-
Meet Swift Regex
Learn how you can process strings more effectively when you take advantage of Swift Regex. Come for concise literals but stay for Regex builders — a new, declarative approach to string processing. We'll also explore the Unicode models in String and share how Swift Regex can make Unicode-correct processing easy.
Resources
Related Videos
WWDC22
-
Search this video…
- Hello, I am Michael Ilseman and I'm an engineer on the Swift standard library team. Join me as we meet and get to know Regex in Swift. There's a lot to Swift Regex, and we'll be getting just a taste of everything it has to offer. Let's say we're developers collaborating with some financial investigators on a tool to analyze transactions for irregularities. Now, you'd think that for a task this important we'd be processing well-structured data. But instead, we have a bunch of strings. Here the first field has the transaction kind, the second the transaction date, the third field the individual or institution, the fourth and final field the amount in US dollars. Fields are separated by either 2-or-more spaces or a tab for a very important technical reason that no one involved can remember. And, yes, that date field is totally ambiguous. We're just going to hope that it's month/day/year and see what happens. Processing these transactions involves processing strings, and string is a collection, which means we get access to generic collection algorithms. These algorithms basically come in two kinds, those that operate over elements, and those that operate over indices.
We can try to use the element-based algorithms by splitting out the transaction fields, but the field separator being either tab or 2-or-more spaces makes this difficult. Splitting on whitespace alone doesn't cut it. Another approach is to drop down to low-level index manipulation code.
But it's hard to do right, and even if you know what you're doing, it still takes a lot of code. Let's come back to split. The reason this approach doesn't work is because it is element-based while the field separator is a more complex pattern. A solution found in a wide variety of languages is to write a regular expression. Regular expressions emerged from formal language theory where they define a regular language. They entered practical application for search in editors and command-line tools as well as lexical analysis in compilers. These applications take regular expressions beyond their theoretical roots, as they need to extract portions of the input, control and direct execution, and add expressive power. And Swift is taking them further. We call this derivative Regex.
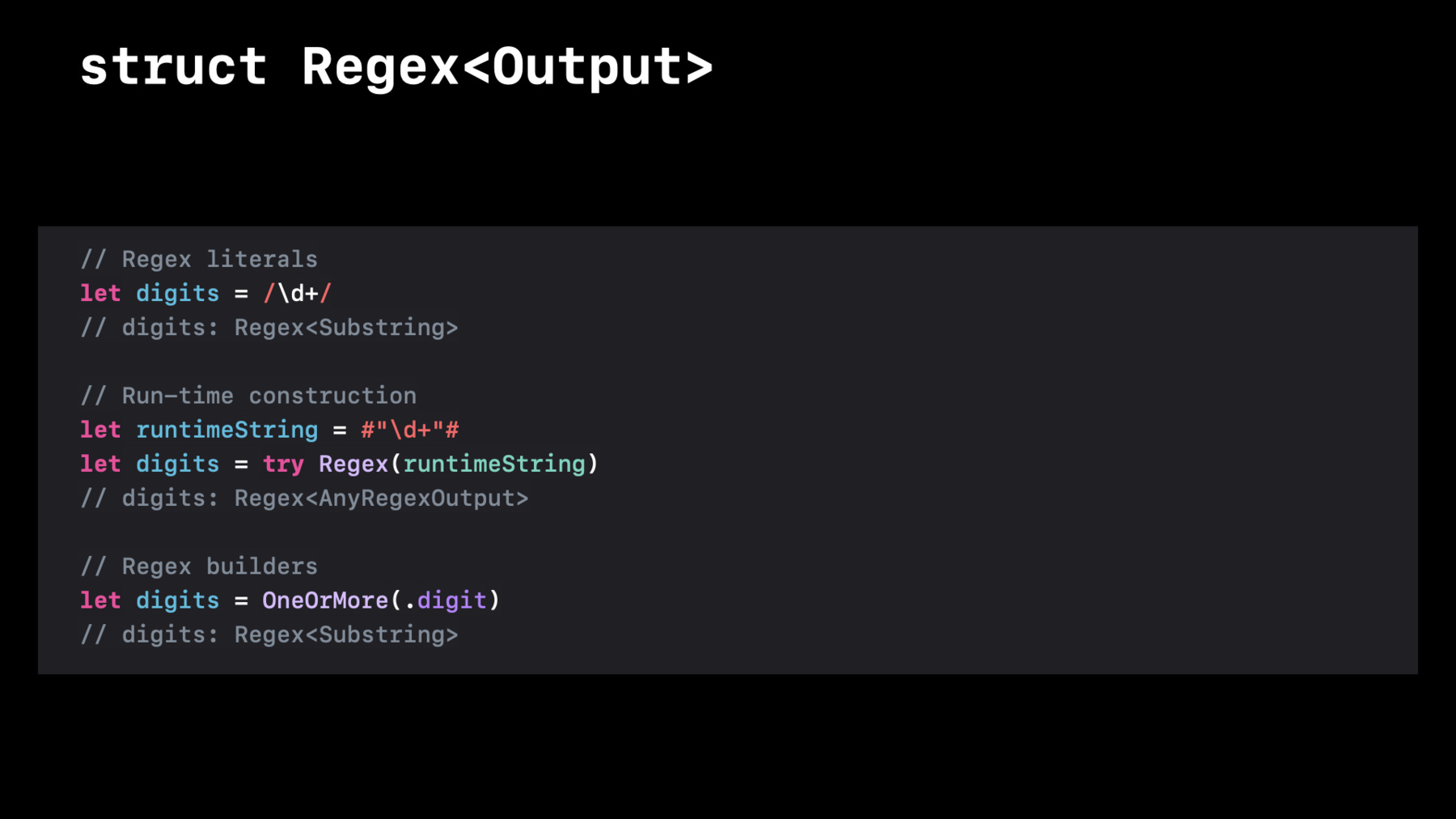
