-
了解 Metal 函数指针
Metal 是一个兼顾图形框架与着色器的,面向底层、低开销的硬件加速应用程序接口,在程序中可以制造绚丽的视觉效果。了解如何通过函数指针将使用 Metal Shading Language 编写的着色器变得更具有编辑与扩展性。学习如何利用 Metal 着色器中新增的动态数据流控制系统。了解如何通过函数指针在光线追踪程序中指定自定义相交函数。我们将会解释函数指针如何支持多种编译模式,以便开发者能够将 GPU 功能与运行时性能进行平衡。
资源
- Modern rendering with Metal
- Accelerating ray tracing and motion blur using Metal
- Metal for Accelerating Ray Tracing
- Debugging the shaders within a draw command or compute dispatch
- Metal Feature Set Tables
- Metal Performance Shaders
- Metal
- Metal Shading Language Specification
相关视频
WWDC21
-
搜索此视频…
(你好 WWDC 2020)
你好 欢迎来到 WWDC (了解 Metal 函数指针) 大家好 我是 Rich Forster Apple 的图形处理器软件工程师 此次演讲 我将和大家讨论 今年为 Metal 添加的 新函数指针 API 我们从简单的函数指针开始 函数指针使我们能够引用可以调用的代码 通过允许我们编写代码 函数指针使我们的代码可扩展 这样以后可以调用 我们以前从未见过的代码
经典示例是回调 这一过程执行跳转到 用函数指针识别的代码处 这让我们能够为插件、专门化和通知 提供函数 但我们还可以做更多 今天我将讨论如何在 Metal 中 公开函数指针支持 以及我们如何使用可见函数实现目标 我将介绍我们支持的不同编译模型 包括其含义以及何时使用 然后 我将讨论可见函数表 最后讨论性能 所以我们从 Metal 中的函数指针开始
当我们向 Metal 添加函数指针时 我们知道会有很多机会可以使用它们 很明显的例子是光线跟踪 在此处我们使用函数指针 来指定自定义相交函数 我鼓励你观看与本次演讲同时进行的 光线追踪演讲
光线追踪作为一个好例子 也可以讨论函数指针的其他用法 今天我就从此处讲起 当我们将光线追踪 应用到经典的康奈尔盒时 我们会将光线发射到场景中 当它们碰到表面时 我们需要给相交位置着色 通常 我们有相交表面的材料 然后我们将继续追踪 直到碰到光线为止 在此处我们要评估光的贡献 我们来重新讨论一下光线追踪的流程 首先 我们从相机产生光线 然后发射到场景中 然后我们测试这些光线 与场景中几何图形的相交情况
接下来 我们在每个相交点计算一个颜色 并更新图像 这一过程被称作着色 着色过程也可以产生额外的光线 所以我们测试这些光线与场景的相交情况 并根据我们的需要重复此过程 来模拟光线在场景中的反弹 今天我们将简化此次演示的内容 从执行单个交点的路径追踪器开始 然后对其交点进行着色 这一过程将在创建计算管线的 单个计算机内核中 管线中包括这三个阶段中每个阶段的代码 但是 我想重点介绍的是着色阶段 这是输出图像之前的最后一步 而且该阶段提供了 一系列使用函数指针的机会
在我们的光线跟踪内核中 着色发生在近结束阶段 一旦我们有了交点 我们就可找到匹配的材料 并且为该材料执行着色 在此例子中 我们所有的材料代码和光照代码 都存在于在文件其他位置中的 着色函数内 我们来更深入地了解一下着色函数
我们的着色函数包括几个步骤
这是一个简单的路径追踪器 它可以马上根据表面交点处的光线 来计算光 然后我们使用材料把光线应用在交点处
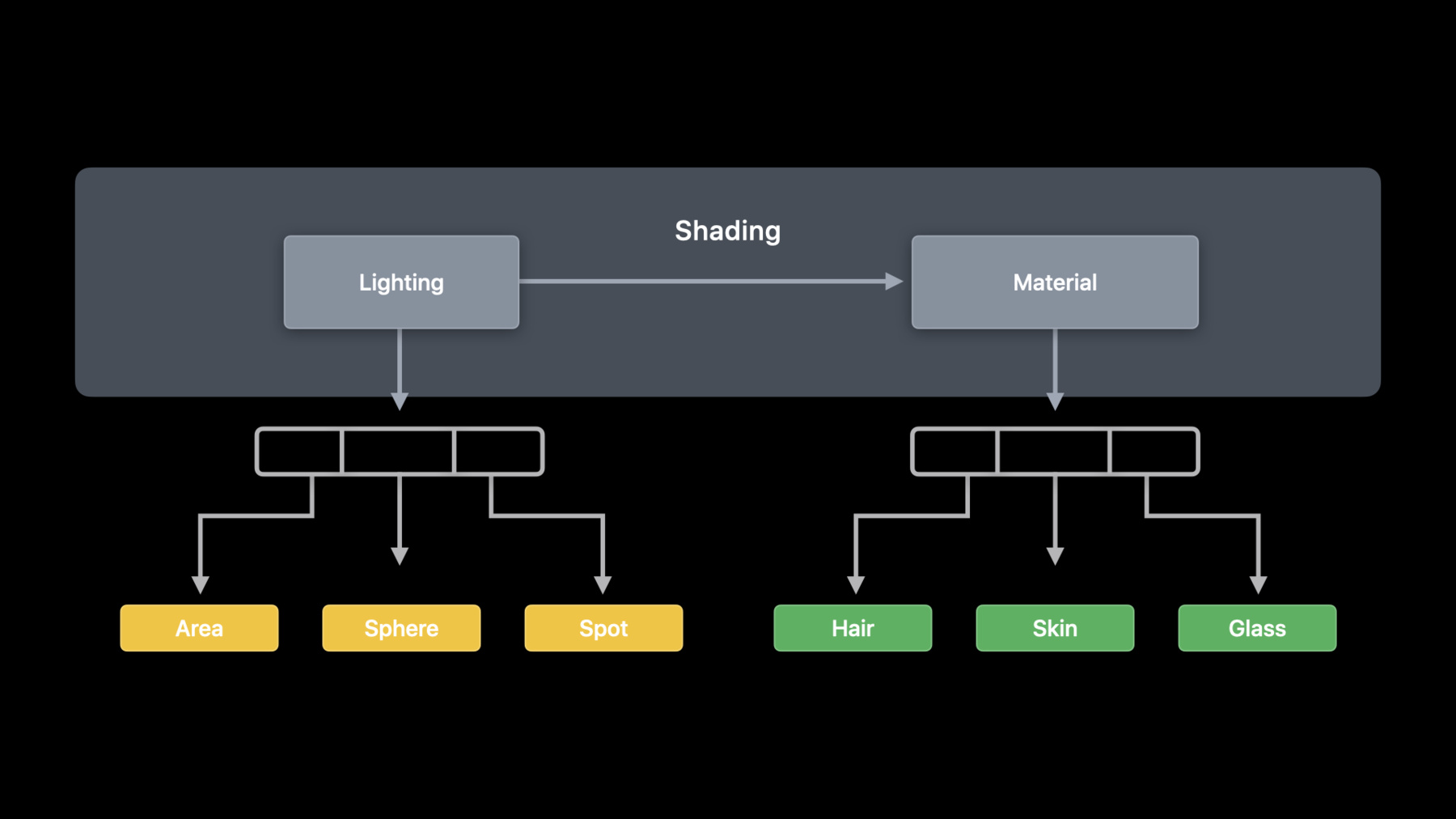
在流程方面 我们可以 将光和材料视为独立的阶段 但是 光的类型不止一种 材料也是不止一种
我们可以将光分为不同类型的光线 每种光线类型都需要不同的代码
而且相比光照代码 材料代码的变化要更多 我们将在 Metal 中使用 新的可见函数类型 来帮助我们使用光照函数和材料函数
可见是一种新的函数资格属性 如同顶点、片段或内核 我们可以在函数定义中使用可见属性 而且当我们使用可见属性时 是在声明我们想从 Metal API 来操纵该函数 我们用设备查询来检查 是否可以使用 API 执行此操控
