-
Optimize your Core ML usage
Learn how Core ML works with the CPU, GPU, and Neural Engine to power on-device, privacy-preserving machine learning experiences for your apps. We'll explore the latest tools for understanding and maximizing the performance of your models. We'll also show you how to generate reports to easily understand your model performance characteristics, help you gain insight into your models with the Core ML Instrument, and take you through API enhancements to further optimize Core ML integration in your apps.
To get the most out of this session, be sure to watch “Tune your Core ML models” from WWDC21.Resources
Related Videos
WWDC23
WWDC22
-
Search this video…
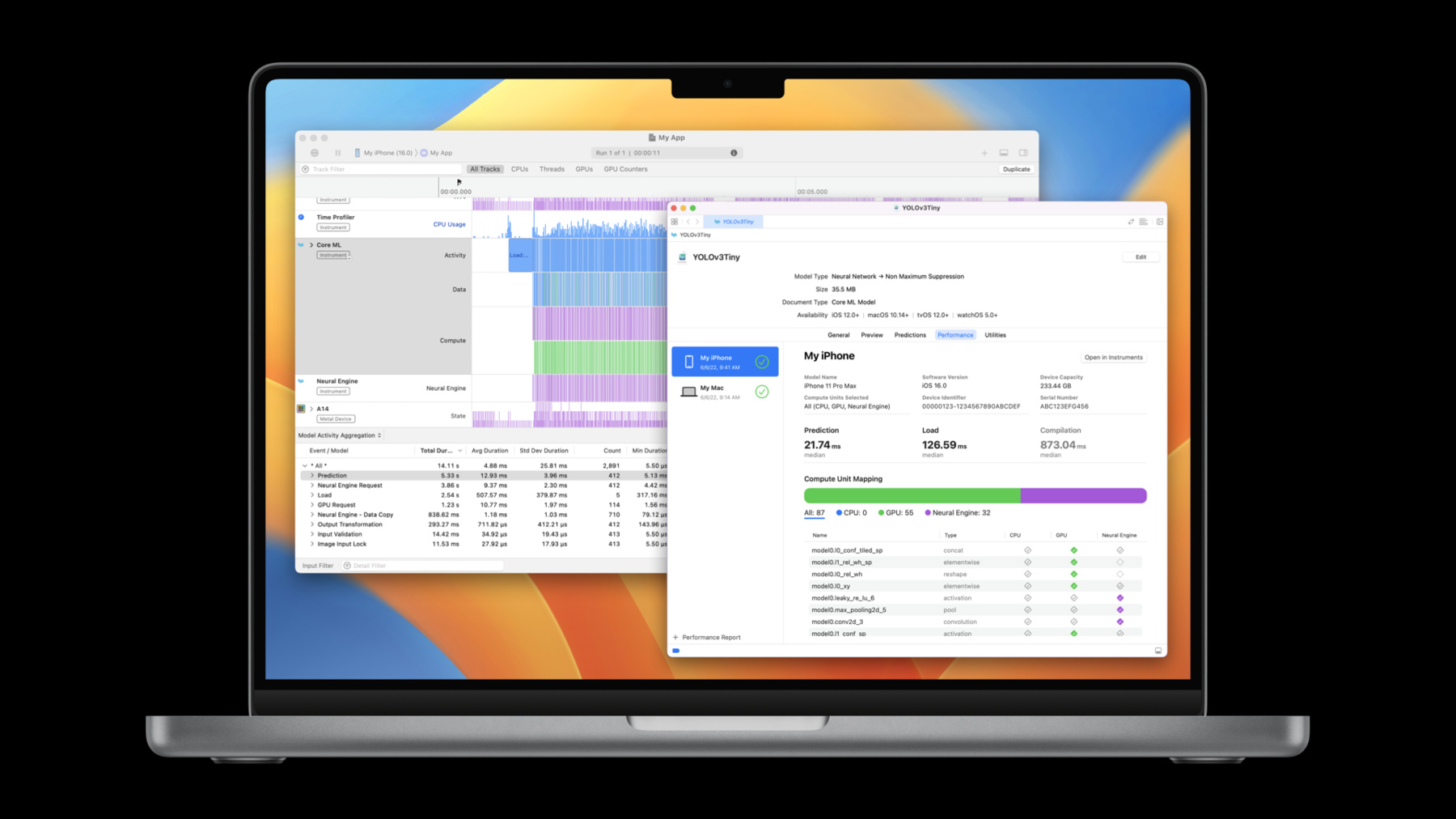
♪ Mellow instrumental hip-hop music ♪ ♪ Hi, my name is Ben, and I'm an engineer on the Core ML team. Today I'm going to show some of the exciting new features being added to Core ML. The focus of these features is to help you optimize your Core ML usage. In this session, I'll go over performance tools that are now available to give you the information you need to understand and optimize your model's performance when using Core ML. Then I'll go over some enhanced APIs which will enable you to make those optimizations. And lastly, I'll give an overview of some additional Core ML capabilities and integration options. Let me begin with the performance tools. To give some background, I'll start by summarizing the standard workflow when using Core ML within your app. The first step is to choose your model. This may be done in a variety of ways, such as using Core ML tools to convert a PyTorch or TensorFlow model to Core ML format, using an already-existing Core ML model, or using Create ML to train and export your model. For more details on model conversion or to learn about Create ML, I recommend checking out these sessions. The next step is to integrate that model into your app. This involves bundling the model with your application and using the Core ML APIs to load and run inference on that model during your app's execution. The last step is to optimize the way you use Core ML. First, I'll go over choosing a model. There are many aspects of a model that you may want to consider when deciding if you should use that model within your app. You also may have multiple candidates of models you'd like to select from, but how do you decide which one to use? You need to have a model whose functionality will match the requirements of the feature you wish to enable. This includes understanding the model's accuracy as well as its performance. A great way to learn about a Core ML model is by opening it in Xcode. Just double-click on any model, and it will bring up the following. At the top, you'll find the model type, its size, and the operating system requirements. In the General tab, it