all remaining tasks are automatically cancelled.
This is ideal for our use case here. We can throw a "TimeToCloseError" when the shift is over, and it will automatically end the shift for all chefs.
The new discard task group automatically releases resources when a task finishes, unlike the normal task groups where you have to collect the result. This helps reduce memory consumption when you have many tasks that don't need to return anything, like when you're processing a stream of requests.
In some situations, you'll want to return a value from your task group, but also want to limit the number of concurrent tasks. We covered a general pattern for using the completion of one task to start another, avoiding a task explosion. We're making soup more efficiently than ever, but we still need to scale up more.
It's time to move production to the server.
With that comes challenges of tracing orders as they are processed.
Task-local values are here to help.
A task-local value is a piece of data associated with a given task, or more precisely, a task hierarchy. It's like a global variable, but the value bound to the task-local value is only available from the current task hierarchy.
Task-local values are declared as static properties with the "TaskLocal" property wrapper.
It's a good practice to make the task local optional.
Any task that doesn't have the value set will need to return a default value, which is easily represented by a nil optional. An unbound task local contains its default value.
In our case, we have an optional String, so it's nil and there is no cook associated with the current task. Task-local values can't be assigned to explicitly, but must be bound for a specific scope. The binding lasts for the duration of the scope, and reverts back to the original value at the end of the scope.
Going back to the task tree, each task has an associated place for task-local values.
We bound the name "Sakura" to the "cook"task-local variable before making soup. Only makeSoup stores the bound value. The children do not have any values saved in their task-local storage.
Looking for the value bound to a task-local variable involves recursively walking each parent until we find a task with that value.
If we find a task with the value bound, the task local will assume that value.
If we reach the root, indicated by the task not having a parent, the task local was not bound and we get the original default value. The Swift runtime is optimized to run these queries faster.
Instead of walking the tree, we have a direct reference to the task with the key we're looking for.
The recursive nature of the task tree lends itself nicely to shadowing values without losing the former value.
Suppose we want to track the current step in the soup-making process.
We can bind the "step" variable to "soup" in "'makeSoup", then rebind it to "chop" in "chopIngredients".
The value bound in chopIngredients will shadow the former value until we return from chopIngredients, where we observe the original value.
Through the powers of video editing magic, we've moved our service to the cloud to keep up with the demands for soup.
We still have the same soup-making functionality, but it's on a server instead.
We'll need to observe orders as they pass through the system to ensure they're being completed in a timely manner and to monitor for unexpected failures.
The server environment handles many requests concurrently, so we'll want to include information that will allow us to trace a given order.
Logging by hand is repetitive and verbose, which leads to subtle bugs and typos.
Oh no, I've accidentally logged the entire order instead of just the order ID.
Let's find out how we can use task-local values to make our logging more reliable.
On Apple devices, you'll want to continue using the OSLog APIs directly, but as parts of your application move to the cloud, you'll need other solutions.
SwiftLog is a logging API package with multiple backing implementations, allowing you to drop in a logging back end that suites your needs without making changes to your server.
MetadataProvider is a new API in SwiftLog 1.5.
Implementing a metadata provider makes it easy to abstract your logging logic to ensure that you're emitting consistent information about relevant values.
The metadata provider uses a dictionary-like structure, mapping a name to the value being logged. We want to automatically log the orderID task-local variable, so we check to see if it was defined, and if it is, add it to the dictionary. Multiple libraries may define their own metadata provider to look for library-specific information, so the MetadataProvider defines a "multiplex" function, which takes multiple metadata providers and combines them into a single object.
Once we have a metadata provider, we initialize the logging system with that provider, and we're ready to start logging.
The logs automatically include information specified in the metadata provider, so we don't need to worry about including it in the log message.
The logs show as order 0 enters the kitchen, and where our chefs picks up that order.
Values in the metadata provider are listed clearly in the log, making it easier for you to track an order through the soup-making process.
Task-local values allow you to attach information to a task hierarchy.
All tasks, except detached tasks, inherit task-local values from the current task. They are bound in a given scope to a specific task tree, providing you with low-level building blocks to propagate additional context information through the task hierarchy. Now we'll use the task hierarchy and tools it provides us to trace and profile a concurrent distributed system. When working with concurrency on Apple platforms, Instruments is your friend. The Swift Concurrency instrument gives you insight into the relationships between your structured tasks. For more information, check out the session, "Visualize and optimize Swift concurrency." Instruments also introduced an HTTP traffic instrument in the "Analyze HTTP Traffic in instruments" session. The HTTP traffic analyzer only shows traces for events happening locally.