使用可见函数 我们可以将自己的代码视为 我们可引用的灵活对象 在本例中 我们考虑区域光照代码 该代码作为一个对象 可以在表示我们管线的 内核外面存在 该代码可以存在于另一个 Metal 文件 或另一个 Metal 库中
要声明我们的光线函数可见 我们在定义函数之前添加可见属性 这可以让我们创建一个 Metal 函数对象 来表示该函数中的代码
下一步是将我们的 Metal 着色器代码 连接到管线 以便我们可以进行调用 首先 我们将区域光照代码 打包到 Metal 函数对象中 然后可以将新的 Metal 函数对象 添加到管线中
我们的区域光照函数有了可见属性 我们可以将其打包到中央处理器的 Metal 函数对象中 我们使用标准方法为可见函数按名称创建 一个 Metal 函数对象
然后将函数对象作为链接函数的一部分 添加到计算管线描述符中 以便管线创建过程可以将其添加到管线内 这样我们在后面可以用函数指针引用它 既然我们在讨论为管线添加可见函数 我们就需要讨论可用的编译模型选择类别
一旦我们的每个光照函数和材料函数 有了对应的 Metal 函数对象 我们就可以把它们添加到管线上
在构建管线时 我们可以复制每个可见函数 这一行为 我们称为“单一编译” 因为我们有了单一的对象 来表示我们的管线 及其使用的所有可见函数
我们使用在前面看到的同一链接函数对象 来列出我们可能从管线中调用的函数 然后我们使用标准管线创建 API 创建我们的 ComputePipelineState
我们管线的创建会产生一个对象 里面包括我们内核代码的一个特殊版本 和我们所有函数的特殊副本 这种特殊化类似于链接时间优化 此处内核代码和可见函数 可以基于它们的用法得到优化
但是 这种优化可能会 增加创建管线所需的时间 并且由于我们在管线中添加了 函数对象副本 会产生一个更大的管线对象 但是我们想做的可能是 将函数对象置于管线的外面 并且能独立存在 方便管线调用 但不必进行复制 这是分别编译管线的基础
我们创建每个 Metal 函数对象时 可以将每个函数编译为 独立的图形处理器二进制形式 这样我们就可以使函数代码单独存在 并在多个管线中重复使用
为了将函数编译为二进制 我们要使用函数描述符 这样我们可以为 Metal 函数对象的创建 添加选项 在创建我们函数的例子中 这一代码段创建的 Metal 函数 和带有名称参数的同一方法相同 但是 函数描述符让我们 可以指定更多的配置选项
我们使用描述符的“选项”属性 请求二进制预编译 函数创建会将我们的函数预编译为二进制
然后 我们在链接函数对象的 二进制函数数组中提供新函数 这表明我们在引用函数的二进制版本 而不是为计算管线 要求复制和特殊化函数 如你所见 对于预编译的函数 和我们想要特殊化的函数 我们可以混合与匹配 然后 像以前一样 我们使用标准调用来创建管线
我们已经介绍了单一编译和分别编译 现在是时候比较每种编译的优点了 对于单一编译 我们使用标准方法创建可见函数 对于分别编译 我们将预编译为二进制 这样我们可以共享编译二进制 并且可以避免在管线创建过程中 对函数进行二进制编译
我们配置管线描述符时 我们使用函数数组来表示 我们希望它们特殊化 并且使用二进制函数数组 来表示我们想要使用二进制版本
在单一编译情况下 特殊化的结果是出现更大的管线 分别编译的结果是产生一个管线 为二进制函数添加调用 并且二进制函数将被共享
和为二进制函数添加调用相比 函数特殊化还需要 更长的管线创建时间 如前所述 这类似于链接时间优化 即编译器可以利用其了解整个管线的优势 但是需要额外的构建时间 才能应用这些特殊化
这一函数特殊化 意味着单一编译具有最棒的运行性能 分别编译管线的灵活性 意味着调用我们的二进制函数 会有一些运行开销 正如我们之前看到的 你可以混合使用预编译的函数集 和特殊化的函数 但是完全特殊化的单一编译管线 会提供最佳的性能 在后台创建新的单一编译管线 来替换现有管线中的任何单独编译的函数 应该始终是可实现的 回到我们分别编译的管线 我们有可用的函数数组 可以从管线进行调用 但是 每当你认为 自己有一组固定的函数时 另一个函数总会出现
在本例中 我们有一个新的木质材料 想添加到我们的管线 增量式编译用于将新函数添加到 现有管线 在动态环境中出现新函数 是十分普遍的 尤其是一些游戏流在进行时 可能会用新的着色器加载新资产