shows additional details captured in the model's metadata, its compute and storage precision, and info, such as class labels that it can predict. The Preview tab is for testing out your model by providing example inputs and seeing what it predicts. The Predictions tab displays the model's inputs and outputs, as well as the types and sizes that Core ML will expect at runtime. And finally, the Utilities tab can help with model encryption and deployment tasks. Overall, these views give you a quick overview of your model's functionality and preview of its accuracy. But what about your model's performance? The cost of loading a model, the amount of time a single prediction takes, or what hardware it utilizes, may be critical factors for your use case. You may have hard targets related to real-time streaming data constraints or need to make key design decisions around user interface depending on perceived latency. One way to get insight into the model's performance is to do an initial integration into your app or by creating a small prototype which you can instrument and measure. And since performance is hardware dependent, you would likely want to do these measurements on a variety of supported hardware. Xcode and Core ML can now help you with this task even before writing a single line of code. Core ML now allows you to create performance reports. Let me show you.
I now have the Xcode model viewer open for the YOLOv3 object detection model. Between the Predictions and Utilities tabs, there is now a Performance tab. To generate a performance report, I'll select the plus icon at the bottom left, select the device I'd like to run on -- which is my iPhone -- click next, then select which compute units I'd like Core ML to use. I'm going to leave it on All, to allow Core ML to optimize for latency with all available compute units. Now I'll finish by pressing Run Test. To ensure the test can run, make sure the selected device is unlocked. It shows a spinning icon while the performance report is being generated. To create the report, the model is sent over to the device, then there are several iterations of compile, load, and predictions which are run with the model. Once those are complete, the metrics in the performance report are calculated. Now it's run the model on my iPhone, and it displays the performance report. At the top, it shows some details about the device where the test was run as well as which compute units were selected. Next it shows statistics about the run. The median prediction time was 22.19 milliseconds and the median load time was about 400 ms. Also, if you plan to compile your model on-device, this shows the compilation time was about 940 ms. A prediction time of around 22 ms tells me that this model can support about 45 frames per second if I want to run it in real time.
