-
Explore and manipulate data in Swift with TabularData
Discover how you can use the TabularData framework to load, explore, and manipulate unstructured data in Swift — whether you need to pre-process data for a machine learning task or digest data on-the-fly in your app. Learn how this framework can help you handle large datasets, join multiple tables of data together, and filter data programmatically. We'll also show you how a DataFrame can be used to drive all the data-centric features of your app.
Resources
Related Videos
WWDC22
-
Search this video…
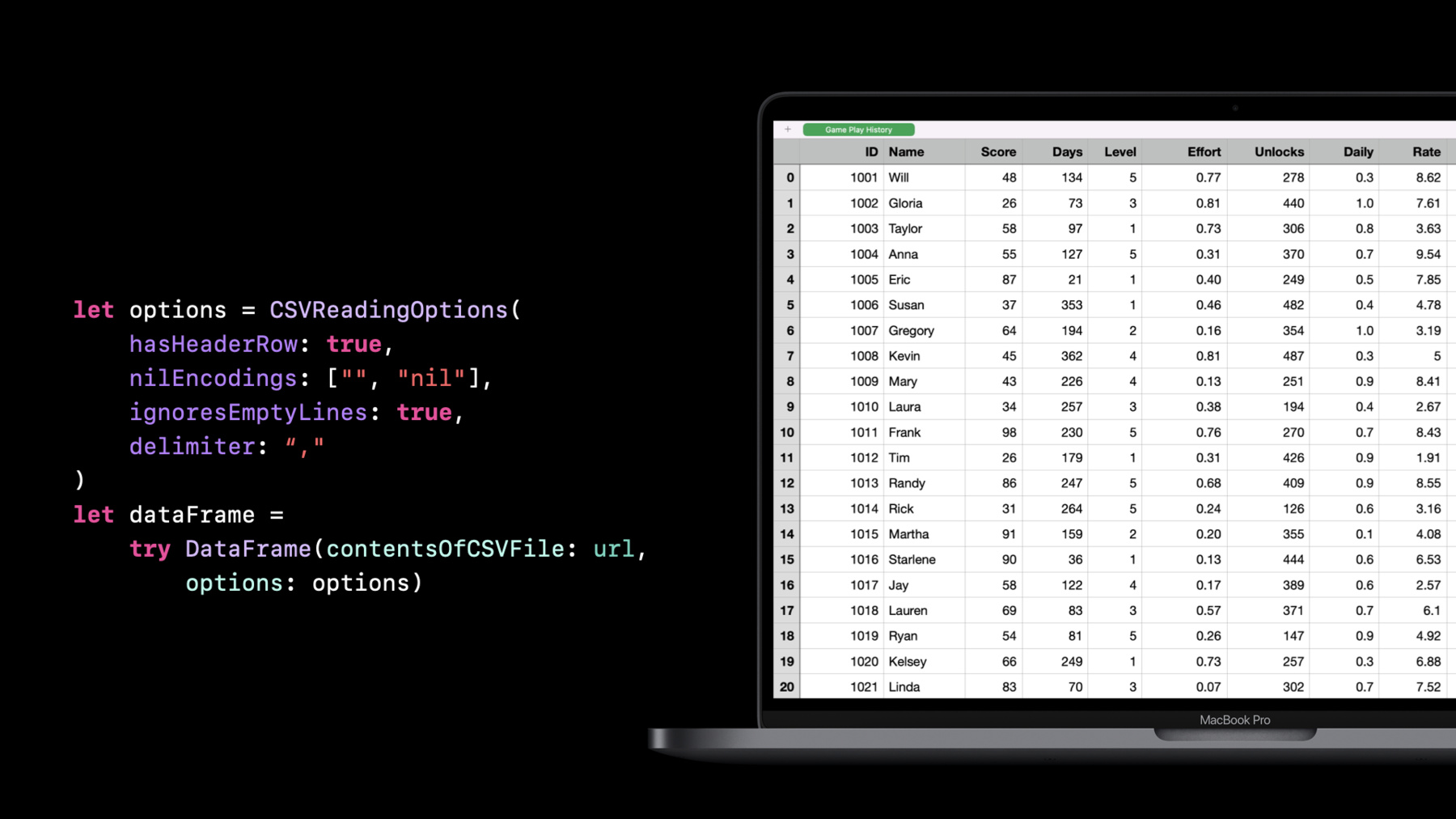
Alejandro Isaza: Hi. I'm Alejandro. Today David and I will introduce TabularData, a new framework for data manipulation and exploration. I'll start with a quick introduction and then we'll talk about data exploration, data transformations, best practices, and end with a recap. Let's jump in. First let me talk about, what is tabular data? In the simplest terms, tabular data is data that is organized in rows and columns, similar to a spreadsheet. But imagine you had hundreds of columns and millions of rows. This is where the TabularData framework comes in. So what is it? It is a brand-new framework we've been working on. It's already available in macOS, iOS, tvOS, and watchOS. It will help you explore and manipulate unstructured data. When I say "unstructured data", I mean data that has not been arranged in a predefined manner. For example, when you download a dataset that doesn't have a technical specification; say, weather data or population statistics. And exploration is the first thing you do when you encounter a new dataset. You want to know what sort of information is there. Things like, what are the values? What are the types? How is the data represented? Are there missing values? And so on. You need to be able to answer these questions to properly understand a dataset and to be able to move to the next step, which is manipulation. Manipulation is where you transform the dataset into a form that is best suited for the problem you are trying to solve. For example, you may want to represent dates as a date type instead of a string, or you may want to combine x and y coordinates into a point type, and so on. The TabularData framework is great for dealing with large datasets. Here are some common use cases. Grouping data according to some criteria; for example, grouping people by age. Joining datasets on common values. For example, joining a table of transactions with the purchaser's information. Splitting or segmenting data for processing incrementally or filtering to a subset of the whole dataset. And building data pipelines; for instance, when doing feature engineering for machine learning. In the context of the framework, a table is known as a DataFrame. A DataFrame contains rows and columns, similar to a spreadsheet. But unlike a spreadsheet, every column can contain only a specific type of value. But this also means that columns can hold any type, even your own custom types. For example, dictionaries, GPS coordinates, or raw audio samples. Know that whenever we show a table representing a DataFrame, or a DataFrame slice, we include an index column on the left. This is relevant