-
Scale compute workloads across Apple GPUs
Discover how you can create compute workloads that scale efficiently across Apple GPUs. Learn how to saturate the GPU by improving your work distribution, minimize GPU timeline gaps with effective pipelining and concurrent dispatches, and use atomic operations effectively. We'll also take you through the latest counters and tools in Xcode and Instruments that can help you optimize spatial and temporal memory access patterns.
Resources
Related Videos
WWDC23
WWDC22
Tech Talks
-
Search this video…
- Hello and welcome. My name is Marco Giordano, and I'm with the GPU Software Engineering team here at Apple. In this session I'll talk to you about how to scale workloads across Apple M1 GPUs. If you work on complex compute workloads and want to know how to take full advantage of Apple silicon hardware and achieve great scaling, this talk is the one for you. I will start by discussing compute scalability concepts and how applications can naturally scale performance across the M1 GPU family. And then, I'll share step-by-step "how-tos" and talk about what tools are available to maximize compute scaling for your workloads. Let's start by understanding what scalability is and why it is important for your workload.
The Apple M1 GPU was designed from the ground up to scale and to let your workload achieve excellent performance across the entire SOC family. The same GPU supporting all Metal 3 features scales from your 8-core iPad all the way to your 64-core Mac Studio.
To take advantage of the high level of scaling, having an app optimized for M1 is a great starting point. Many prominent pro apps have already been optimized for Apple M1 and have been experiencing excellent scaling across all devices.
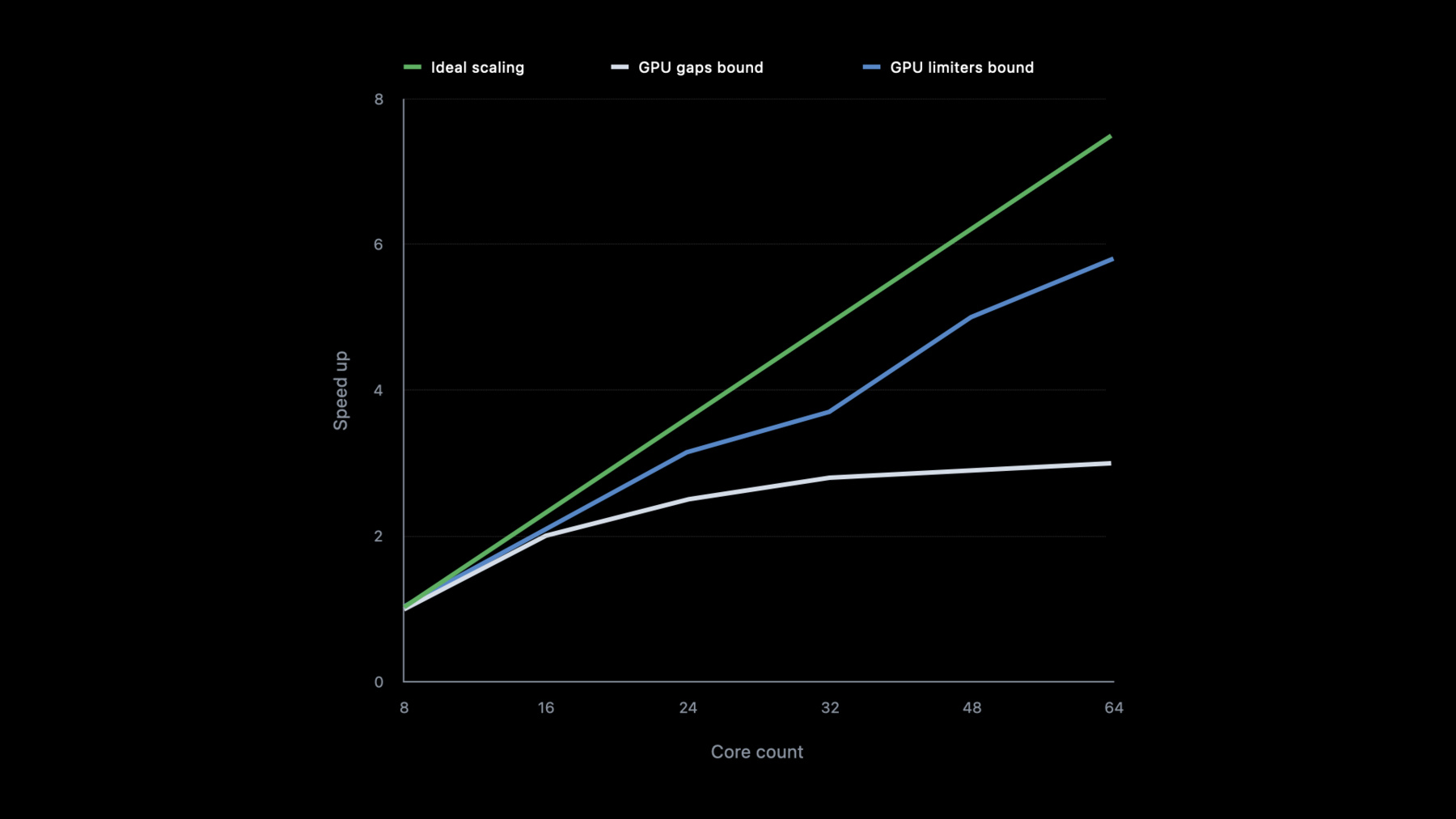
For example, here we have Affinity Photo and DaVinci Resolve-- photo and video editors from the post-production industry. These apps are achieving great scaling. Let's define what scalability really means and how you can achieve "ideal" scaling. GPU workload scalability is the capacity to improve performance with an increased number of GPU cores. The chart on the right shows application speed-up with an increasing GPU cores count. Linear proportion improvement is considered ideal.
However, while working on your app, you might notice a type of scaling which hits a plateau and scales with diminishing returns, or doesn't scale at all due to gaps in the GPU timeline.