The profile shows a grey box while waiting for a response from the server, so we'll need more information to understand how to improve the performance of our server.
Introducing the new Swift Distributed Tracing package.
The task tree is great for managing child tasks in a single task hierarchy.
Distributed tracing allows you to leverage the benefits of the task tree across multiple systems to gain insight into performance characteristics and task relationships. The Swift Distributed Tracing package has an implementation of the OpenTelemetry protocol, so existing tracing solutions, like Zipkin and Jaeger, will work out of the box.
Our goal with Swift Distributed Tracing is to fill in the opaque "waiting for response" in Xcode Instruments with detailed information about what is happening in the server. We'll need to instrument our server code to figure out where we need to focus.
Distributed tracing is a little different from tracing processes locally.
Instead of getting a trace per-function, we instrument our code with spans using the "withSpan" API.
Spans allow us to assign names to regions of code that are reported in the tracing system. Spans don't need to cover an entire function.
They can provide more insight on specific pieces of a given function.
withSpan annotates our tasks with additional trace IDs and other metadata, allowing the tracing system to merge the task trees into a single trace. The tracing system has enough information to provide you with insight into the task hierarchy, along with information about the runtime performance characteristics of a task.
The span name is presented in the tracing UI.
You'll want to keep them short and descriptive so that you can easily find information about a specific span without clutter.
We can attach additional metadata with the use of span attributes, so we don't need to clutter the span name with the order ID.
Here we've replaced the span name with the "#function" directive to automatically fill the span name with the function name, and used the span attribute to attach the current order ID to the span information reported to the tracer.
Tracing systems usually present the attributes while inspecting a given span.
Most spans come with HTTP status codes, request and response sizes, start and end times, and other metadata making it easier for you to track information passing through your system.
As noted on the previous slide, you can define your own attributes. For more examples of how you can leverage spans, please check out the swift-distributed-tracing-extras repository.
If a task fails and throws an error, that information is also presented in the span and reported in the tracing system. Since spans contain both timing information and the relationships of tasks in the tree, it's a helpful way to track down errors caused by timing races and identify how they impact other tasks. We've talked about the tracing system and how it can reconstruct task trees using the trace IDs and how you can attach your own attributes to a span, but we haven't started working this into a distributed system yet. The beauty of the tracing system is that there is nothing more that needs to be done.
If we factor a chopping service out of our kitchen service, otherwise keeping the same code, the tracing system will automatically pick up the traces and relate them across different machines in the distributed system.
The trace view will indicate that the spans are running on a different machine, but will otherwise be the same. Distributed tracing is most powerful when all parts of the system embrace traces, including the HTTP clients, servers, and other RPC systems.
Swift Distributed Tracing leverages task-local values, built on the task trees, to automatically propagate all of the information necessary to produce reliable cross-node traces. Structured tasks unlock the secrets of your concurrent systems, providing you with tools to automatically cancel operations, automatically propagate priority information, and facilitate tracing complex distributed workloads.
All of these work because of the structured nature of concurrency in Swift.
I hope this session excited you about structured concurrency, and that you'll reach for structured tasks before using unstructured alternatives.
Thank you for watching! I can't wait to see what other useful patterns you'll come up with using structured concurrency.