for when you need to access rows by data index. Some operations like filter, the data is unchanged, while other operations like sort may change the indices on the resulting data frame. Let's break it down and zoom in on a column. As I mentioned, a column has a specific element type; in this case, Int. It also has a name that must be unique in the data frame. A column is represented by the Column type, which is a collection, just like array. You can refer to a column by name but in most cases, you need the type as well. There is a struct called ColumnID that holds the name and type of a column, and can be used to refer to a specific column. Whenever possible, I recommend using predefined ColumnIDs over string literals to refer to columns. Also note that all columns in a DataFrame must have the same number of elements. But there can always be missing elements, represented as nil values. Similar to Column, there is a Row type. You can access each element of a row by column name or by index. You can think of Row as a proxy. It doesn't actually contain the elements in the row; instead, it's a reference pointing back to a row in the DataFrame. So how do you create a DataFrame? Let me show you. You can create a DataFrame from a dictionary literal or by building one column at a time. This is an example of building from a dictionary literal. Note that when using a dictionary literal, you are constrained to using basic Swift types such as strings, numbers, boolean values, and dates. Also keep in mind that every column must have the same number of elements. A more general way of building a DataFrame is to build one column at a time and then append the columns to the DataFrame. Here's an example. First, I create an empty DataFrame. Then I create a Column. And then I append the column to the DataFrame. I can repeat the process for all the columns, but again, make sure that every column has the same number of elements and that column names are unique. Now that you know what a DataFrame is, let's do some data exploration. The first thing you want to do is load a dataset. TabularData supports reading comma-separated values, CSV, and JSON files. And it's as simple as calling the initializer with a file URL, which will load using all default options. Let's explore some of the options available when loading a CSV. If you have used CSV before, you may know that there are not always commas. The separator may be a tab or a semicolon. Or there may or may not be a header row with the column names. There are also variations of how strings are escaped for special characters and how missing values are represented. TabularData can handle all the variations. In this example, I am specifying that there is no header row, using a custom nil encoding, ignoring empty lines, and using a semicolon delimiter. Please refer to the documentation to see the full set of options as well as the defaults. If you have a larger file, you may want to load only a subset of rows at a time. You can do this with the rows option. For example, this will only load the first 100 rows. Similarly, you can select a subset of the columns. To do this, use the columns argument. Note that this will also let you reorganize the columns.