Or you might see another type scaling where the performance improves but not uniformly across the stack where the workload is hitting some GPU limiters, like here, between 24 to 32 or 48 to 64 cores.
Your goal is to get as close as possible to linear scaling, and I will show you the tools and techniques to identify bottlenecks and achieve the result you want.
In the next section I will discuss the approaches to maximize GPU scaling. For every workload, you should first identify where the bottleneck is. Workloads can be limited either by computation or bandwidth. During the optimization process, you might end up bouncing between one and the other. If you are computational-bound, you might try to shift some of the load to leverage memory to reduce computation, or vice versa. Bottlenecks can shift when you scale up. One good solution could be using Apple frameworks like MPS or MPSGraph. if you can leverage their primitives, we made sure every compute kernel runs best on all the hardware. However, you can't replace everything with MPS, so it is critical to profile and understand your workload.
I will first cover three items that can help minimize GPU gaps: Improve your work distribution, eliminate GPU timeline gaps, and atomics operation considerations.
Then I will explain how to optimize for GPU limiters by first investigating the effect of compute grid shapes and memory layouts of your workload and finally by looking at a specific example in Blender Cycles. Start by focusing on minimizing GPU gaps. This kind of scaling can be the result of the GPU not being fully utilized, with gaps in the GPU timeline where the hardware is idle.
Let's see if we can improve scaling by investigating work distribution.
Small workloads usually do not saturate the whole GPU, and kernel synchronization has its cost, so both can prevent proper scaling. It is very important to understand how the workload gets mapped to the hardware, so let's talk about it.
A workload is dispatched in the form of a 3D grid of threadgroups. Threadgroups are uniformly distributed to the GPU cores and have access to threadgroup memory, which is limited in size, but very fast, local to the GPU core.
A single threadgroup is further broken down into SIMD-groups, which are also known as waves or warps in other compute dialects.
Checking the "threadExecutionWidth" on the compute pipeline state object will return the SIMD width, and on all Apple GPUs, it is equal to 32.
Threadgroups can have up to 1024 threads per threadgroup and threads can share up to 32K of threadgroup memory.
To keep the GPU busy, there should be enough work to do on all the GPU cores.