Since this model contains a neural network, there's a layer view displayed towards the bottom of the performance report. This shows the name and type of all of the layers, as well as which compute unit each layer ran on. A filled-in checkmark means that the layer was executed on that compute unit. An unfilled checkmark means that the layer is supported on that compute unit, but Core ML did not choose to run it there. And an empty diamond means that the layer is not supported on that compute unit. In this case, 54 layers were run on the GPU, and 32 layers were run on the Neural Engine. You can also filter the layers by a compute unit by clicking on it.
That was how you can use Xcode 14 to generate performance reports for your Core ML models. This was shown for running on an iPhone, but it will allow you to test on multiple operating system and hardware combinations, without having to write a single line of code. Now that you've chosen your model, the next step is to integrate this model into your app. This involves bundling the model with your app and making use of Core ML APIs to load the model and make predictions with it. In this case, I've built an app that uses Core ML style transfer models to perform style transfer on frames from a live camera session. It's working properly; however, the frame rate is slower than I'd expect, and I'd like to understand why. This is where you'd move on to step three, which is to optimize your Core ML usage. Generating a performance report can show the performance a model is capable of achieving in a stand-alone environment; however, you also need a way to profile the performance of a model that's running live in your app. For this, you can now use the Core ML Instrument found in the Instruments app in Xcode 14. This Instrument allows you to visualize the performance of your model when it runs live in your app, and helps you identify potential performance issues. Let me show how it can be used. So I'm in Xcode with my style transfer app workspace open, and I'm ready to profile the app. I'll force-click on the Run button and select Profile.
This will install the latest version of the code on my device and open Instruments for me with my targeted device and app selected. Since I want to profile my Core ML usage, I'm going to select the Core ML template. This template includes the Core ML Instrument, as well as several other useful Instruments which will help you profile your Core ML usage. To capture a trace, I'll simply press Record.
The app is now running on my iPhone. I will let it run for a few seconds and use a few different styles. And now I'll end the trace by pressing the Stop button. Now I have my Instruments trace. I'm going to focus on the Core ML Instrument. The Core ML Instrument shows all of the Core ML events that were captured in the trace. The initial view groups all of the events into three lanes: Activity, Data, and Compute. The Activity lane shows top-level Core ML events which have a one-to-one relationship with the actual Core ML APIs that you would call directly, such as loads and predictions. The Data lane shows events in which Core ML is performing data checks or data transformations to make sure that it can safely work with the model's inputs and outputs. The Compute lane shows when Core ML sends compute requests to specific compute units, such as the Neural Engine, or the GPU. You can also select the Ungrouped view where there is an individual lane for each event type. At the bottom, there's the Model Activity Aggregation view. This view provides aggregate statistics for all of the events displayed in the trace. For example, in this trace, the average model load took 17.17 ms, and the average prediction took 7.2 ms. Another note is that it can sort the events by duration. Here, the list is telling me that more time is being spent loading the model than actually making predictions with it, at a total of 6.41 seconds of loads, compared to only 2.69 seconds of predictions. Perhaps this has something to with the low frame rate. Let me try to find where all of these loads are coming from.
I am noticing that I am reloading my Core ML model prior to calling each prediction. This is generally not good practice as I can just load the model once and hold it in memory. I'm going to jump back into my code and try to fix this.
I found the area of code where I load my model. The issue here is that this is a computed properly, which means that each time I reference the styleTransferModel variable, it will recompute the property, which means reloading the model, in this case. I can quickly fix this by changing this to be a lazy variable.
Now I'll reprofile the app to check if this has fixed the repeated loads issue.
