-
Sync to iCloud with CKSyncEngine
Discover how CKSyncEngine can help you sync people's CloudKit data to iCloud. Learn how you can reduce the amount of code in your app when you let the system handle scheduling for your sync operations. We'll share how you can automatically benefit from enhanced performance as CloudKit evolves, explore testing for your sync implementation, and more.
To get the most out of this session, you should be familiar with CloudKit and CKRecord types.Chapters
- 0:00 - Intro
- 0:48 - The state of sync
- 3:09 - Meet CKSyncEngine
- 9:47 - Getting started
- 13:18 - Using CKSyncEngine
- 19:25 - Testing and debugging
- 22:27 - Wrap-up
Resources
Related Videos
WWDC23
Tech Talks
-
Search this video…
♪ ♪ Tim: Hi, I'm Tim, I'm an engineer on the CloudKit team. My colleague Aamer and I are here to talk about a new CloudKit API called CKSyncEngine. CKSyncEngine is designed to help sync data between the device and the cloud. First, I'll talk about the state of syncing to CloudKit on Apple platforms. Next, I'll give an overview of what CKSyncEngine is and how it works. Then, you'll learn about how to get started with CKSyncEngine in your own project. Once you're set up, you'll learn how to use the sync engine to sync data across devices. Finally, you'll learn about best practices for testing and debugging your integration with CKSyncEngine. First, the state of syncing to CloudKit.
When you build a new app, people just expect their data to sync. They make something on their iPhone, and when they open up their Mac, they expect it to be there too. From the outside, this looks like magic. Their data is in one place, and then it's everywhere. For you and me, it's not that easy. CloudKit itself isn't that complicated, but syncing in general is hard. When you bring multiple devices into the scenario, there's just a lot that can go wrong. So the simpler you can make your sync code, the better. And the best way to simplify your sync code is to write as little as possible. Thankfully, you have some great API choices for syncing with CloudKit, and these APIs do a lot of the heavy lifting for you.
If you want a full-stack solution that includes local persistence, you can use NSPersistentCloudKitContainer. If you want to bring your own local persistence, you can use the new CKSyncEngine API. If you still think you need more fine-grained control, you can use CKDatabase and CKOperations. But if you want to sync with CloudKit, and if you're not using NSPersistentCloudKitContainer, you should use CKSyncEngine. Sync involves many moving parts, and using a higher level API like CKSyncEngine can help reduce complexity and improve your app's sync experience.
At its core, sync is mostly just sending changes from one device and fetching them on another, converting to and from CloudKit records when necessary. That's pretty easy to do on its own, but there's more than just that. You need to learn about all the different operations and errors, monitor system conditions, listen for account changes, handle push notifications, manage your subscriptions, track a bunch of state, and a whole lot more. When you use CKSyncEngine, the amount of sync code you have to write becomes much smaller and more focused. You only have to handle the things that are specific to your app, and the sync engine handles the rest. In order to write a proper sync engine, you probably need several thousands of lines of code, and then double that amount in your tests. I actually heard a rumor that NSPersistentCloudKitContainer is backed by over 70,000 lines of tests. CKSyncEngine has quite a lot of tests as well, and that's 'cause it handles a lot of this stuff for you. So what is this new CKSyncEngine API? CKSyncEngine encapsulates the common logic for syncing with a CloudKit database. It aims to provide a convenient API, while also giving flexibility when necessary. It's designed to meet the needs of most apps that would otherwise write their own custom sync engine. Generally, if you're looking to sync your app's private or shared data, CKSyncEngine is a great choice. The data model you use with the sync engine consists of records and zones, which are the same types of data used in the rest of CloudKit. You can access any of this data using any existing CloudKit API. Because of this, if you already have an existing CloudKit sync implementation, CKSyncEngine can sync with that as well. The sync engine is being used by several apps and services across the system, including the Freeform app. Another example is NSUbiquitousKeyValueStore, which was rewritten on top of the sync engine. This is a good example of a backward compatible use case. In newer OSes it uses the sync engine, but it still syncs with previous versions as well. So if you already have a custom CloudKit sync implementation, then you have the option to switch to CKSyncEngine. If the benefits sound enticing enough, you should consider switching, but it's not required. Sometimes, it's nice to just have less code to maintain. You'll also be able to benefit whenever CKSyncEngine gets a new enhancement. As the platform evolves, the sync engine will evolve as well, making it easier and more efficient to sync as time goes on. You might also benefit from the smaller API surface of CKSyncEngine. This allows you to focus on your app's specific data model and use case. If you're considering using CKSyncEngine, but you have some specific needs that it doesn't support, you can always build your own if you'd like. However, if you think your needs could be satisfied by a new feature in CKSyncEngine, consider filing a feedback with your use case. After all, some of the best ideas for the sync engine have come from developers like you.