Here is an example of a grid to dispatch. Threadgroups are dispatched to GPU Clusters and distributed among GPU cores.
If there are too few threadgroups, the workload won't fully saturate the machine. Here's how to fix this.
Start by computing how many threads the workload produces and roughly see if the dispatch will saturate the whole machine.
For relatively complex kernels, 1K to 2K concurrent threads per shader core is considered a very good occupancy, so take 1 to 2K threads per GPU core as a rule of thumb. Now you can compute if you have enough work to fully saturate the hardware. The table here shows the lowest recommended number of threads to saturate different SOCs.
Another thing to consider would be avoiding using unnecessarily large threadgroup sizes. Making threadgroups smaller will map the load to the hardware more uniformly. Using larger threadgroups might prevent a more uniform distribution, leading to imbalance in the GPU cores.
It's best to use the smallest multiple of the SIMD width that maps well to your workload.
By using smaller threadgroups, the GPU has more opportunities to better balance its workload.
Please always check your kernel runtime performance with Xcode or Instruments GPU Tools.
In this GPU capture, for example, there is a kernel performing some computation. Occupancy is pretty low, which is unexpected. The compiler statistics show that max theoretical occupancy, which is new in Xcode 14, is 100%. This indicates there might not be enough threads--and indeed, we can see the algorithms starts to dispatch fewer and fewer threads, not saturating the machine anymore.
Low occupancy might have several other causes. To get all the details, check the Metal Compute on MacBook Pro Tech talk.
OK, now that workload is correctly distributed, it's time to make sure the GPU is always busy.
Under-utilizing the GPU never leads to ideal scaling, and the worst case of under-utilizing is keeping it idle. The GPU can be idle because of GPU timeline gaps.
Consider this example. Here is a workload using only 50% of the GPU due to work serialization between CPU and GPU. In this case, overall task duration is the sum of CPU and GPU work with no overlaps.
Doubling the GPU cores makes the GPU track complete faster, but the CPU track is not affected. Overall performance increases only by 33%, far from ideal scaling.
If the GPU cores are doubled again, the workload is even faster on the GPU, but overall latency is reduced by only 60% compared to the original time! So GPU cores scaling brings diminishing returns in such cases. This is far from ideal. Let's fix it! This Instrument trace from a M1 pro shows big GPU timeline gaps, and this will clearly prevent proper scaling.
On M1 Ultra the same workload is indeed a bit faster, but the GPU idle time became higher and the workload is not scaling well. The big gaps are caused by CPU synchronization using the waitUntilCompleted on the command buffer.
After changing the waiting logic and removing serialization, the GPU became fully utilized, which is great.
Comparing the workload scaling before and after, we can state that the scaling became much closer to the ideal scaling.
In the previous example, it was possible to remove CPU/GPU synchronization altogether, however this is not always the case, due to your application nature. There are other approaches you can take to reduce idle time. Use MTLSharedEvents to signal the CPU, pipeline more work, consider using GPU-driven encoding, and using concurrent dispatches. So let's discuss those approaches to minimize GPU timeline gaps. Some of them might fit your workflow.
Waiting on the CPU for GPU completion leads to not ideal scaling. If your application is using WaitUntilCompleted, you might want to try to use MTLSharedEvents instead.
MTLSharedEvents have lower overhead and can help you reduce the timeline gaps. The next thing to consider is pipelining the workload.
If the algorithm has the data necessary for the next batch to work on, it's possible to encode one or more batches in advance before waiting on the MTLSharedEvents. By doing so, the GPU will not become drained and will always have work to process.
If work can't be encoded in advance on the same queue, consider using a second queue to overlap work. Using multiple queues allows you to submit independent work, and they do not stall the other submission thread when waiting on an event. This way, the GPU has the chance to keep receiving and processing work.
In some cases, an algorithm can encode work directly from the GPU.