I'll once again select the Core ML template and capture a trace. This is much more in line with what I'd expect. The count column tells me that there are five load events total, which matches the number of styles I used in the app, and the total duration of loads is much smaller than the total duration of predictions. Also, as I scroll through... ...it correctly shows repeated prediction events without loads in between each one.
Another note is that so far, I've only looked at the views that show all Core ML model activity. In this app, there is one Core ML model per style, so I may want to breakdown the Core ML activity by model. The Instrument makes this easy to do. In the main graph, you can click the arrow at the top left, and it will make one subtrack for each model used in the trace. Here it displays all of the different style transfer models that were used. The Aggregation view also offers similar functionality by allowing you to break down the statistics by model.
Next I'd like to dive into a prediction on one of my models to get a better idea of how it's being run. I'll look deeper into the Watercolor model.
In this prediction, the Compute lane is telling me that my model was run on a combination of the Neural Engine and the GPU. Core ML is sending these compute requests asynchronously, so if I'm interested to see when these compute units are actively running the model, I can combine the Core ML Instrument with the GPU Instrument and the new Neural Engine Instrument. To do this, I have the three Instruments pinned here.
The Core ML Instrument shows me the entire region where the model ran.
And within this region, the Neural Engine Instrument shows the compute first running on the Neural Engine, then the GPU Instrument shows the model was handed off from the Neural Engine to finish running on the GPU. This gives me a better idea of how my model is actually being executed on the hardware. To recap, I used the Core ML Instrument in Xcode 14 to learn about my model's performance when running live in my app. I then identified an issue in which I was too frequently reloading my model. I fixed the issue in my code, reprofiled the application, and verified that the issue had been fixed. I was also able to combine the Core ML, GPU, and new Neural Engine Instrument to get more details on how my model was actually run on different compute units. That was an overview of the new tools to help you understand performance. Next, I'll go over some enhanced APIs that can help optimize that performance. Let me start by going over how Core ML handles model inputs and outputs. When you create a Core ML model, that model has a set of input and output features, each with a type and size. At runtime, you use Core ML APIs to provide inputs that conform with the model's interface and get outputs after running inference. Let me focus on images and MultiArrays in a bit more detail. For images, Core ML supports 8-bit grayscale and 32-bit color images with 8 bits per component. And for multidimensional arrays, Core ML supports Int32, Double, and Float32 as the scalar types. If your app is already working with these types, it's simply a matter of connecting them to the model. However, sometimes your types may differ. Let me show an example. I'd like to add a new filter to my image processing and style app. This filter works to sharpen images by operating on a single-channel image. My app has some pre- and post-processing operations on the GPU and represents this single channel in Float16 precision. To do this, I used coremltools to convert an image-sharpening torch model to Core ML format as shown here. The model was set up to use Float16 precision computation. Also, it takes image inputs and produces image outputs. I got a model that looks like this. Note that it takes grayscale images which are 8-bit for Core ML. To make this work, I had to write some code to downcast my input from OneComponent16Half to OneComponent8 and then upcast the output from OneComponent8 to OneComponent16Half. However, this isn't the whole story. Since the model was set up to perform computation in Float16 precision, at some point, Core ML needs to convert these 8-bit inputs to Float16. It does the conversion efficiently, but when looking at an Instruments trace with the app running, it shows this. Notice the data steps Core ML is performing before and after Neural Engine computation. When zooming in on the Data lane, it shows Core ML is copying data to prepare it for computation on the Neural Engine, which means converting it to Float16, in this case. This seems unfortunate since the original data was already Float16. Ideally, these data transformations can be avoided both in-app and inside Core ML by making the model work directly with Float16 inputs and outputs. Starting in iOS 16 and macOS Ventura, Core ML will have native support for one OneComponent16Half grayscale images, and Float16 MultiArrays. You can create a model that accepts Float16 inputs and outputs by specifying a new color layout for images or a new data type for MultiArrays, while invoking the coremltools convert method. In this case, I'm specifying the