Regex is a struct generic over its Output, which is the result of applying it, including captures. You can create one using a literal containing regex syntax in between slash delimiters. Swift's regex syntax is compatible with Perl, Python, Ruby, Java, NSRegularExpression, and many, many others.
This regex matches one or more digits. The compiler knows regex syntax, so you'll get syntax highlighting, compile-time errors, and even strongly-typed captures, which we'll be meeting later. A regex can be created at run-time from a string containing the same regex syntax. This is useful for search fields in editors or command-line tools. This will throw an error at run-time if the input contains invalid syntax. The output type is an existential AnyRegexOutput, because the types and number of captures won't be known until run-time.
And the same regex can be written using a declarative and well-structured, albeit more verbose, regex builder.
Let's adapt our split approach from earlier to use a regex literal. The first portion matches 2-or-more occurrences of any whitespace character. The second portion matches a single horizontal tab. And the pipe character denotes a choice between alternatives, giving us a field separator of either 2-or-more-spaces or a single tab. Now that our fields are split, let's make a contribution to civilization itself and normalize that field separator to a single tab and be done with it. We could call 'join' on the result after splitting, but there's a better algorithm for that: 'replacing' lets us replace all field separators with a single tab.
So we go out and evangelize our clearly superior approach to anyone who will listen. Adoption is...slow but promising. If you are familiar with regular expressions, you may also know of their mixed reputation. As the old saying goes, "I had a problem, so I wrote a regular expression. Now I have two problems." But Swift regex is different.
Swift advances the art in four key areas. Regex syntax is concise and expressive, but it can become terse and difficult to read. And newer features have to use increasingly cryptic syntax.
Swift regexes can be structured and organized the way we structure and organize source code through Regex builders. Literals are concise, builders give structure, and literals can be used within builders to find that perfect balance.
Textual representations for data have become a lot more complicated, and handling them correctly requires a standards-conforming parser. Swift regex lets you interweave industrial-strength parsers as individual components of a regex. This is done in a library-extensible fashion, meaning any parsers can participate.