将这个加入代码中 首先 我们需要在创建初始计算管线时 做出选择 以支持增量式编译 默认情况下不支持增量式编译 因为启用二进制函数的后添加 意味着即使在管线创建时 未指定二进制函数 管线创建也必须期望能调用二进制函数
然后我们使用函数描述符 为木材着色器创建 Metal 函数对象 并将该函数作为预编译的二进制函数
最后我们在 ComputePipelineState 上 使用新添加的方法 来创建带有任何其他二进制函数的 计算管线
接下来 我想谈一谈可见函数表 可见函数表是我们将函数指针 传到可见函数再到图形处理器的方法
回到我们为着色考虑过的 光照函数和材料函数 我们需要将这些提供给 在图形处理器上运行的内核
为了让我们可以把相关函数分类 并将其传递给图形处理器 我们使用 Metal API 创建可见函数表 可见函数表现在成了一个对象 我们可以将其传递给 Metal 着色器代码
在开始之前 我们添加一些使用声明 来定义函数指针类型 以避免我们的代码示例太过冗长 可见函数表可以被指定为内核参数 而且它们使用缓冲区绑定点 我们也可以把它们传递到参数缓冲区
然后 在我们的着色器中 我们通过索引访问我们的函数 我们可以使用指向函数的指针 或直接从表中调用它
在中央处理器上 基于我们想在表中展现的函数条目数 我们从 ComputePipelineState 分配可见函数表
然后我们使用创建管线状态时 指定的函数句柄填充此表
最后 我们使用该表时 我们根据需要 将其设置在 computeCommandEncoder 或 argumentEncoder 上 如果使用 argumentEncoder 请不要忘记调用 useResource 为了确保使用增量编译的管线 成本尽可能的低 我们要确保可以再次使用祖先管线中的 可见函数表 表中已经存在的句柄仍然有效 你只需要向表中添加新的函数句柄即可 无需创建和构建全新的表 最后 你只需确保 不会从之前的管线 访问新添加的函数句柄即可 今天最后但同样重要的一点 我想讨论在你的 app 中使用函数指针的 性能注意事项 在性能方面 我们将涉及三个主要领域 我们从优化函数组开始 回到我们之前的图表上 我们可以看到 我们有针对特定目的的函数组 但是 管线创建并没有意识到这些关系
我们可以根据函数在着色器中的用处 对其进行分组 我们知道我们将使用哪些函数用作灯光 哪些函数用作材料
为了显示我们在着色函数中的 函数的分组情况 我们已经对其进行了更新 使其包含我们进行调用的函数组 在 Metal 中 我们可用函数组通知编译器 将在哪里使用这些函数 在着色器代码中 我们在调用函数的线路上 应用函数组属性 以便给该位置可调用的 那些函数组命名
然后 在配置计算管线描述符时 我们用每个组都可调用的设置函数 在代码字典中指定分组 这会为编译器提供尽可能多的信息 并且可以在生成管线时帮助进行优化 除了在函数数组中 编译器为函数执行的特殊化操作 编译器能够利用每个组中 设置函数之间的任何共同点 然后将其应用于标有函数组属性的调用点
所有这些新的灵活性 还代表着你现在可以执行递归函数
如果我们回到光线追踪流程开始的地方 这种光线追踪模型中我们考虑多次反射 它可以以迭代或递归的方式来执行
如果我们关注相交和着色之间的关系 那我们可以遵循这个调用图
使用我们的递归路径追踪器 在发现相交之后 对交点进行着色 在本例中 我们选择新木质材料函数 这种木质材料包含反射成分 所以它与场景中的另一条光线相交 并为相交处着色
我们再次与覆盖有木质材料的表面相交 这会再次反射并与场景相交 我们再次选中木质材料 我们可以继续 但是通常你会限制递归光线追踪器的深度 以提高性能并且避免栈溢出 所以我们在此处停止 为了支持调用可见函数链的 计算内核的各种堆栈用法 我们在计算管线描述符上 公开 maxCallStackDepth 属性 这样就可以指定 我们想从内核调用函数的深度 默认深度是 1 以便可见函数和相交函数的典型用例 在无需其他操作的情况下 可以直接运行 此值应用于可见函数调用的所有链条中 但是在光线跟踪的情况下 该代码以迭代方式编写 以减少堆栈使用情况 我今天要讨论的最后一个性能注意事项 是使用函数指针时差异的影响 但是在深入讲解函数指针之前 我应该强调一下 去年的《Metal 光线追踪》讲座 涵盖了高级方法 以在后续反弹变得不太一致时 处理光线追踪中的固有差异 这包括具有块线性布局的光线相干性 用于活动光线的光线压缩 和平衡图形处理器之间负载的交错平铺 我建议你查看去年的演讲 回顾其中 光线追踪优化的思想