Mm, soup! ♪ ♪
-
-
2:27 - Unstructured concurrency
func makeSoup(order: Order) async throws -> Soup { let boilingPot = Task { try await stove.boilBroth() } let choppedIngredients = Task { try await chopIngredients(order.ingredients) } let meat = Task { await marinate(meat: .chicken) } let soup = await Soup(meat: meat.value, ingredients: choppedIngredients.value) return await stove.cook(pot: boilingPot.value, soup: soup, duration: .minutes(10)) } -
2:42 - Structured concurrency
func makeSoup(order: Order) async throws -> Soup { async let pot = stove.boilBroth() async let choppedIngredients = chopIngredients(order.ingredients) async let meat = marinate(meat: .chicken) let soup = try await Soup(meat: meat, ingredients: choppedIngredients) return try await stove.cook(pot: pot, soup: soup, duration: .minutes(10)) } -
3:00 - Structured concurrency
func chopIngredients(_ ingredients: [any Ingredient]) async -> [any ChoppedIngredient] { return await withTaskGroup(of: (ChoppedIngredient?).self, returning: [any ChoppedIngredient].self) { group in // Concurrently chop ingredients for ingredient in ingredients { group.addTask { await chop(ingredient) } } // Collect chopped vegetables var choppedIngredients: [any ChoppedIngredient] = [] for await choppedIngredient in group { if choppedIngredient != nil { choppedIngredients.append(choppedIngredient!) } } return choppedIngredients } } -
4:32 - Task cancellation
func makeSoup(order: Order) async throws -> Soup { async let pot = stove.boilBroth() guard !Task.isCancelled else { throw SoupCancellationError() } async let choppedIngredients = chopIngredients(order.ingredients) async let meat = marinate(meat: .chicken) let soup = try await Soup(meat: meat, ingredients: choppedIngredients) return try await stove.cook(pot: pot, soup: soup, duration: .minutes(10)) } -
4:58 - Task cancellation
func chopIngredients(_ ingredients: [any Ingredient]) async throws -> [any ChoppedIngredient] { return try await withThrowingTaskGroup(of: (ChoppedIngredient?).self, returning: [any ChoppedIngredient].self) { group in try Task.checkCancellation() // Concurrently chop ingredients for ingredient in ingredients { group.addTask { await chop(ingredient) } } // Collect chopped vegetables var choppedIngredients: [any ChoppedIngredient] = [] for try await choppedIngredient in group { if let choppedIngredient { choppedIngredients.append(choppedIngredient) } } return choppedIngredients } } -
5:47 - Cancellation and async sequences
actor Cook { func handleShift<Orders>(orders: Orders) async throws where Orders: AsyncSequence, Orders.Element == Order { for try await order in orders { let soup = try await makeSoup(order) // ... } } } -
6:41 - Cancellation and async sequences
public func next() async -> Order? { return await withTaskCancellationHandler { let result = await kitchen.generateOrder() guard state.isRunning else { return nil } return result } onCancel: { state.cancel() } } -
7:40 - AsyncSequence state machine
private final class OrderState: Sendable { let protectedIsRunning = ManagedAtomic<Bool>(true) var isRunning: Bool { get { protectedIsRunning.load(ordering: .acquiring) } set { protectedIsRunning.store(newValue, ordering: .relaxed) } } func cancel() { isRunning = false } } -
10:55 - Limiting concurrency with TaskGroups
func chopIngredients(_ ingredients: [any Ingredient]) async -> [any ChoppedIngredient] { return await withTaskGroup(of: (ChoppedIngredient?).self, returning: [any ChoppedIngredient].self) { group in // Concurrently chop ingredients for ingredient in ingredients { group.addTask { await chop(ingredient) } } // Collect chopped vegetables var choppedIngredients: [any ChoppedIngredient] = [] for await choppedIngredient in group { if let choppedIngredient { choppedIngredients.append(choppedIngredient) } } return choppedIngredients } } -
11:01 - Limiting concurrency with TaskGroups
func chopIngredients(_ ingredients: [any Ingredient]) async -> [any ChoppedIngredient] { return await withTaskGroup(of: (ChoppedIngredient?).self, returning: [any ChoppedIngredient].self) { group in // Concurrently chop ingredients let maxChopTasks = min(3, ingredients.count) for ingredientIndex in 0..<maxChopTasks { group.addTask { await chop(ingredients[ingredientIndex]) } } // Collect chopped vegetables var choppedIngredients: [any ChoppedIngredient] = [] for await choppedIngredient in group { if let choppedIngredient { choppedIngredients.append(choppedIngredient) } } return choppedIngredients } } -
11:17 - Limiting concurrency with TaskGroups