Much of the history of applied regular expressions took place in a world where the entire computer system only supported a single language and encoding, most notably ASCII. But the modern world is Unicode. Swift regex does the Unicode without compromising expressivity. And finally, the power of regular expressions can open up a broad search space that must be exhaustively explored. This makes their execution difficult to reason about. Some languages support controls, but because they're behind cryptic syntax, they tend to be obscure. Swift regex provides predictable execution and surfaces controls prominently. Let's go back to the financial statements we've been working with and fully parse each transaction using Regex builders, a declarative approach to string processing in Swift. We'll import the RegexBuilder module to get started. We can re-use the field separator regex that we just defined. The first field is simple; it's either a CREDIT or a DEBIT. We can use the regex literal syntax we've already seen to write that. After that comes a field separator, and then the date. Parsing dates by hand is a bad idea. Foundation has really good parsers for types like dates, numbers, and URLs, and we can use them directly in a Regex Builder.
We supply an explicit locale which is our best guess at the author's intent. We do this instead of implicitly using the system's current locale. We can always change it later, and it's easy to do because we made our assumptions _explicit_ in code.
The third field can be "anything," so it's tempting to just write "one or more of anything." And while that will give us the right answer, it does a lot of unnecessary work first, because it starts off by matching anything else that comes after it. The regex will back up one character at a time and try the rest of the pattern. We want to tell the regex to stop when it sees the terminating field separator. There are a quite a few ways that we could accomplish this. One good way to do this is to use NegativeLookahead which peeks at the next part of the input without actually consuming it. Here we peek at the input to make sure a field separator isn't coming up before matching any character. NegativeLookahead is one of a family of tools that let you precisely control how a Regex matches its components.
Finally, we match the amount, again using one of Foundation's parsers, this time for currency. We've been assuming that comma is a thousands separator while period is a decimal separator, and we make this assumption explicit.
We've built a regex that lets us parse a line from the transaction ledger. We don't just want to recognize the lines. We want to extract some of this data out. To do this, we use captures, which extract portions of our input for later processing. By convention, the '0th' capture is the part of the input that the entire regex matched, and each explicit capture follows. Our transaction kind is captured as a Substring that is a slice of our input. For dates, we actually capture the strongly-typed value that was parsed out without needing to post-process the text. The individual or institution is again captured as a portion of our input, and the decimal capture is another strongly-typed value. To use it, we extract date and decimal values from the match result, and the investigators take it from here. It's at this point that we recommend they dump the data into a real database for obvious benefits like structured queries. They have a...different opinion. They want to keep everything as strings. Which is good news for this talk because we get to see even more of Swift Regex. Everything's going well until suddenly it's not. We just learned that the date order in the transaction text, which we told everyone was totally ambiguous, is in fact ambiguous. It's not always the same, and the leading theory is that it depends on the currency used in the transaction. Because of course it does. This means that US dollars is month/day/year and British pounds is day/month/year. So let's write a sed-like script to disambiguate this. For our regex, we're going to use an extended delimiter. This allows us to have slashes inside without having to escape them. This also gives us access to an extended syntax mode where whitespace is ignored, which means we can use whitespace for readability, just like in normal code. We used named captures, which show up in the Regex's output as tuple labels.
And we use a Unicode Property to recognize currency symbols. This makes our regex more adaptable; we will handle the specific symbols in application logic.
Rather than try to cut and splice text manually, we're going to yet again use Foundation's date parser. pickStrategy receives the currency symbol and will determine a parse strategy based on it. All of our assumptions are explicit in code, which makes it easier to adapt and evolve, something we almost certainly will end up needing.