但是 对于函数指针来说 我们需要在线程级别考虑差异 当我们调度你的线程组时 我们知道它们在被定义为 SIMD 组的 较小线程组中执行 在这个例子中 我们有八个 SIMD 组
SIMD 组中的线程同时执行 同一条指令时 其性能最佳
当下一条要执行的指令 对于 SIMD 组的线程而言不相同时 通常来说他们在着色器代码中 到达分叉点时 就会出现差异 这种情况下 我们通常的办法是 让线程的一个子集执行他们的指令 而其他线程不再使用 当所有线程 都在积极执行有用的指令时 我们才有最佳的性能
函数指针是另一种可能导致差异的情况 我们通过函数指针调用函数时 我们需要考虑设置器函数指针 会出现多大的差异 在最糟的情况下 在 SIMD 组中 每个线程可能都在调用不同的函数 而执行时间将是依次执行 每个必需的函数所花费的时间
但是 如果我们考虑整个线程组 我们可能有足够的工作 来创建完整的 SIMD 组
为了处理我们的差异 我们将把函数调用重新排序 从而将一致性引入我们的 SIMD 组 这意味着对一个线程的函数调用 将很可能由线程组中的另一个线程来执行
在代码方面 我们将从编写所有函数参数 线程索引 以及调用线程组内存的函数开始 然后 我们将使用自己喜欢的排序 对函数索引进行排序
接下来 我们按它们的排序顺序 调用这些函数 函数的结果返回到线程组内存 然后每个线程都可以从那里读取其结果 我们还可以使用设备内存 来执行类似的版本 用于我们的参数和结果 在调用复变函数的情况下 应该减少差异的开销 使用 Metal 中的函数指针 可以做很多事情 今天 我们介绍了可见函数的创建和使用 以及如何将它们添加到可见函数表 从而提供可以从计算内核调用的函数
我们讨论了不同的编译模型 让你可以选择如何平衡管线大小 和创建时间与运行性能之间的关系 以及如何能够动态添加函数 最后 我们讲到了在 app 中 使用函数指针的 一些性能注意事项 今年我很享受研究函数指针的工作 我很高兴能与你分享 希望你在 WWDC 参会愉快
-
-
3:09 - Our simple Path Tracer in Metal Shading Language:
float3 shade(...); [[kernel]] void rtKernel(... device Material *materials, constant Light &light) { // ... device Material &material = materials[intersection.geometry_id]; float3 result = shade(ray, triangleIntersectionData, material, light); // ... } -
3:30 - Our shading function
float3 shade(...) { Lighting lighting = LightingFromLight(light, triangleIntersectionData); return CalculateLightingForMaterial(material, lighting, triangleIntersectionData); } -
4:59 - Declare a function as visible
[[visible]] Lighting Area(Light light, TriangleIntersectionData triangleIntersectionData) { Lighting result; // Clever math code ... return result; } -
5:30 - Single compilation pipeline on CPU
// Single compilation configuration let linkedFunctions = MTLLinkedFunctions() linkedFunctions.functions = [area, spot, sphere, hair, glass, skin] computeDescriptor.linkedFunctions = linkedFunctions // Pipeline creation let pipeline = try device.makeComputePipelineState(descriptor: computeDescriptor, options: [], reflection: nil) -