input and output of my model to be grayscale Float16 images. Since Float16 support is available starting in iOS 16 and macOS Ventura, these features are only available when the minimum deployment target is specified as iOS 16. This is how the reconverted version of the model looks. Note that the inputs and outputs are marked as Grayscale16Half. With this Float16 support, my app can directly feed Float16 images to Core ML, which will avoid the need for downcasting the inputs and upcasting the outputs in the app. This is how it looks in the code. Since I have my input data in the form of a OneComponent16Half CVPixelBuffer, I can simply send the pixel buffer directly to Core ML. This does not incur any data copy or transformation. I then get a OneComponent16Half CVPixelBuffer as the output. This results in simpler code, and no data transformations required. There's also another cool thing you can do, and that's to ask Core ML to fill your preallocated buffers for outputs instead of having Core ML allocate a new buffer for each prediction. You can do this by allocating an output backing buffer and setting it on the prediction options. For my app, I wrote a function called outputBackingBuffer which returns a OneComponent1 HalfCVPixelBuffer. I then set this on the prediction options, and finally call the prediction method on my model with those prediction options. By specifying output backings, you can gain better control over the buffer management for model outputs. So with those changes made, to recap, here's what was shown in the Instruments trace when using the original version of the model that had 8-bit inputs and outputs. And here's how the final Instruments trace looks after modifying the code to provide IOSurface-backed Float16 buffers to the new Float16 version of the model. The data transformations that were previously shown in the Data lane are now gone, since Core ML no longer needs to perform them. To summarize, Core ML now has end-to-end native support for Float16 data. This means you can provide Float16 inputs to Core ML and have Core ML give you back Float16 outputs. You can also use the new output backing API to have Core ML fill up your preallocated output buffers instead of making new ones. And lastly, we recommend using IOSurface-backed buffers whenever possible, as this allows Core ML to transfer the data between different compute units without data copies by taking advantage of the unified memory. Next, I'll go through a quick tour of some of the additional capabilities being added to Core ML. First is weight compression. Compressing the weights of your model may allow you to achieve similar accuracy while having a smaller model. In iOS 12, Core ML introduced post-training weight compression which allows you to reduce the size of Core ML neural network models. We are now extending 16- and 8-bit support to the ML Program model type, and additionally, introducing a new option to store weights in a sparse representation. With coremltools utilities, you will now be able to quantize, palettize, and sparsify the weights for your ML Program models. Next is a new compute unit option. Core ML always aims to minimize inference latency for the given compute unit preference. Apps can specify this preference by setting the MLModelConfiguration computeUnits property. In addition to the three existing compute unit options, there is now a new one called cpuAndNeuralEngine. This tells Core ML to not dispatch computation on the GPU, which can be helpful when the app uses the GPU for other computation and, hence, prefers Core ML to limit its focus to the CPU and the Neural Engine. Next, we are adding a new way to initialize your Core ML model instance that provides additional flexibility in terms of model serialization. This allows you to encrypt your model data with custom encryption schemes and decrypt it just before loading. With these new APIs, you can compile and load an in-memory Core ML model specification without requiring the compiled model to be on disk. The last update is about Swift packages and how they work with Core ML. Packages are a great way to bundle and distribute reusable code. With Xcode 14, you can include Core ML models in your Swift packages, and now when someone imports your package, your model will just work. Xcode will compile and bundle your Core ML model automatically and create the same code-generation interface you're used to working with. We're excited about this change, as it'll make it a lot easier to distribute your models in the Swift ecosystem. That brings us to the end of this session. Core ML performance reports and Instrument in Xcode 14 are here to help you analyze and optimize the performance of the ML-powered features in your apps. New Float16 support and output backing APIs gives you more control of how data flows in and out of Core ML. Extended support for weight compression can help you minimize the size of your models. And with in-memory models and Swift package support, you have even more options when it comes to how you represent, integrate, and share Core ML models. This was Ben from the Core ML team, and have a great rest of WWDC. ♪
-