Using indirect command buffer, you can move the encoding of the next batch directly on the GPU, avoiding any need for synchronization. For more details about indirect command buffers, please check "Modern Rendering with Metal." The workload now removes or minimizes expensive synchronizations between CPU and GPU as much as possible. But even with a busy GPU timeline, scaling challenges may still exist. Let's investigate. This graph is from an image processing workload where images are processed 1 frame at a time. A lot of back-to-back compute serial dispatches can also limit scaling. The GPU is busy, but kernel synchronization has a cost and additionally, every dispatch has a small ramp up where the threadgroups are being distributed and not yet saturating the cores. Likewise, when threadgroups finish and retire, there might not be enough work to fully saturate the cores anymore. In this situation, the advice is to overlap independent work when possible. Let's see a visual example. Here we have a workload processing two images, one after the other. Normally, kernels need to synchronize between each other. However, this is not the only way to schedule work. You can interleave independent work of two images using concurrent dispatches. Here the driver is able to interleave different work, thanks to concurrent dispatches. We can see that the two kernels that previously were back-to-back are now separated by some independent work. However, when you use MTLDispatchTypeConcurrent, barriers must be put in manually. Concurrent dispatches enable the driver to pack the work more tightly, hiding most of the synchronization cost between dependent kernels, as well as fill the ramp up and tail end of the various kernels. This optimization greatly improved the workload performance and scaling when moving from M1 Max to M1 Ultra. The workload runs 30% faster with two images interleaved, 70% faster with 3 images in parallel, compared to the previous scaling.
It's important to carefully consider atomic operations that kernels are doing. Let's make sure it is made in the most efficient way. Atomic operation allows reading and writing data from multiple threads in a safe manner. Global atomics are coherent across the whole GPU. When many threads attempt to read and write the same global value, this leads to contention. Increasing numbers of GPU cores doesn't help and in fact leads to more contention. Let's investigate how you can improve atomics behavior in an algorithm with an example.
Here is a reduction algorithm, where all of the values in a buffer will be summed up together. The simplest approach is to perform an atomic add operation per thread in main memory. However, this is not ideal because that puts a great level of pressure on a single value in main memory, effectively serializing each memory write.
There are two things that the hardware offers to help with atomic memory contention: Simd-group instruction and threadgroup atomics.
SIMD instructions like prefix_exlusive sum and simd_min and many more allow to do operations and exchange memory between registers in a SIMD-group without round trip to memory. Threadgroup atomics are fulfilled by the threadgroup memory. Each GPU core has its own threadgroup memory allowing to scale with the number of GPU cores. Let's see how these two features can help you improve your workload.
Here we have the same reduction problem, but this time it start using a SIMD-group instruction, an inclusive memory sum. Such operation will leave the sum of all the numbers in the SIMD-group in the last thread. The last thread from each SIMD-group can then perform a single atomic add in threadgroup memory to reduce all SIMD-groups to a single value in threadgroup memory. In this way, using SIMD-group instruction and threadgroup memory, a whole threadgroup was reduced without touching main memory at all. Each group will be able to reduce independently and in parallel.
Now that each threadgroup has been reduced to a single value, one thread per threadgroup can perform a single atomic in main memory. Not only this requires only one atomic per threadgroup, but since threadgroups complete at different times, it scatters atomics over time, reducing memory contention even further. To recap, to maximize atomics effectiveness, try to leverage memory locality, try to use SIMD-group operation, as well as to leverage threadgroup memory atomics. All this should greatly help reduce atomic operation pressure that prevents scaling.
Now that GPU gaps are fixed, it's time to see if the scaling is closer to ideal. GPU Limiters in Xcode and Metal System Trace help to optimize any bottlenecks and inefficiencies in GPU cores execution pipeline. For example, inefficient memory access patterns always cause high Last Level Cache or Memory Management Unit, or MMU limiters, and pretty low utilizations. The first thing to address is the way to tune threadgroups and memory layout. The key in reducing memory span and divergence is to have a clear understanding of the workload memory access pattern, both spatially and temporally. Once that's understood, there are two possible tuning directions: Re-organize the data layout to improve data access locality, or tune the access pattern to better match the data layout and improve memory and cache locality. Let's see an example.
Here it is a memory buffer where the data is laid out horizontally, one row after the other. However, when the compute kernel is dispatched, it is common to have a 2D like pattern with square threadgroups being distributed, which is quite spatially localized. This access pattern and data layout is not great for data locality.