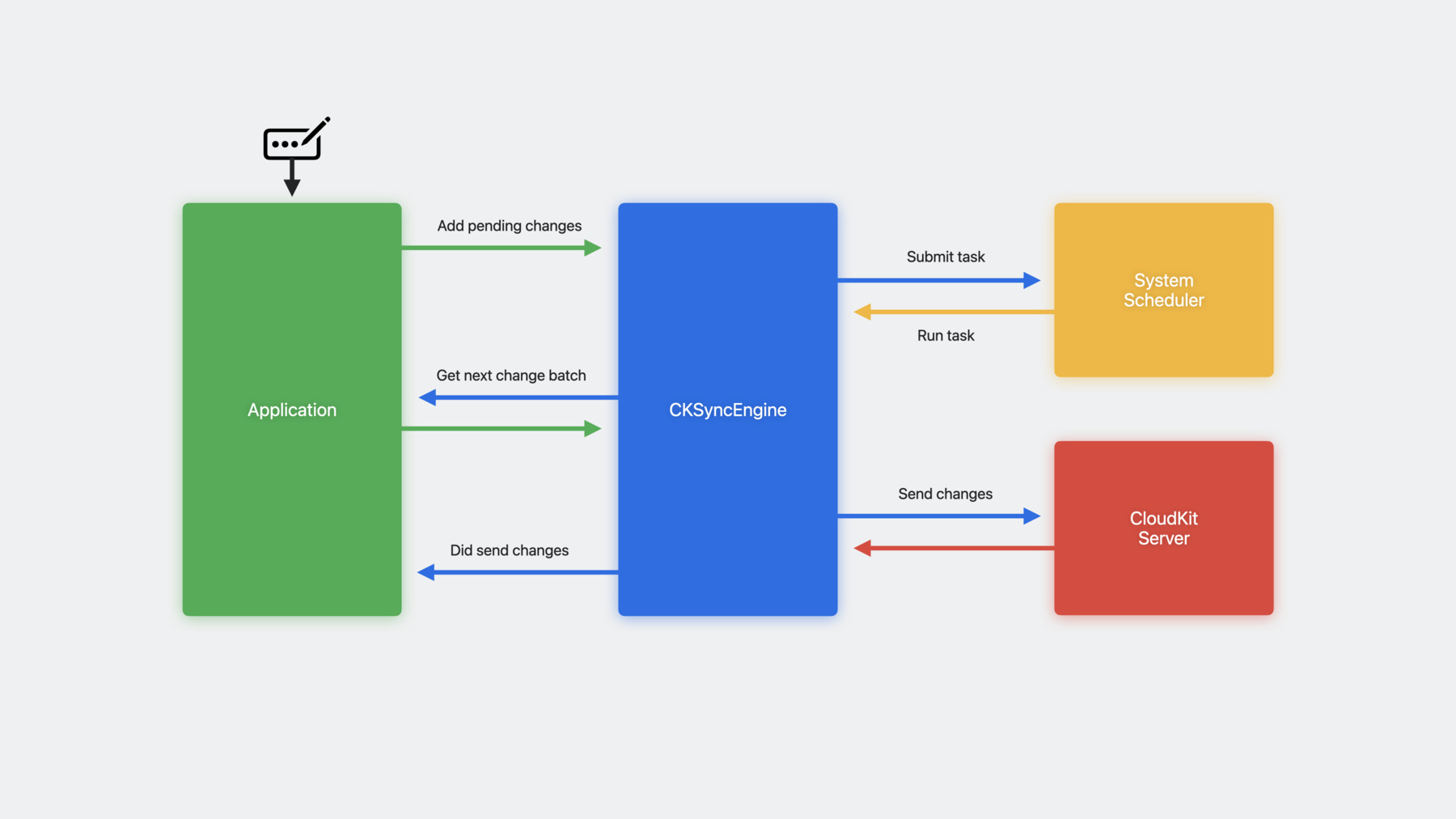
So how does the sync engine actually work? Generally, the sync engine acts as a conduit of data between your app and the CloudKit server. Your app communicates with the sync engine in terms of records and zones. When there are changes to save, your app gives them to the sync engine. When it fetches these changes on another device, it gives them to your app. That said, when the sync engine has work to do, it doesn't always do it immediately. If it needs to communicate with the server, it'll first consult with the system task scheduler. This is the same scheduler used across the OS for background task management, and it makes sure that the device is ready to sync. Once the device is ready, the scheduler runs the task, and the sync engine talks with the server. This is the basic flow of operation for the sync engine. More specifically, what does it look like when the sync engine sends changes to the server? First, someone makes a modification to the data. Maybe they typed something or they flipped a switch or deleted an object. Then, your app tells the sync engine that there's a pending change to send to the server. This lets the sync engine know that it has work to do. Next, the sync engine submits a task to the scheduler. Once the device is ready, the scheduler runs the task. When the task runs, the sync engine starts the process of sending changes to the server. In order to do that, it asks your app for the next batch of changes to send. If someone made a single modification, you might only have one pending change. However, if someone imports a huge database of new data, you might have hundreds or thousands of changes. Since there's a limit on how much can be sent to the server in a single request, the sync engine asks for these changes in batches. This also helps to reduce memory overhead by not bringing any records into memory until they're actually needed. After you provide the next batch, the sync engine sends it to the server. The server responds with the result of the operation, including any information about the success or failure of these changes. Once the request finishes, the sync engine calls back to your app with the result. This is your opportunity to react to the success or failure of the operation. If you have any more pending changes, the sync engine will continue to ask for batches until there's nothing left to send. Now that one device has sent some data to the server, other devices will fetch that data. When the server receives a new change, it sends a push notification to the other devices that have access to that data. CKSyncEngine automatically listens for these push notifications in your app. When it receives a notification, it submits a task to the scheduler. When the scheduler task runs, the sync engine fetches from the server. When it fetches new changes, it gives them to your app. This is your chance to persist these changes locally and show them in the UI. And that's the basic flow of operations when using the sync engine. One thing all these flows have in common is the system scheduler. Generally, CKSyncEngine will consult the scheduler before doing anything. This is how it's able to automatically sync on your behalf.