7:43 - Introducing MTLFunctionDescriptor
// Create by function descriptor: let functionDescriptor = MTLFunctionDescriptor() functionDescriptor.name = "Area" // More configuration goes here let areaBinaryFunction = try library.makeFunction(descriptor: functionDescriptor) -
8:08 - Binary pre–compilation
// Create and compile by function descriptor: let functionDescriptor = MTLFunctionDescriptor() functionDescriptor.name = "Area" functionDescriptor.options = MTLFunctionOptions.compileToBinary let areaBinaryFunction = try library.makeFunction(descriptor: functionDescriptor) -
8:20 - Binary functions
// Specify binary functions on compute pipeline descriptor let linkedFunctions = MTLLinkedFunctions() linkedFunctions.functions = [spot, sphere, hair, glass, skin] linkedFunctions.binaryFunctions = [areaBinaryFunction] computeDescriptor.linkedFunctions = linkedFunctions // Pipeline creation let pipeline = try device.makeComputePipelineState(descriptor: computeDescriptor, options: [], reflection: nil) -
11:04 - Incremental compilation pipeline
// Create initial pipeline with option computeDescriptor.supportAddingBinaryFunctions = true // Create and compile by function descriptor let functionDescriptor = MTLFunctionDescriptor() functionDescriptor.name = "Wood" functionDescriptor.options = MTLFunctionOptions.compileToBinary let wood = try library.makeFunction(descriptor: functionDescriptor) // Create new pipeline from existing pipeline let newPipeline = try pipeline.makeComputePipelineStateWithAdditionalBinaryFunctions(functions: [wood]) -
12:22 - Visible function tables on the GPU