For example, when the first SIMD-group access the data, the requests are packed in a cache lines. Most of the cache line won't be used, however still occupying space in the cache. Re-arrange the data to fit the access pattern better, where, for example, instead of spanning the whole row, it is localized into stripes.
With this new memory layout, a threadgroup will be able to utilize most of the data that will be requested in a cache line, reducing divergence and improving cache efficiency.
The other option is to change how the 3D grid is dispatched to better fit the current data layout. Try to play with the threadgroup size to create groups that map better to your memory layout, like a more rectangular shape, for example. In this case, the access pattern is aligned with the memory layout, giving a much higher cache efficiency. You might need to experiment to find the best fit for your workload. Sometimes you might need to make trade-offs, sacrifice thread divergence for memory locality, or vice versa, change your data layout, grid dispatch, or a combination of them all. Every workload and access pattern is different.
Now that you're aware of ways to improve memory locality, let's see a more concrete example in Blender Cycles.
Cycles is Blender's physically-based path tracer for production rendering. It is designed to provide physically based results out-of-the-box, with artistic control and flexible shading nodes for production needs.
This Instrument trace clearly shows low Read Bandwidth, high Top GPU Limiter, high Cache Limiter and low Last Level Cache Utilization.
Keeping bandwidth and MMU limiters in control is important for scaling. If your Top limiter is the Last Level Cache or MMU, you need to reduce your memory span and maximize data locality. Let's see an example.
Cycles use sorting of data to try to reduce divergence. It does that by sorting the ray hits by material type. This is great to reduce thread divergence, but it increases spatial memory divergence, resulting in a high MMU Limiter. To help with this, we experimented with partitioning the memory range before sorting to increase data locality. Let's visualize it. When rays are shot into the scene to simulate light traveling, they hit objects and data is collected into buffers. At the point of intersection we know many things-- the material type that was hit, like glass, metal and so on, the intersection position, the ray, and more. For simplicity, let's focus on the material type only. Here are the materials in a buffer in memory.
Since a lot of data is gathered per ray hit, the memory buffer can become quite large. To avoid moving a lot of memory around, populate a list of indices and sort those instead. After the sort, the indices for the same material type are now packed closed together. SIMD-groups can start loading the indices and process the materials. The SIMD-group will use the index to load the corresponding data in the original buffer.
However, the SIMD-group would be reading across the whole memory span, putting pressure on the MMU. Let's investigate the new approach. The memory range is partitioned in an idealized partition that simply won't let indices from different partition mix. When sorting, it is apparent that the range of data accessed is contained inside the partition instead of spanning the full memory range like before. It is a trade-off and balance between thread divergence and memory divergence. The number of partitions and size that is ideal is highly dependent on the workload. You might have to experiment to see which one works best. Let's take another Metal System Trace and let see if the workload improved. Here we see the limiters and utilizations for the optimized version. The Top Performance limiter went down, as well as Last Level Cache limiter. As a result, bandwidth and shader runtime substantially improved. Let's see how much. Top limiter and LLC limiter reduced by around 20%. That means data flow is more efficient. GPU Read bandwidth increased significantly, allowing to push more data to the GPU cores.
Overall, increasing memory locality with this experiment improved performance between 10 to 30%, depending on the scene. This was just an example of many ways you can try to improve memory access pattern. Keep experimenting and optimizing for the Top Performance Limiter. The GPU tools have more useful counters to tune for.
Xcode has a new theoretical occupancy in the compiler statistic window. Both Xcode and Instruments now have several MMU related limiters and counters, specifically a new MMU Limiter, MMU Utilization Counter, and MMU TLB Miss Rate Counter.
I have covered a lot of ground today. I discussed GPU scalability and how bottlenecks can shift when scaling up, and how the tools can help you find and fix scalability issues. I also discussed how you might need to experiment and make trade-offs to get the best result for your application. I am looking forward to seeing all your great apps scale amazingly well on Apple silicon. Thank you for watching.
-