Let's use our regex and helper function with a find-and-replace algorithm by supplying a closure which uses the match result, including captures, to construct the replacement string. We pick a strategy based on the captured currency and parse the captured date. We can access the captures by name, instead of only by position. For our output, we'll format the new date using ISO-8601, an unambiguous industry standard. Our tool transforms this ledger Into an unambiguous one. Because we're using a real date parser and formatter, we're far more adaptable to changing requirements. And using a Unicode property to recognize currency symbols helps us evolve that much quicker. A regex declares an algorithm over some model of String. Swift's String presents multiple models for working with Unicode. This string, representing a love story for the ages, contains 3 characters. These characters are complex entities formally called Unicode extended grapheme clusters. A single Character is composed of one or more Unicode scalar values. String provides a UnicodeScalarView to access this lower-level representation of its contents. This enables advanced usage as well as compatibility with other systems.
Our first Character, who is our story's protagonist, is composed of 4 Unicode scalars: ZOMBIE, Zero Width Joiner, FEMALE SIGN, and uh... VARIATION SELECTOR-16, which in this context signals a preference to be rendered as emoji. Of course! These scalars produce the single emoji we see visually. When strings are stored in memory, they are encoded as UTF-8 bytes. We can view these bytes using the UTF-8 view. UTF-8 is a variable-width encoding, meaning multiple bytes may be needed for a single scalar, and as we saw, multiple scalars may be needed for a single character. Our story's protagonist, represented by 4 Unicode scalars, is encoded using 13 UTF-8 bytes. In addition to being composed of multiple scalars, the same exact character can sometimes be represented by different sets of scalars. This comes up a lot when handling languages other than English. In this example, the 'e' with an acute accent can be represented as either a single scalar, precomposed ‘e’ with acute accent, or as an ASCII 'e' followed by a combining acute accent. These are the same characters, so String comparison will return true. This is because String obeys what is formally called Unicode Canonical Equivalence.
From the perspective of the UnicodeScalarView, or the UTF-8 view, the contents are different, and we see this difference when we compare within these lower-level views. Just like String, Swift regex is obsessively Unicode correct by default. But it does this without compromising expressivity. Let's switch over a pair of strings. For the first string, we'll match the named Unicode Scalar SPARKLING HEART surrounded by any characters denoted by dot (.).
The any character class will match any Swift character; that is, any Unicode extended grapheme cluster.
For the second string, characters that are equal compare as equals... and we can ignore case. And now our simple love story has become a lot more complicated. Sometimes life, or in this case un-life, has complexities that we need to process.
Just like String, if you do need to process Unicode scalar values yourself, either for compatibility or sub-grapheme cluster precision, you can by matching with 'unicodeScalar' semantics. When we match at the Unicode Scalar level, the dot matches a single Unicode Scalar value instead of a full Swift Character. Which means we get to see our friend again: VARIATION-SELECTOR 16. This friendly little selector gets matched by the dot, and you can't see it because when it's all alone, it renders as empty whitespace. So helpful.
Now that we've worked with precision and correctness, let's do something a little different, and get back to finance. The investigators have returned, and this time they have an interesting request. They modified our transaction matching tool to sniff transactions live off the wire instead of processing ledgers after the fact. Looking at their code, they actually did a reasonably good job, but they're facing scaling issues and need our help. The transactions they are processing are very similar, but with minor differences. Instead of a date, they have a precise time stamp instead. This is represented in a clear, unambiguous, and shockingly proprietary format. They have a regular expression written in a prior century that matches this just fine. It's fine. Next they have a details field which includes individuals and identification codes. They filter transactions against this field by using a run-time compiled regex derived from input. Because this is live, and there are more fields later on, they like to bail early on any uninteresting transactions. Then comes an amount and other fields like checksums, which they handle just fine on their own. And of course, fields are still separated by 2-or-more spaces or a tab.
Their transaction matcher looks a lot like ours. They have their own regex for the timestamp, their details regex is compiled from input, and they handle the rest of the fields. They did a reasonably good job. Everything technically works. It just isn't scaling well. They notice that their timestamp and details regexes often match much more of the input than their fields. Ideally, these regexes would be constrained to only run over a single field. We handled a similar issue in our project by using negative lookahead, so let's pull that regex in.
