-
What's new in Create ML
Discover the latest updates to Create ML. We'll share improvements to Create ML's evaluation tools that can help you understand how your custom models will perform on real-world data. Learn how you can check model performance on each type of image in your test data and identify problems within individual images to help you troubleshoot mistaken classifications, poorly labeled data, and other errors. We'll also show you how to test your model with iPhone and iPad in live preview using Continuity Camera, and share how you can take Action Classification even further with the new Repetition Counting capabilities of the Create ML Components framework.
To learn more about all that Create ML can bring to your app, watch "Classify hand poses and actions with Create ML" and "Build dynamic iOS apps with the Create ML framework" from WWDC21.Resources
Related Videos
WWDC23
WWDC22
WWDC21
-
Search this video…
♪ Mellow instrumental hip-hop music ♪ ♪ Namaskar! Hello and welcome to WWDC22. My name is Vrushali Mundhe, engineer on the Create ML team, and I am excited to share with you what's new in Create ML. Create ML allows you to easily train powerful machine learning models with data you have collected to deliver unique experiences and enhance your apps. Create ML ships as an app bundled with Xcode, letting you quickly build and train Core ML models right on your Mac with no code. Create ML is also available as a Swift framework shipping in SDK. Using its APIs, you can easily automate model creation or create dynamic experiences powered by training directly from within your own app. To learn more about Create ML's core capabilities, you can check out these previous sessions. In this session, we'll talk about what's new in Create ML. We will start with new features in the Create ML app that can help evaluate the accuracy and utility of your models. We will then turn our attention to the Create ML framework, its extended capabilities, and ability to now highly customize models for your own app. Let's start by reviewing a typical workflow for model creation. Given an identified task, you begin by collecting and annotating data. Take, for example, wanting to visually identify groceries. For this image classification task, your starting point would be collecting and labeling images; here, some fruits and vegetables.
Create ML will then help you train a model from this data, which can be used in your app. However, before using this model, an important step is to evaluate how well it performs; here, seeing how accurate the model is on images, which were not part of the training set. Depending on evaluation, you may iterate on the model with additional data and modified training settings or, once the model is performing well enough, you're ready to integrate it into your app, I would like to focus on this evaluation step further. When performing an evaluation, we often turn to a set of metrics measured by testing your model on new data held out from training. You may start by looking at a top-level accuracy metric or dive into per-class statistics to get a general sense of the model's behavior and ability to generalize beyond what it was trained on. Ultimately, the model will be responsible for empowering data-driven experience in your app, and during evaluation, you want to identify the model's main strengths and weaknesses in terms of categories of inputs or scenarios; it works well or may fall short of expectations. There are new features in the Create ML app that can help you on this part of your model-creation journey. Let me show you a project that I'm working on. Here, I have a project set up to create a model to identify groceries. I started with collecting various fruit and vegetable images as my training data and labeled them appropriately. Here are my different classes and number of images for each class.