Let me briefly talk about how type inference works when loading a CSV file. CSV files are all text based. But having every column be of type string is not very convenient. So when loading a CSV file, TabularData will attempt to convert values to numbers, boolean values, and dates before defaulting to string. If you want to force values to a specific type, or want to speed loading up a bit, you can explicitly specify the type of a column. You do this with the types argument. In this example, we're specifying integer type for the id column and string type for the name column. This will not only speed up the loading process, but it will also throw an error if there is a value that cannot be converted to the specified type. This is good because it lets you catch problems early and handle them appropriately instead of ending up with a column of a type that's not what you'd expect, which can lead to crashes later in your app. Lastly, let me mention date parsing. TabularData, by default, will detect and parse dates in ISO8601 format. If your CSV file contains dates in a different format, you will need to specify a custom date parsing strategy. I'll let David talk about this and show you an example when we go into the demo. Now let's switch gears and talk about writing data out. The first and simplest choice is to use Swift's print function. This will generate a nicely printed table in Terminal. The printed output includes the row index, the column names, the column types, the first few rows of data, and the number of rows and columns. It also indicates that not all rows fit on the screen and that not all columns fit on the screen. In this case, there are 10 more columns that aren't displayed. Print is great for exploring and debugging, but obviously not great for storing data. If you want to save the DataFrame as a CSV file, use the writeCSV method. One important thing to note is that writeCSV will use every value's default string conversion. Be careful when using custom types in your columns, because the generated CSV may not be something that you can read back. As a general rule, use only the basic Swift types in your columns when writing to CSV, which may require transforming some of your columns. writeCSV has some options similar to the reading options. They let you customize how the CSV data is written. Here is an example where I'm disabling headers using a custom nil encoding and using a custom delimiter. To access a specific row, you can just use the row subscript. Then you can access a specific column of that row. But whenever possible, you should instead access the column first and then the row. This is how you access a column. In the case of accessing a column by name, you can omit the column: label from the subscript. You can also access a subset of rows. In this case, you get a DataFrame slice. A DataFrame slice is very similar to a DataFrame. It is basically a reference to the original DataFrame In most situations, you don't even need to know whether it's a full DataFrame or a slice. And lastly, you can also select a subset of the columns. This will return a new DataFrame that includes only those columns. You can also select a subset of the rows with the filter method. The result of the filter operation is a DataFrame slice, similar to selecting a range of rows. But unlike a range of rows, filter can return discontiguous rows. You need to be careful when dealing with DataFrame slice indices. Similar to array slices, their indices reflect the indices of the original rows. Specifically, the first index may not be zero, and the next index may not be the current index plus one. As with string indices, you want to use startIndex instead of zero, endIndex instead of count, and index(after:) instead of adding one. Now that I've covered the basics, let's put it into practice by building an app. Finding parking in San Francisco is hard. David and I want to build an iPhone app that shows nearby parking spots on the street. We want to use data published by the city to identify parking meters that are close by where parking is currently allowed. We know there is a dataset but we don't know exactly what it contains. So the first step is going to be exploring the dataset to understand what we have. I'll hand it off to David. David Findlay: Thanks, Alejandro. Hi. I'm David, a framework engineer. In this demo, I'll go through an example of how you can use TabularData to explore a dataset. I'll start by exploring a CSV file of parking policies. The first step is to load the data, which I can do easily by passing the file url into the DataFrame initializer. Note that the initializer is throwable, which I find useful when handling potential parsing errors. Next, with a simple print, I can explore the first few rows and columns.