The scheduler monitors system conditions like network connectivity, battery level, resource usage, and more. It makes sure the device has met any prerequisite conditions before it tries to sync. By respecting the scheduler, the sync engine can ensure a proper balance between user experience and device resources. In normal conditions, sync will be pretty fast, usually within a few seconds or so. However, if there's no network connection, or if the device's battery is low, then sync might be delayed or deferred. If the device is under a heavy load, you don't want your sync mechanism to interfere with other more urgent tasks in your app. By relying on the sync engine's automatic scheduling, you can be confident that you'll sync when you should, and not when you shouldn't. Not only is it more efficient, it's also just easier to use. If you don't have to worry about when to sync, you can focus on everything else. That said, there are legitimate use cases for manually performing a sync. You might have a pull-to-refresh UI that fetches immediately. Or you might have a button to back up now that immediately sends any pending changes to the server. Manually syncing can also be useful when writing automated tests. It can help you simulate specific sync scenarios across multiple devices where you need to control the order of events. In general, we recommend that you rely on automatic sync scheduling. But, we understand that there are valid use cases for manual syncing, and the sync engine has API to do that when necessary. And now, Aamer is going to talk about how to start using CKSyncEngine. Aamer: Thanks for that introduction, Tim. My name is Aamer. I'm an engineer on the CloudKit Client team. I'll now cover getting started with CKSyncEngine. Before you use CKSyncEngine, there are a few things you need to do to set up your project. These requirements are the same whether you're using CKSyncEngine or building your own custom CloudKit implementation. First, you'll need a basic knowledge of CloudKit's fundamental data types, CKRecord and CKRecordZone. The sync engine API deals heavily in terms of records and zones, so you should understand what they are before diving in. Next, you'll need to enable the CloudKit capability for your project in Xcode. Finally, since the sync engine relies on push notifications to keep up to date, you'll also need to enable the remote notifications capability. Once you have all that, you're ready to initialize your sync engine. You should initialize your CKSyncEngine very soon after your app launches. When you initialize your sync engine, it will automatically start listening for push notifications and scheduler tasks in the background. These notifications and tasks might happen at any time, and the sync engine needs to be initialized in order to handle them.
The main means of communication between your app and CKSyncEngine is through a protocol called CKSyncEngineDelegate. When initializing your sync engine, you'll need to provide an object that conforms to this protocol. In order to function properly and efficiently, the sync engine tracks some internal state. You'll also need to provide the last known version of the sync engine state.
While performing sync operations, it will occasionally give your delegate an updated version of this state in the form of a state update event. Whenever the sync engine gives you a new state serialization, you should persist it locally. This way, you can provide it the next time your process launches and you initialize your sync engine. To help understand this, I'll explain it using a few code examples.
In order to initialize a sync engine, you'll pass in a configuration object. In the configuration, you'll need to provide the database you want to sync with, the last known version of the sync engine state, and your delegate. One of the functions in the delegate protocol is the handle event function. This function is how the sync engine notifies your app about different events that happen during normal sync operation. For example, it'll post events when it fetches new data from the server, or when the account changes. One of these events is the state update event. When the sync engine updates its internal state, or when you update the state yourself, the sync engine will post a state update event. In response to this event, you should locally persist this new serialized version of the state. In the example, you'll use this state serialization the next time you initialize your sync engine. Now that the foundation is set up, I'll cover syncing with the sync engine.
There are a few simple steps that allow you to send changes to the server. First, add your pending record zone changes and pending database changes to the sync engine state. This will alert the sync engine that it should schedule a sync. The sync engine will ensure consistency and deduplicate these changes.
Next, implement the delegate method nextRecordZoneChangeBatch. The sync engine will call this to get the next batch of record zone changes to send to the server. Lastly, handle the events sentDatabaseChanges and sentRecordZoneChanges. These events will post once changes are sent up to the server.
Here's an example of sending changes to the server. This application edits data and wants to sync new record changes. To do this, you'll tell the sync engine that you need to save that record by adding a pending record zone change to the sync engine state. When the sync engine is ready to sync the record, it will call the delegate method nextRecordZoneChangeBatch. Here you'll return the next batch of changes to send to the server. You initialize a RecordZoneChangeBatch by providing the list of pending changes and a record provider. The list of pending changes contains the recordIDs to save or delete, and the record provider that will map those IDs to records when the actual sync occurs. Here's how your application can fetch changes from the server. The sync engine automatically fetches changes for you from the server. When it does, it will post the events fetchedDatabaseChanges and fetchedRecordZoneChanges. Depending on your use case, you may want to listen for the events willFetchChanges and didFetchChanges. For example, handing these events may be useful if you want to perform any setup or cleanup tasks before or after fetching changes.