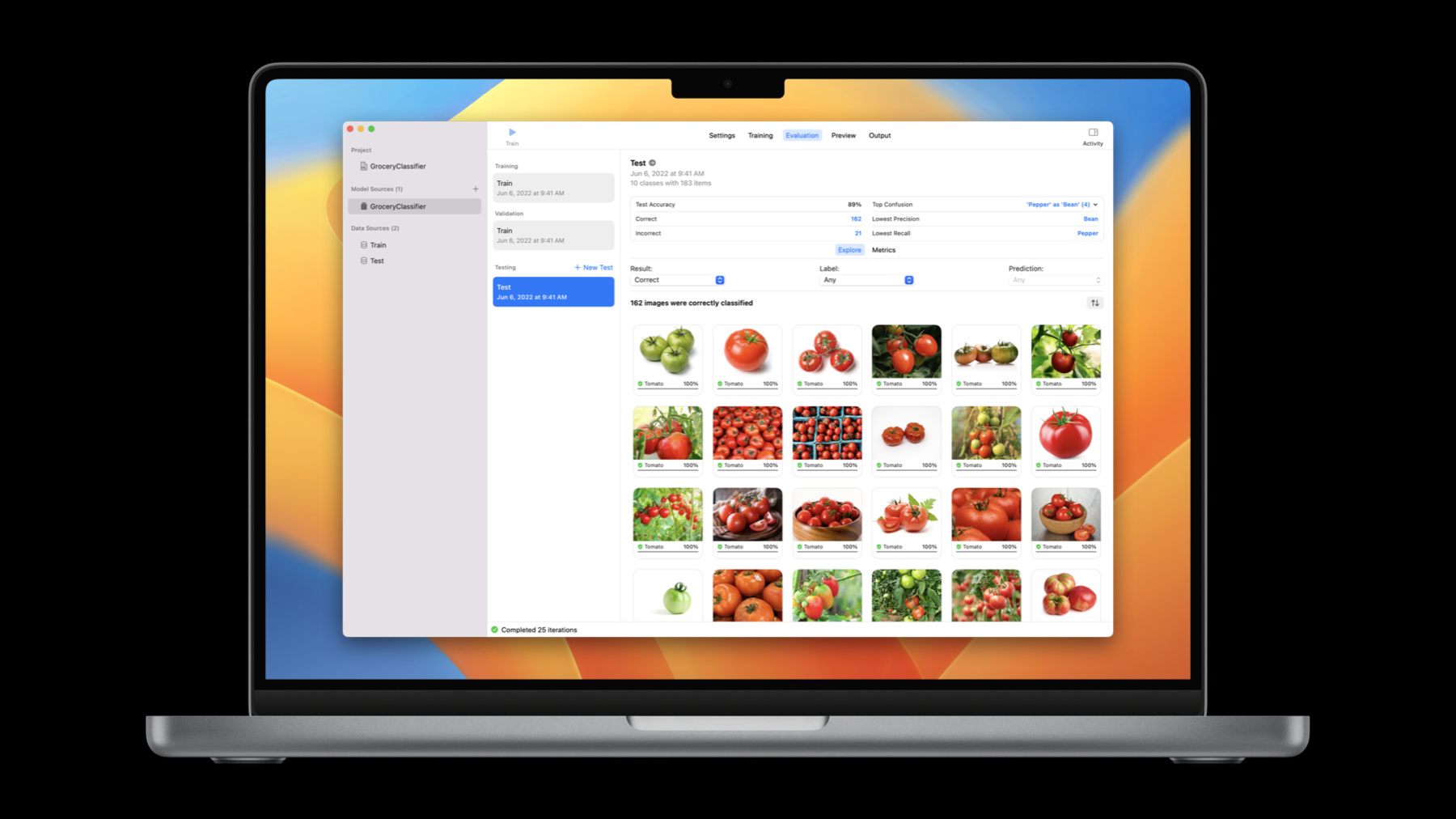
I have already trained my image classifier for 25 iterations. Next, when I click on the Evaluation tab, I can add new test data -- a set of images apart from training data that I had set aside for testing.
I will next click Evaluate to begin testing. After it finishes evaluation, the UI provides details of the results. On the top, there is a high-level summary section which gives a quick sense of test accuracy. Here, the accuracy of this test data is 89 percent. Below in this Metrics tab, a table provides a wealth of metrics for each class. You can adjust what is shown here using these drop-down menus and add additional metrics like false positive and false negative. Let's review one of these classes. How about Tomato? The model classified 29 of the 32 tomato images correctly. It also shows the precision for this class is 91 percent, which means nine percent of the time the model says something is a tomato, it is incorrect. While these numbers and statistics are super useful, it's sometimes even more important to look at them in the context of the data itself. When I click the precision, it takes me to the images that were incorrectly classified as tomato. Here are three of these cases in the test data. For each image, the app displays its thumbnail, the class the model has predicted, and the true label below it. In this first example, while the model classified this as Tomato, it was labeled as Potato. But this sure appears to be a tomato to me. This seems like a case of a mislabeled test data. In fact, all three of these examples seem to be mislabeled. This should be easy to address. I'll make a note to double-check and revisit my test-set labeling. This was clearly an error on my part, but is it the only source of error? I got here by exploring the metrics on a random class of my choice. You may wonder, "Where should I start?" Or, "What should I explore next?" The top-level summary section is here to help you out. The app has selected some of the most important evaluation details that can serve as a great place to start your exploration. Let me restart from the top and review the successful cases. Clicking here, this correct count... Here, we can get a quick glance of all the 162 images the model correctly classified. Next, let me contrast this with a review of all the failures by clicking on the incorrect. There are 21 failures in total.
Here is that mislabeled tomato again. Let me check if there are any other types of errors that can stand out. How about... this one? This image is labeled as Carrot, but the model predicts as Potato. It's hard to tell in this small thumbnail, but let's confirm by clicking on this image to get a better view. Well, this looks like a foot to me. This clearly is not a long, skinny carrot shape I'm used to but can be easily confused as a potato. Perhaps I should consider adding more shape variations to my training data for carrots. Let me make a note of this as well. This time, I will click on the arrow next to the filename to bring me to this image in the Finder.