Loading took a few seconds, and that's because the DataFrame loaded over a million rows and 15 columns into memory. When I'm exploring a dataset for the first time, I don't usually need the whole dataset, so I'll specify a row range when loading the data to speed up my exploration.
Next, I'll take a look at the columns. Notice that two of them are hidden to the right, since they wouldn't fit on the screen. Let me show you how to fix that with formatting options.
Formatting options let me configure how the data is presented. In this case, I'll increase my maximumLineWidth to 250, reduce my column width to 15, and reduce the rows to five to prevent scrolling through the printed result. Then I can simply add the formattingOptions to my print statement using the description method.
Great! Now that I can explore all of my columns, I'll pick a few interesting ones to keep. It's also a good opportunity to reorganize the columns by listing them in the order that I want. I have HourlyRate, DayOfWeek, start and end time, StartDate, and PostID. All I need to do next is to add these columns as a parameter when loading my DataFrame.
All right, this is already so much easier to explore. Take a look at the StartDate column, which has a string type. That's because only ISO8601 dates are detected automatically. I'll need to explicitly specify any other date format. I can fix that by using CSVReadingOptions that Alejandro explained earlier. Using Foundation Date Parsing API, I'll add a date parsing strategy. I'll specify the format as year, month, day; the locale as US English; and the time zone as Pacific Standard Time. Then I'll pass the CSVReadingOptions when loading my DataFrame.
Now that the StartDate column has the right type, I can easily filter the DataFrame so that I have only active parking policies. Starting with the variable to represent the current date, then I'll filter the DataFrame using the filter method. The filter method takes a column name -- in this case, StartDate -- and a type -- Date. In the closure, I unwrap the optional date, returning false when the date value is nil so that it doesn't appear in my filter result. And lastly, I keep the start dates that are less than or equal to my current date. I'll go ahead and change my print to show you the filtered result.
From now on, I won't be needing the StartDate column, so I'll go ahead and remove it. But I need to be careful, since I can't remove a column from a DataFrame slice. I'll first have to convert to DataFrame and make filteredPolicies of var, since removing a column is a mutating method. Now I can remove the column using the removeColumn method and specify the StartDate column as the column to remove. All right, that's all I wanted to explore in the parking policies dataset. In the next section, Alejandro will discuss ways that you can augment your tabular data. Back to you, Alejandro! Alejandro: Thanks, David. Now I now have some great insights into the dataset. The next step is going to be transforming and augmenting it to match our needs. The simplest kind of transformation is changing the values within a column. This can take the form of a map operation where each value is mapped to a new value, possibly of a different type. TabularData provides an in-place version of map as a convenience: transformColumn. In this example, I am transforming the DayOfWeek column from a string to an integer representing the weekday. This what the code would look like. For each element, we convert the string to an Int.