func chopIngredients(_ ingredients: [any Ingredient]) async -> [any ChoppedIngredient] { return await withTaskGroup(of: (ChoppedIngredient?).self, returning: [any ChoppedIngredient].self) { group in // Concurrently chop ingredients let maxChopTasks = min(3, ingredients.count) for ingredientIndex in 0..<maxChopTasks { group.addTask { await chop(ingredients[ingredientIndex]) } } // Collect chopped vegetables var choppedIngredients: [any ChoppedIngredient] = [] var nextIngredientIndex = maxChopTasks for await choppedIngredient in group { if nextIngredientIndex < ingredients.count { group.addTask { await chop(ingredients[nextIngredientIndex]) } nextIngredientIndex += 1 } if let choppedIngredient { choppedIngredients.append(choppedIngredient) } } return choppedIngredients } } -
11:26 - Limiting concurrency with TaskGroups
withTaskGroup(of: Something.self) { group in for _ in 0..<maxConcurrentTasks { group.addTask { } } while let <partial result> = await group.next() { if !shouldStop { group.addTask { } } } } -
11:56 - Kitchen Service
func run() async throws { try await withThrowingTaskGroup(of: Void.self) { group in for cook in staff.keys { group.addTask { try await cook.handleShift() } } group.addTask { // keep the restaurant going until closing time try await Task.sleep(for: shiftDuration) } try await group.next() // cancel all ongoing shifts group.cancelAll() } } -
12:41 - Introducing DiscardingTaskGroups
func run() async throws { try await withThrowingDiscardingTaskGroup { group in for cook in staff.keys { group.addTask { try await cook.handleShift() } } group.addTask { // keep the restaurant going until closing time try await Task.sleep(for: shiftDuration) throw TimeToCloseError() } } } -
14:10 - TaskLocal values
actor Kitchen { @TaskLocal static var orderID: Int? @TaskLocal static var cook: String? func logStatus() { print("Current cook: \(Kitchen.cook ?? "none")") } } let kitchen = Kitchen() await kitchen.logStatus() await Kitchen.$cook.withValue("Sakura") { await kitchen.logStatus() } await kitchen.logStatus() -
16:17 - Logging
func makeSoup(order: Order) async throws -> Soup { log.debug("Preparing dinner", [ "cook": "\(self.name)", "order-id": "\(order.id)", "vegetable": "\(vegetable)", ]) // ... } func chopVegetables(order: Order) async throws -> [Vegetable] { log.debug("Chopping ingredients", [ "cook": "\(self.name)", "order-id": "\(order.id)", "vegetable": "\(vegetable)", ]) async let choppedCarrot = try chop(.carrot) async let choppedPotato = try chop(.potato) return try await [choppedCarrot, choppedPotato] } func chop(_ vegetable: Vegetable, order: Order) async throws -> Vegetable { log.debug("Chopping vegetable", [ "cook": "\(self.name)", "order-id": "\(order)", "vegetable": "\(vegetable)", ]) // ... } -
17:33 - MetadataProvider in action
let orderMetadataProvider = Logger.MetadataProvider { var metadata: Logger.Metadata = [:] if let orderID = Kitchen.orderID { metadata["orderID"] = "\(orderID)" } return metadata } -
17:50 - MetadataProvider in action
let orderMetadataProvider = Logger.MetadataProvider { var metadata: Logger.Metadata = [:] if let orderID = Kitchen.orderID { metadata["orderID"] = "\(orderID)" } return metadata } let chefMetadataProvider = Logger.MetadataProvider { var metadata: Logger.Metadata = [:] if let chef = Kitchen.chef { metadata["chef"] = "\(chef)" } return metadata } let metadataProvider = Logger.MetadataProvider.multiplex([orderMetadataProvider, chefMetadataProvider]) LoggingSystem.bootstrap(StreamLogHandler.standardOutput, metadataProvider: metadataProvider) let logger = Logger(label: "KitchenService") -
18:13 - Logging with metadata providers
func makeSoup(order: Order) async throws -> Soup { logger.info("Preparing soup order") async let pot = stove.boilBroth() async let choppedIngredients = chopIngredients(order.ingredients) async let meat = marinate(meat: .chicken) let soup = try await Soup(meat: meat, ingredients: choppedIngredients) return try await stove.cook(pot: pot, soup: soup, duration: .minutes(10)) } -
20:30 - Profile server-side execution
func makeSoup(order: Order) async throws -> Soup { try await withSpan("makeSoup(\(order.id)") { span in async let pot = stove.boilWater() async let choppedIngredients = chopIngredients(order.ingredients) async let meat = marinate(meat: .chicken) let soup = try await Soup(meat: meat, ingredients: choppedIngredients) return try await stove.cook(pot: pot, soup: soup, duration: .minutes(10)) } } -
21:36 - Profiling server-side execution
func makeSoup(order: Order) async throws -> Soup { try await withSpan(#function) { span in span.attributes["kitchen.order.id"] = order.id async let pot = stove.boilWater() async let choppedIngredients = chopIngredients(order.ingredients) async let meat = marinate(meat: .chicken) let soup = try await Soup(meat: meat, ingredients: choppedIngredients) return try await stove.cook(pot: pot, soup: soup, duration: .minutes(10)) } }
-