I will right-click and label this as red, as reminder of it being something I want to revisit in my next round of data collection. Let me continue my exploration from within this expanded view. Note that this view also shows full prediction results, listing the model's confidence in every class. It also lets me navigate through examples using these left and right arrows. I'll move to another example from here. This is an interesting case. It has multiple vegetables in a single image. It says it's an eggplant and it's true that there are eggplants here but other things as well. I need to think about whether this is an important use case for me to consider in my app. Perhaps the UI can guide my users to make sure they only point to one type of grocery at a time, or if I want to support multiple types, I may want to consider using an object detector -- another template in the app -- rather than the whole image classifier. Coming back to the summary section, let me check out this line about the top confusion. Here it says it's 'Pepper' as 'Bean'. Let's click to explore this case. Four images labeled as peppers are incorrectly classified as beans. These look like spicy peppers to me, but I guess they are green like beans as well. I wonder if the model is having trouble with peppers in general. Let me switch this query option from Incorrect to Correct... ...to contrast these failures to correctly classified peppers. It correctly classified 32 images; however, I do notice that most of these are bell peppers. I should check my training data to make sure I have a good representation of multiple peppers as well. This quick exploration was a great reminder of how important the quantity, quality, and variety of training and test data are for machine learning. In a matter of a few minutes, the app helped me visually identify some issues with labeling and representation. I need to make some tweaks to my training data and see if it fixes the issues we saw. It also revealed something I hadn't considered before: what happens if a user captures multiple vegetables in a single photo? I need to think about my app design some more. All of this exploration was possible because I had a collection of labeled data to evaluate. But what if I have unlabeled examples I want to quickly test, or consider whether or not I should explore more camera angles or lighting conditions? Here is where the Preview tab can help. I can drag a few examples my colleague just sent to me here and see how well it does.
Or I can even test this live, using my iPhone as the Continuity Camera.
As I point to these actual vegetables, the model is able to correctly classify them live. Here, this is a pepper and a tomato. To recap, you can now dive deeper into a trained model's behavior on any labeled dataset. The Evaluation pane provides a detailed metric summary with its extended options. A new Explore tab provides options which lets you filter and visualize the test evaluation results along with the associated data in a new interactive UI, currently available for image classifier, hand pose classifier, and object detection templates. Live preview enables immediate feedback. It's expanded to image classifier, hand action classifier, and body action classifier templates. We have also extended the feature to allow you to select from any attached webcam and we also support Continuity Cameras on macOS Ventura. That's a quick summary of what's new in the Create ML app. Let's shift over to discuss what's new in the Create ML framework.
The Create ML framework is available on macOS, iOS, and iPadOS. This year, we are expanding some of its support to tvOS 16. The programmatic interface not only lets you automate model creation at development time but also opens up many opportunities to build dynamic features that learn directly from users' input or on-device behavior, providing personalized and adaptive experiences while preserving user privacy. Note that task support does differ per platform. For example, while tabular classifiers and regressors are available everywhere, some of the tasks with larger data and computation requirements, such as those involving video, require macOS. One common question you may have is, "What if I can't map my idea into one of these Create ML's predefined tasks?" To help answer this question, we are introducing a new member to the Create ML family: Create ML Components. Create ML Components exposes the underlying building blocks of Create ML. It allows you to combine them together to create pipelines and models customized to your use case. I highly recommend you checking out these sessions to learn more. In "Get to know Create ML Components," you will learn about the building blocks and how they can be composed together. In "Compose advanced models with Create ML Components," you dive deeper into using async temporal components and customizing training. There are endless capabilities; let me showcase one that I am personally excited about: action repetition counting. When I am not working, most likely you'll find me dancing. I'm a professionally trained Indian classical dance Kathak artist. To improve my form, I often rely on repeatedly practicing my routines. As a choreographer/teacher, I would like my performers to practice steps for certain counts and submit them to me. The new repetition counting capabilities in Create ML can help me actually do that! Here, this a chakkar -- twirl -- an integral part of Kathak dance.
I would like to practice this for certain counts daily to build my form and my stamina. I have an iOS app built using Create ML that counts my moves. Let's try it in action.
As I take my chakkars, the count increases to correspond to it. Here, I have done five chakkars, and the count reflects exactly that. Next, let's try a different small routine that consist of right- and left-side movements. The counter counts them as one.
Here, the count shows three. Let me try another quick one-side arm movement.
That's four. When combined with Action Classification, this will allow you to count and categorize repetitive actions at the same time. Repetition counting is available as a runtime API. It requires no training data, and adding this functionality to your app can be just a few lines of code. Its implementation is based on a pretrained model designed to be class-agnostic. Meaning, while it works on fitness or dance actions, such as jumping jacks, squats, twirls, chakkars, it's also applicable to a wide variety of full-body repetitive actions. You can find out more about this model and potential use case by checking out the sample code and the article linked to this session. So that's a quick overview of what's new in Create ML. Interactive evaluation and live previews in the Create ML app lets you dive deeper into understanding the models you train. The Create ML framework adds tvOS support, repetition counting, and has expanded to give you access to a rich set of underlying components to help you build models highly customized to your app needs. Thank you, and I hope you enjoyed all these exciting new features, and we can't wait to see what you do with them! ♪
-