-
Make apps smarter with Natural Language
Explore how you can leverage the Natural Language framework to better analyze and understand text. Learn how to draw meaning from text using the framework's built-in word and sentence embeddings, and how to create your own custom embeddings for specific needs.
We'll show you how to use samples to train a custom text classifier or word tagger to extract important pieces of information out of text— all powered by the transfer learning algorithms in Natural Language. Find out how you can create apps that can answer user questions, recognize similarities in text, and find relevant documents, images, and more.
To get the most out of this session, you should have a basic understanding of the Natural Language framework. For an overview, watch “Introducing Natural Language Framework” and “Advances in Natural Language Framework.” You can also brush up on model training using Create ML through “Introducing the Create ML App.”Resources
Related Videos
WWDC23
WWDC19
-
Search this video…
Hello and welcome to WWDC. Hello everyone. Welcome to our session on natural language processing. The goal of this session is to help you make your apps smarter by using the power of NLP in the Natural Language framework. I'm Vivek and I'll be jointly presenting this session with my colleague Doug Davidson. So let's get started. Let's begin with the central notion of language. Language is a code system that helps us humans solve difficult problems through communication and it also provides us with a very unique type of social interaction.
You could think of how we communicate using language. Language is an intermediate representation that helps us translate concepts into symbols which can then be expressed in the form of words, phrases or sentences with some grammatical structure. The medium of expression can be through speech, perhaps through writing on a keyboard or Apple Pencil. It can even be an image or a video that you capture using your camera. Now language also has this remarkable property that not only helps us translate concepts into symbols but it also helps us assimilate content into concepts. And the last few years as we have moved from human intelligence into machine intelligence, the central notion of language has been replaced by NLP. NLP has now become the intermediate representation that helps machines translate concepts into symbols and also assimilate content into concepts. But what does on device NLP at Apple look like? Until 2017, the primary modality where NLP was exposed at Apple was through the NS LinguisticTagger Class and Foundation. Now this provides fundamental text processing such as language identification, tokenization and so on.
In 2018, we introduced the Natural Language framework. The Natural Language framework provides everything that NSLinguisticTagger can and on top of it, we started focusing on state of the art machine learning and modern linguistic techniques such as text embedding and custom models.
Not only that, we also started tightly integrating Natural Language framework with the rest of the machine learning ecosystem at Apple through tight integration with Create ML and Core ML. Now, before we jump into the rest of the session we'd like to tell you that ENSLinguisticTagger has been marked for deprecation. We strongly encourage you to move towards Natural Language for all your language processing needs. Now if you look at the kinds of functionalities provided in the Natural Language framework they can be broadly broken down into three different categories. The first is in the area of fundamental text processing. The second is in the realm of text embeddings. And the third is in the area of custom models. So let's begin with fundamental text processing.
Natural language framework provides several basic fundamental building blocks such as language identification, tokenization, part of speech tagging, lemmatization and named entity recognition. And we provide these APIs across a wide variety of languages. For more information about these APIs you can refer to our 2018 and 2019 WWDC sessions. But at a high level all of these APIs operate on a piece of text and what they give is an output is a hypothesis or a prediction. However, it did not tell us a notion of confidence associated with this prediction. And this year we have a brand new API call for confidence course. So this builds on top of the existing functionality. And in addition to the hypothesis or the predicted labels you can also get the confidence course using the APIs.
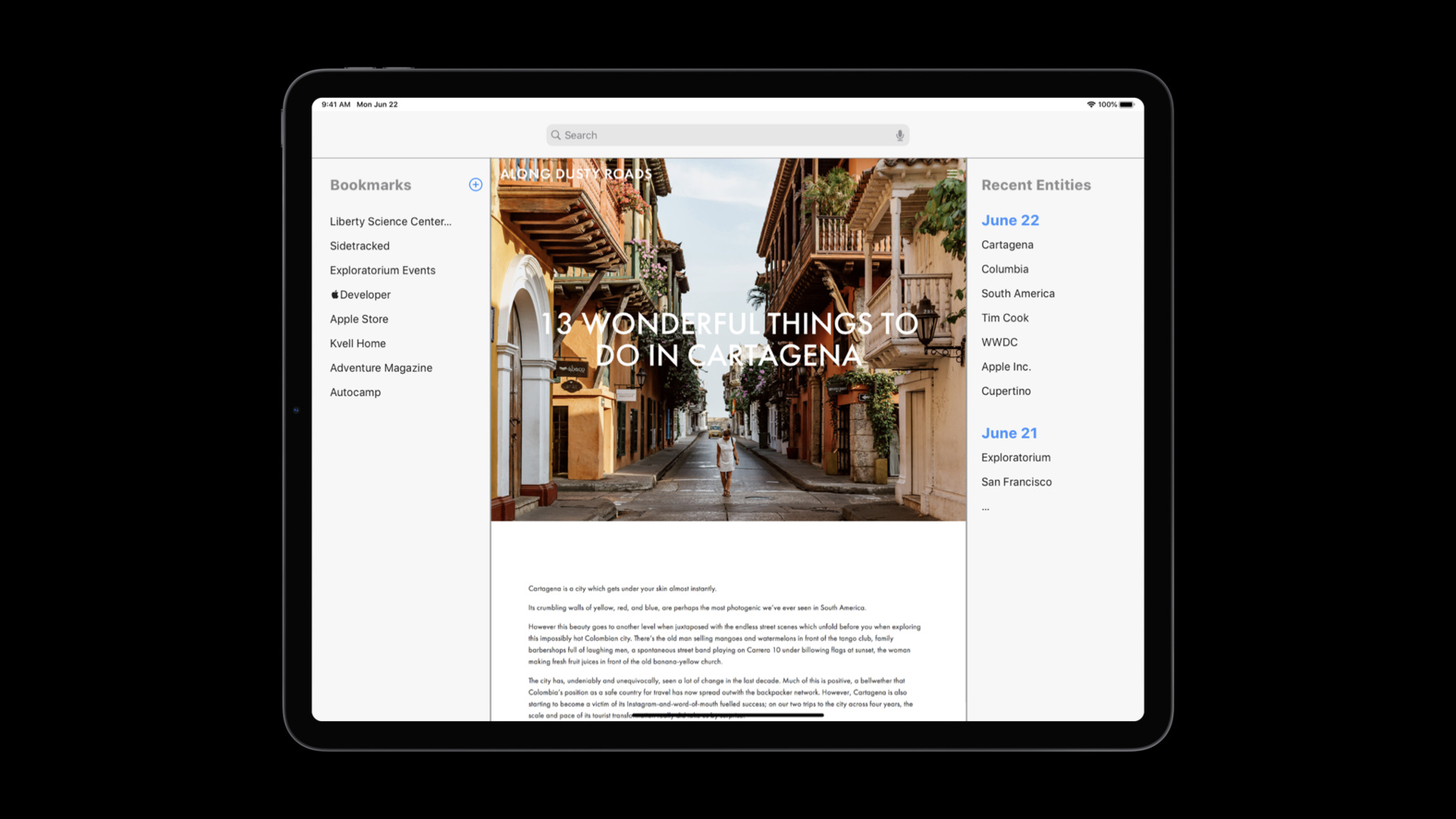