// Helper using declaration in Metal using LightingFunction = Lighting(Light, TriangleIntersectionData); using MaterialFunction = float3(Material, Lighting, TriangleIntersectionData); // Specify tables as kernel parameters visible_function_table<LightingFunction> lightingFunctions [[buffer(1)]], visible_function_table<MaterialFunction> materialFunctions [[buffer(2)]], // Access via index LightingFunction *lightingFunction = lightingFunctions[light.index]; Lighting lighting = lightingFunction(light, triangleIntersection); return materialFunctions[material.index](material, lighting, triangleIntersection); -
12:49 - Visible function tables on the CPU
// Initialize descriptor let vftDescriptor = MTLVisibleFunctionTableDescriptor() vftDescriptor.functionCount = 3 let lightingFunctionTable = pipeline.makeVisibleFunctionTable(descriptor: vftDescriptor)! // Find and set functions by handle let functionHandle = pipeline.functionHandle(function: spot)! lightingFunctionTable.setFunction(functionHandle, index:0) // Find and set functions by handle computeCommandEncoder.setVisibleFunctionTable(lightingFunctionTable, bufferIndex:1) argumentEncoder.setVisibleFunctionTable(lightingFunctionTable, index:1) -
14:23 - Function groups on GPU
// Add function groups to our shading function float3 shade(...) { LightingFunction *lightingFunction = lightingFunctions[light.index]; [[function_groups("lighting")]] Lighting lighting = lightingFunction(light, triangleIntersection); MaterialFunction *materialFunction = materialFunctions[material.index]; [[function_groups("material")]] float3 result = materialFunction(material, lighting, triangleIntersection); return result; } -
14:49 - Function groups on CPU
// Function Group configuration let linkedFunctions = MTLLinkedFunctions() linkedFunctions.functions = [area, spot, sphere, hair, glass, skin] linkedFunctions.groups = ["lighting" : [area, spot, sphere ], "material" : [hair, glass, skin ] ] computeDescriptor.linkedFunctions = linkedFunctions
-