'field' will efficiently match any character until it encounters a field separator, and we'd like to use it to contain their regexes. We could do this as a post-processing step, but because this is running live, we want to bail early if these regexes don't match their fields. We can do this using TryCapture. TryCapture passes the matched field to our closure, where we test against the investigator's timestamp and details regexes. If they match, we return the field's value, meaning that matching succeeded and the field is captured. Otherwise we return nil, which signals that matching failed.
TryCapture's closure actively participates in matching, which is exactly what we need. And with this, we've solved a major scaling issue. But there's still one more problem: when something later on in the transaction matcher fails, it can take a long time to exit.
Our fieldSeparator regex we defined at the very beginning matches 2-or-more whitespaces or a tab, which is what we want. If there are 8 whitespace characters, it will match all of them before trying the rest of the regex. But if the regex later fails, it will back up and only match 7 whitespace characters before trying again. And if that fails, it will match only 6 whitespace characters, and so on.
Only after trying all alternatives does matching fail. This backing up in order to try alternatives is called global backtracking or, in formal logics, the Kleene closure. It's what gives regular expressions their characteristic power. But it opens up a broad search space to explore, and here we want a more linear search space. We want to match all of the whitespace and never give any up. There are a couple tools that we could use; the more general tool is to put fieldSeparator in a local backtracking scope instead of a global one.
The Local builder creates a scope where, if the contained regex ever successfully matches, any untried alternatives are discarded.
Even if our transaction matcher fails later on, we don't go back to try consuming fewer spaces. Global backtracking, the default for regex, is great for search and fuzzy matching. Local is useful for matching precisely specified tokens. The field separator, as vexing as it may be, is precise.
Local is known elsewhere as an atomic non-capturing group, which can be a… frightening name. Makes it seem like your regex might blow up. But it actually does the opposite-- it contains the search space.
And with this, we've helped them solve their scaling issues. Today we got to meet Swift Regex, but there's so much more that we weren't able to cover. Be sure to check out Swift Regex: Beyond the Basics by my colleague Richard. Before we leave, I want to highlight a few points. Regex builders give structure. Regex literals are concise. The choice between when to use one over the other will ultimately be subjective.
Make sure to use real parsers whenever possible. This will save you massive amounts of time and avoid headaches. Just by using Swift's defaults, you're going to get far more Unicode support and goodness than anywhere else. Look for ways to use things like character properties effectively, such as when we matched the currency symbols. And finally, simplify your search and processing algorithms by using controls such as lookahead and local backtracking scopes. Thank you for watching.
-
-
1:35 - Processing collections
let transaction = "DEBIT 03/05/2022 Doug's Dugout Dogs $33.27" let fragments = transaction.split(whereSeparator: \.isWhitespace) // ["DEBIT", "03/05/2022", "Doug\'s", "Dugout", "Dogs", "$33.27"] -