Similar to transformColumn, the decode method handles decoding of data. When dealing with CSV files, you may encounter arrays or dictionaries embedded within the CSV as JSON values. TabularData provides a decode method for this. Here is an example where the DataFrame on the left has an embedded JSON data blob. Decode lets you use a JSONDecoder to transform the column into your own type; in this example, Preferences. And this what the code would look like. Keep in mind that the Preferences type needs to conform to the Decodable protocol, and the column needs to contain elements of type Data, which is what JSONDecoder expects as input. Another useful operation is the filled method. It lets your replace all missing values in a column with a default value. And to finish the list of column operations, I like to mention summary. Summary gives you a quick overview of the contents of a column. The summary method returns a categorical summary. It includes the number of elements, shown in the description as someCount; the number of missing elements, shown as noneCount; the number of unique elements; and the most frequent values, known as the mode. There is also numericSummary, which is only available for columns containing numeric values. It includes counts as well, plus mean, standard deviation, and other statistics. Here, I'm showing the print result of summary. But you can also use the summary struct directly to access the statistics. For instance, if you want to filter scores to the ones in the 75th percentile. OK, that was a lot of column transformations, but column transformations are not the most interesting. DataFrame transformation is where it really gets interesting. Unlike column transformations, DataFrame transformations manipulate multiple columns at once. A simple example is sorting. We all know how sorting works, but let me illustrate for clarity. Let's sort this table by score. This affects all columns. Also note that row indices change when sorting. Another interesting DataFrame transformation is combineColumns. The combineColumns method lets you combine multiple columns into one. For example, imagine that you have separate columns for latitude and longitude, but you want to combine them into a CLLocation type. Here is an example of doing this. First, I specify the columns I want to combine. Then I give a name to the new column. Then I specify the types of the input columns and the new column, and note that everything has to be optional. I handle the missing value case, and I build the new value. Similar to column, there is also a summary method for DataFrame. It returns summary statistics for every column. Note that this may be costly if you have a large DataFrame; it may be better to summarize only the columns you are interested in. Another interesting method is explode. It takes a column that contains an array of elements and creates a new row for every element in the array. Let's look at this example. This time, the scores column contains an embedded array of scores for each person. If I apply the explode operation to the DataFrame, each of these becomes a new row. We have repeated names for people who had multiple scores. This is useful when filtering or doing other operations that require looking at each individual score. With these tools in our arsenal I'll turn it back to David, who will help us get the meter data into the form that we need it. David, show us some code. David: Thanks, Alejandro. I don't know about you, but for me, the most important part about parking is the location. Luckily, I have another CSV file that has just what I need. Let me show you what's in there. Similar to before, I'll start by loading the data, but this time, I already know the columns I'm interested in. I have POST_ID, STREET_NAME, STREET_NUM, LATITUDE, and LONGITUDE, and I'll print the result using the same formattingOptions from the previous demo. The first augmentation I want is to combine the latitude and longitude columns into a new column with a core location type. The combineColumns method is perfect for the job. Here, I'm combining the latitude and longitude columns into a new column named location. In the closure, I specify the latitude and longitude parameter types and the core location return type. Next, I unwrap the optional latitude and longitude values, returning nil in the case that either one is nil. And finally, passing the latitude and longitude values to a core location initializer. With location in my DataFrame, I can start building the first feature for my app: given a location, search for the closest parking meters. I'll write a function named closestParking that takes a location, a DataFrame, and the amount of parking meters to include in the search result. I'll start with a local copy. And then using the transformColumn method that Alejandro introduced earlier, I'll transform location to distance. And then, of course, I'll rename the location column to distance. Finally, I'll sort the distance column in ascending order and limit the number of spots to return. Just for fun, let's test this out using the Apple Store in San Francisco. I'll plug in the coordinates that I found on Apple Maps, the meters DataFrame, and limit the search result to five parking spots. Perfect! It looks like there's lots of parking close to the Apple Store on Post Street. The first feature of the app is working great, but what if all of the closest parking is already taken? The next feature of the app is to find streets with the most parking. But before I implement this feature, let me introduce a new concept called grouping. Grouping splits your data into groups, given a grouping column. For example, the STREET_NAME column. The group method first identifies unique street name values -- Post Street, California Street, and Mission Street -- and then splits the rows into corresponding groups. Each group is a DataFrame slice. Now, let's jump back into the code. I'll group the meters by street name