Here's an example where our app fetches changes from the server. When the sync engine fetches changes within a record zone it will post the fetchedRecordZoneChanges event. This event contains the modifications and deletions that were performed by another device. When listening for this, you should check the fetched modifications and fetched deletions. When you receive modifications, you should persist the data locally. When you receive deletions, you should delete the data locally. Fetching database changes works very similarly and can be handled with the same approach. Handling errors can be tricky. The sync engine helps with this too. The sync engine automatically handles transient errors such as network issues, throttling, and account issues. The sync engine will automatically retry work that is affected by these errors. For other errors, your app will need to handle them. Once you've resolved those errors, you should reschedule the work if necessary.
This is an example of error handing when sending record zone changes. When the sentRecordZoneChanges event is posted, you should check the failedRecordSaves to see if any records failed to save.
serverRecordChanged indicates that the record changed on the server. This means that another device saved a new version the application hasn't fetched yet. You should resolve the conflict and reschedule the work.
zoneNotFound indicates that the zone does not yet exist on the server. To resolve this, you may need to create the zone and then reschedule the work. The sync engine will always attempt to save zones first, and then records. networkFailure, networkUnavailable, serviceUnavailable, and requestRateLimited are examples of transient errors that the sync engine will handle for you. You'll still receive these errors for your awareness but you do not need to take action in response to them. The sync engine will automatically retry for these errors when system conditions permit.
Another thing the sync engine helps with are account changes. iCloud account changes can happen at any time on a device. The sync engine helps you manage and react to these.
The sync engine listens for changes and will notify you using the accountChange event to indicate sign in, sign out, or that the account switched. Your application should prepare for the change depending on the type.
The sync engine will not begin syncing with iCloud until there is an account present on the device.
You can initialize the sync engine at any time, and it will automatically update you when there is an account change. Sharing data with other users is a key part of CloudKit. The sync engine makes life easier here too. The sync engine works with the CloudKit shared database. You just create a sync engine per database that your application will work with. For example, you can create a sync engine for the private database, and another sync engine for the shared database. To learn more about sharing with CloudKit, check out the "Get the most out of CloudKit Sharing" Tech Talk.
That covers using CKSyncEngine. Now I'll cover how to test when using it. Automated tests are the best way to ensure stability in your codebase while rapidly developing. Using the sync engine, you can simulate device-to-device user flows using multiple CKSyncEngine instances.
You should simulate edge cases that your app may encounter. To do this, you can intervene in the sync engine flow by setting automaticallySync to false. Here is a test case that simulates a data conflict between two devices and the server. The purpose of this test is to simulate the full flow users will take when working with multiple devices. It also validates conflict resolution. First, simulate two devices using MySyncManager. In this example, MySyncManager creates a local database and sync engine. Device A sets the value to A and sends its changes to the server.
Before device B fetches the changes from the server we'll ask it to send its changes to the server too. Since device A saved to the server first, device B's save is expected to fail. This will result in a server record changed error, which will exercise the local conflict resolution code. This sample expects the conflict resolution to prefer the data from the server, so the new value on device B will be the value most recently sent to the server from device A.
Here are a few key points that can help speed up testing and debugging. Understanding the sequence of events on each device will help pinpoint where in the flow your application may be having problems. Logging as much as possible when developing will help trace these flows, and compare logs across multiple devices. CloudKit will log each event that you receive, but you should also log the actions that surround them in your application.
Logging record IDs and zone IDs can help debug what data is flowing between a sync engine, the server, and other devices you may be syncing with.
Writing tests that simulate each of your user flows will help maintain stability as you grow your codebase.
Look at timestamps when piecing the puzzle together. You may only have a few sync operations happening, or you may have many in a short time. Ensuring you're tracing the right ones is key to debugging amongst multiple devices.
These steps will help create and maintain a reliable, long-lasting application using CKSyncEngine.
That concludes our talk on CKSyncEngine. Take a look at the sync engine sample code to see a full working example in an app. To dive in deeper, check out our CKSyncEngine documentation. If you have any suggestions to improve the sync engine, please submit feedback for the CloudKit team. We're excited to see what you create with it.