1:49 - Low-level index manipulation
var slice = transaction[...] // Extract a field, advancing `slice` to the start of the next field func extractField() -> Substring { let endIdx = { var start = slice.startIndex while true { // Position of next whitespace (including tabs) guard let spaceIdx = slice[start...].firstIndex(where: \.isWhitespace) else { return slice.endIndex } // Tab suffices if slice[spaceIdx] == "\t" { return spaceIdx } // Otherwise check for a second whitespace character let afterSpaceIdx = slice.index(after: spaceIdx) if afterSpaceIdx == slice.endIndex || slice[afterSpaceIdx].isWhitespace { return spaceIdx } // Skip over the single space and try again start = afterSpaceIdx } }() defer { slice = slice[endIdx...].drop(while: \.isWhitespace) } return slice[..<endIdx] } let kind = extractField() let date = try Date(String(extractField()), strategy: Date.FormatStyle(date: .numeric)) let account = extractField() let amount = try Decimal(String(extractField()), format: .currency(code: "USD")) -
2:47 - Regex literals
// Regex literals let digits = /\d+/ // digits: Regex<Substring> -
3:20 - Regex created at run-time
// Run-time construction let runtimeString = #"\d+"# let digits = try Regex(runtimeString) // digits: Regex<AnyRegexOutput> -
3:44 - Regex builder
// Regex builders let digits = OneOrMore(.digit) // digits: Regex<Substring> -
3:56 - Split approach with a regex literal
let transaction = "DEBIT 03/05/2022 Doug's Dugout Dogs $33.27" let fragments = transaction.split(separator: /\s{2,}|\t/) // ["DEBIT", "03/05/2022", "Doug's Dugout Dogs", "$33.27"] -
4:36 - Normalize field separators
let transaction = "DEBIT 03/05/2022 Doug's Dugout Dogs $33.27" let normalized = transaction.replacing(/\s{2,}|\t/, with: "\t") // DEBIT»03/05/2022»Doug's Dugout Dogs»$33.27 -
6:55 - Create a Regex builder
// CREDIT 03/02/2022 Payroll from employer $200.23 // CREDIT 03/03/2022 Suspect A $2,000,000.00 // DEBIT 03/03/2022 Ted's Pet Rock Sanctuary $2,000,000.00 // DEBIT 03/05/2022 Doug's Dugout Dogs $33.27 import RegexBuilder let fieldSeparator = /\s{2,}|\t/ let transactionMatcher = Regex { /CREDIT|DEBIT/ fieldSeparator One(.date(.numeric, locale: Locale(identifier: "en_US"), timeZone: .gmt)) fieldSeparator OneOrMore { NegativeLookahead { fieldSeparator } CharacterClass.any } fieldSeparator One(.localizedCurrency(code: "USD").locale(Locale(identifier: "en_US"))) } -
9:04 - Use Captures to extract portions of input
let fieldSeparator = /\s{2,}|\t/ let transactionMatcher = Regex { Capture { /CREDIT|DEBIT/ } fieldSeparator Capture { One(.date(.numeric, locale: Locale(identifier: "en_US"), timeZone: .gmt)) } fieldSeparator Capture { OneOrMore { NegativeLookahead { fieldSeparator } CharacterClass.any } } fieldSeparator Capture { One(.localizedCurrency(code: "USD").locale(Locale(identifier: "en_US"))) } } // transactionMatcher: Regex<(Substring, Substring, Date, Substring, Decimal)> -
10:31 - Plot twist!
private let ledger = """ KIND DATE INSTITUTION AMOUNT ---------------------------------------------------------------- CREDIT 03/01/2022 Payroll from employer $200.23 CREDIT 03/03/2022 Suspect A $2,000,000.00 DEBIT 03/03/2022 Ted's Pet Rock Sanctuary $2,000,000.00 DEBIT 03/05/2022 Doug's Dugout Dogs $33.27 DEBIT 06/03/2022 Oxford Comma Supply Ltd. £57.33 """ // 😱 -
10:53 - Use named captures
let regex = #/ (?<date> \d{2} / \d{2} / \d{4}) (?<middle> \P{currencySymbol}+) (?<currency> \p{currencySymbol}) /# // Regex<(Substring, date: Substring, middle: Substring, currency: Substring)> -