using the grouped method. Then I can count how many parking meters each street group has and serve the result in descending order. The streets with the most parking are at the top of the result, which is what I need for my app. This is so awesome! Two great features for my app. But wait a minute, I just realized there's a bug in the first feature. The closest parking meters only consider the meters DataFrame. What I really need is the closest parking meters with active parking policies. This is getting interesting, since that information is in the data from demo one. Let me show you how to join data from two different sources so that I can fix the bug. You may be familiar with joining if you've used a relational database before. It allows you to combine two DataFrames together using a key. The key is a value that appears in both DataFrames. In the meters and policies DataFrames, the key is the POST_ID, which uniquely identifies a parking meter. The join operation results in a DataFrame with rows where the POST_ID from meters matches the POST_ID from policies. The rows are composed of the matching data from the left DataFrame and the right DataFrame. Notice that the column names have either a left or right prefix. This indicates which side of the join the column came from. The prefixes help avoid naming collisions in the join result. This operation was an inner join, which is the default. There are three other join kinds: left outer, right outer, and full outer. I won't go into the details here, but please refer to the documentation to learn more. All right, that's all I wanted to cover in tabular data augmentations. In the next section, Alejandro will talk about best practices. Alejandro: Thanks, David. Now that we have all the data in the form we need it, it's time to build our app. Let me talk about how you can reuse your exploration code while making it production ready. Let me go back to the code we started with for loading a CSV file. If you do this, the columns are going to have unknown types. This is problematic for operations like filter or join where you need to know the type ahead of time. If you are loading the data from a user-supplied source, making assumptions about the type is risky. It may lead to your app crashing. Instead, you should declare the types that you expect when loading data, like in this example. Here, I'm defining column IDs for every column I care about. And then I'm providing both the column names and the column types to the CSV initializer. Remember that you can use the column ID instead of a string in any method that refers to a column. Now, if there are invalid values, you will get an exception that you can handle, for instance, by presenting an error to the user. This way you can ensure you have the columns and column types you expect. This is particularly important when using custom date formats because if you don't specify that your column is of type date, the date parsing may fail silently and produce a string column instead. Forcing it to be a date will throw an exception that includes the contents of the cell that failed, which will help you debug the problem. Speaking of errors, these are the sort of errors you should expect when loading a CSV file. Failed to parse will be generated when using a custom date parser and a cell fails to parse. The other ones are self-explanatory, but please refer to the documentation. And to finish, let me briefly mention performance. Most of the time, you should not need to worry about performance, but there are a few cases where you will see a large impact when working with large datasets. The first one is date parsing when loading a CSV. Date parsing has a lot of special cases and considerations and as such, it tends to be slow. If your CSV file takes more than a couple of seconds to load, this is the first place you should look to make improvements. One option is to delay parsing. This works particularly well when you don't need the date information right away. For instance, you want to perform filtering or grouping first. If that's not an option, consider handcrafting a date parser that optimizes performance for your date strings. When grouping, always use a column containing a basic Swift type as the group column, such as string or Int. This will speed up grouping performance. If you are grouping by more than one column, consider first combining the columns into a single column of a simple type first and then grouping. For example, if you want to group by day of week and meter type, consider combining those two properties into a string. For instance, day-type. Similarly, when joining, consider joining on a column containing a basic Swift type. With this, we are ready to finish the app. David, let's wrap it up. David: Using TabularData best practices, I'll write the app's search functionality. The Parking struct will store the joined meters and policies DataFrame. And I defined a location ColumnID, since multiple methods need it. Let's dive into the details in the loadMeters method. At the top, I have the Column IDs that I need for loading the meters. Then, I load the meters and specify the expected types of each column. This will throw if there's any mismatch in the provided CSV file. Next I verify the resolved columns are exactly what I expected, and I'll throw a custom ParkingError otherwise. Lastly, I refactored the combineColumns operation to use the latitude, longitude, and location column IDs. With that, the app's search functionality is production-ready. I'll hand it back to Alejandro for a recap of the TabularData framework. Alejandro: Thanks, David. Let's recap. Today we showed you how TabularData lets you explore an unknown dataset, manipulate it, and bring it into your app. We explored a dataset, looked at some column and data transformations, and we finished with some best practices around error handling and performance. I can't wait to see how you use TabularData to make great apps. Thank you!
-