Thanks for watching. Have a great WWDC! ♪ ♪
-
-
12:14 - Initializing CKSyncEngine
actor MySyncManager : CKSyncEngineDelegate { init(container: CKContainer, localPersistence: MyLocalPersistence) { let configuration = CKSyncEngine.Configuration( database: container.privateCloudDatabase, stateSerialization: localPersistence.lastKnownSyncEngineState, delegate: self ) self.syncEngine = CKSyncEngine(configuration) } func handleEvent(_ event: CKSyncEngine.Event, syncEngine: CKSyncEngine) async { switch event { case .stateUpdate(let stateUpdate): self.localPersistence.lastKnownSyncEngineState = stateUpdate.stateSerialization } } } -
14:13 - Sending changes to the server
func userDidEditData(recordID: CKRecord.ID) { // Tell the sync engine we need to send this data to the server. self.syncEngine.state.add(pendingRecordZoneChanges: [ .save(recordID) ]) } func nextRecordZoneChangeBatch( _ context: CKSyncEngine.SendChangesContext, syncEngine: CKSyncEngine ) async -> CKSyncEngine.RecordZoneChangeBatch? { let changes = syncEngine.state.pendingRecordZoneChanges.filter { context.options.zoneIDs.contains($0.recordID.zoneID) } return await CKSyncEngine.RecordZoneChangeBatch(pendingChanges: changes) { recordID in self.recordToSave(for: recordID) } } -
15:40 - Fetching changes from the server
func handleEvent(_ event: CKSyncEngine.Event, syncEngine: CKSyncEngine) async { switch event { case .fetchedRecordZoneChanges(let recordZoneChanges): for modifications in recordZoneChanges.modifications { // Persist the fetched modification locally } for deletions in recordZoneChanges.deletions { // Remove the deleted data locally } case .fetchedDatabaseChanges(let databaseChanges): for modifications in databaseChanges.modifications { // Persist the fetched modification locally } for deletions in databaseChanges.deletions { // Remove the deleted data locally } // Perform any setup/cleanup necessary case .willFetchChanges, .didFetchChanges: break case .sentRecordZoneChanges(let sentChanges): for failedSave in sentChanges.failedRecordSaves { let recordID = failedSave.record.recordID switch failedSave.error.code { case .serverRecordChanged: if let serverRecord = failedSave.error.serverRecord { // Merge server record into local data syncEngine.state.add(pendingRecordZoneChanges: [ .save(recordID) ]) } case .zoneNotFound: // Tried to save a record, but the zone doesn't exist yet. syncEngine.state.add(pendingDatabaseChanges: [ .save(recordID.zoneID) ]) syncEngine.state.add(pendingRecordZoneChanges: [ .save(recordID) ]) // CKSyncEngine will automatically handle these errors case .networkFailure, .networkUnavailable, .serviceUnavailable, .requestRateLimited: break // An unknown error occurred default: break } } case .accountChange(let event): switch event.changeType { // Prepare for new user case .signIn: break // Delete local data case .signOut: break // Delete local data and prepare for new user case .switchAccounts: break } } } -
18:49 - Using CKSyncEngine with private and shared databases
let databases = [ container.privateCloudDatabase, container.sharedCloudDatabase ] let syncEngines = databases.map { var configuration = CKSyncEngine.Configuration( database: $0, stateSerialization: lastKnownSyncEngineState($0.databaseScope), delegate: self ) return CKSyncEngine(configuration) } -
20:00 - Testing CKSyncEngine integration
func testSyncConflict() async throws { // Create two local databases to simulate two devices. let deviceA = MySyncManager() let deviceB = MySyncManager() // Save a value from the first device to the server. deviceA.value = "A" try await deviceA.syncEngine.sendChanges() // Try to save the value from the second device before it fetches changes. // The record save should fail with a conflict that includes the current server record. // In this example, we expect the value from the server to win. deviceB.value = "B" XCTAssertThrows(try await deviceB.syncEngine.sendChanges()) XCTAssertEqual(deviceB.value, "A") }
-