11:33 - Use Foundation's date parser
let regex = #/ (?<date> \d{2} / \d{2} / \d{4}) (?<middle> \P{currencySymbol}+) (?<currency> \p{currencySymbol}) /# // Regex<(Substring, date: Substring, middle: Substring, currency: Substring)> func pickStrategy(_ currency: Substring) -> Date.ParseStrategy { switch currency { case "$": return .date(.numeric, locale: Locale(identifier: "en_US"), timeZone: .gmt) case "£": return .date(.numeric, locale: Locale(identifier: "en_GB"), timeZone: .gmt) default: fatalError("We found another one!") } } -
11:48 - Find and replace
let regex = #/ (?<date> \d{2} / \d{2} / \d{4}) (?<middle> \P{currencySymbol}+) (?<currency> \p{currencySymbol}) /# // Regex<(Substring, date: Substring, middle: Substring, currency: Substring)> func pickStrategy(_ currency: Substring) -> Date.ParseStrategy { … } ledger.replace(regex) { match -> String in let date = try! Date(String(match.date), strategy: pickStrategy(match.currency)) // ISO 8601, it's the only way to be sure let newDate = date.formatted(.iso8601.year().month().day()) return newDate + match.middle + match.currency } -
12:45 - A zombie love story
let aZombieLoveStory = "🧟♀️💖🧠" // Characters: 🧟♀️, 💖, 🧠 -
13:01 - A zombie love story in unicode scalars
aZombieLoveStory.unicodeScalars // Unicode scalar values: U+1F9DF, U+200D, U+2640, U+FE0F, U+1F496, U+1F9E0 -
13:44 - A zombie love story in UTF8
aZombieLoveStory.utf8 // UTF-8 code units: F0 9F A7 9F E2 80 8D E2 99 80 EF B8 8F F0 9F 92 96 F0 9F A7 A0 -
14:12 - Unicode canonical equivalence
"café".elementsEqual("cafe\u{301}") // true -
14:49 - String's views are compared at binary level
"café".elementsEqual("cafe\u{301}") // true "café".unicodeScalars.elementsEqual("cafe\u{301}".unicodeScalars) // false "café".utf8.elementsEqual("cafe\u{301}".utf8) // false -
15:14 - Unicode processing
switch ("🧟♀️💖🧠", "The Brain Cafe\u{301}") { case (/.\N{SPARKLING HEART}./, /.*café/.ignoresCase()): print("Oh no! 🧟♀️💖🧠, but 🧠💖☕️!") default: print("No conflicts found") } -
15:54 - Complex scalar processing
let input = "Oh no! 🧟♀️💖🧠, but 🧠💖☕️!" input.firstMatch(of: /.\N{SPARKLING HEART}./) // 🧟♀️💖🧠 input.firstMatch(of: /.\N{SPARKLING HEART}./.matchingSemantics(.unicodeScalar)) // ️💖🧠 -
17:56 - Live transaction matcher
let timestamp = Regex { ... } // proprietary let details = try Regex(inputString) let amountMatcher = /[\d.]+/ // CREDIT <proprietary> <redacted> 200.23 A1B34EFF ... let fieldSeparator = /\s{2,}|\t/ let transactionMatcher = Regex { Capture { /CREDIT|DEBIT/ } fieldSeparator Capture { timestamp } fieldSeparator Capture { details } fieldSeparator // ... } -
18:26 - Replace field separator
let field = OneOrMore { NegativeLookahead { fieldSeparator } CharacterClass.any } -
18:55 - Use TryCapture
// CREDIT <proprietary> <redacted> 200.23 A1B34EFF ... let fieldSeparator = /\s{2,}|\t/ let field = OneOrMore { NegativeLookahead { fieldSeparator } CharacterClass.any } let transactionMatcher = Regex { Capture { /CREDIT|DEBIT/ } fieldSeparator TryCapture(field) { timestamp ~= $0 ? $0 : nil } fieldSeparator TryCapture(field) { details ~= $0 ? $0 : nil } fieldSeparator // ... } -
21:45 - Fixing the scaling issues
// CREDIT <proprietary> <redacted> 200.23 A1B34EFF ... let fieldSeparator = Local { /\s{2,}|\t/ } let field = OneOrMore { NegativeLookahead { fieldSeparator } CharacterClass.any } let transactionMatcher = Regex { Capture { /CREDIT|DEBIT/ } fieldSeparator TryCapture(field) { timestamp ~= $0 ? $0 : nil } fieldSeparator TryCapture(field) { details ~= $0 ? $0 : nil } fieldSeparator // ... }
-