Let's see how we can use this. We start off by creating an instance of NLTagger and specify the tag scheme to be named type. This is something that you've been used to so far. Now we have a brand new API called tagHypotheses. So when you use tagHypotheses in addition to getting the predictions either at the sentence level or the token level you also get a confidence code associated with that prediction. Let's look at how to use these confidence scores through the lens of a hypothetical app called Buzz. Buzz is a News reader app. As part of this application, you can browse articles, you can bookmark them and you can organize them so that you can read them later.
And what we would like to do is add a new feature to this application. Then we extract recent entities from the articles that you've written. So we want to populate these entities on the right side bin. And when you click on an entity, you can be taken back to the article that you've already read. So how do we do this. So we want to use a Named Entity Recognition API to automatically analyze this text and extract these named entities so that we get these named entities such as Cartagena and so on and so forth. Now if you take a close look at the entities on the right side you'll see that is a spurious entry. We have something called Do Not Disturb while driving. So the Named Entity Recognition API gives us person names, organization names as well as location names. This seems like a false positive from this machine learning API. So how do we fix this. Suppose we had an input sentence such as he was driving with Do Not Disturb while driving turned on. When we passed the sentence through the Named Entity Recognition API what it does is it analyzes the sequence of tokens and produces a span of tokens as an organization name. Now this hypothesis is incorrect in this machine learning model. Now on the power of confidence course you can also get the confidence course for each of these labels. As you can see the confidence score is pretty low. By setting the threshold of, for instance, point eight for organization names, you can easily filter out this false positive. That this if you now go back to the app and incorporate this in your application you can easily filter out the false positive and you have a much better and enhanced user experience. We do have a few recommendations in terms of best practices. First we'd like to recommend that you avoid heuristic hard coding of these threshold values and calibrate it on representative data that is pertinent to your app and domain of operation. We'd also recommend that you consider creating thresholds on a per class basis rather than setting a global threshold for all the classes in a particular application you considered on a per class basis so that you get final control of false positives because there's false negatives in your app. Now let's move on and shift our attention to text embeddings. Text embeddings are really important. In fact they have been the cornerstone of recent advances in modern and to really understand Text embeddings, let's begin with the notion of a text corpus. What is a text corpus? A text corpus is a collection of documents which are comprised of paragraphs sentences phrases and words and in conventional NLP. Then we start with the text corpus. The first thing that we do is to tokenized this corpus. Then we tokenized a text corpus. What we get is an inventory of words in this text corpus. And this inventory of words can be thought of as a bag of words representation that each word is independent. Now if you were to look at this from a machine representation standpoint it is also called this one-hot encoding. So in this example if you have a bunch of words food, burger, pizza, automobile, bus and car and we've gone over the text corpus and extracted these words. Now each word here is represented by a bit vector which has one bit on and the rest of the bits off. And the length of this vector is the same as the number of unique words in your text corpus.
Now as humans we can see that food, burger and pizza are related concepts. And similarly, automobile, car and bus are also related concepts. However if you just look at this bit vector representation, it doesn't provide any information about the similarity or dissimilarity of goods. So wouldn't it be great if we had a representation that also incorporated the information about similarities of words? And this is really where word and embeddings come in.
When you use word embeddings again, you start with the text corpus and what you get as an output is a vector representation of words. Words that are similar are clustered together and words that are dissimilar are clustered away.
So in this example you can see that burger, pizza and food are clustered together and away from the concepts of automobile, car and bus. To obtain these word embeddings you can use different sorts of machine learning algorithms which would be linear models or non-linear models. But at a high level they capture this vector representation by analyzing global core coincidence of words in the text corpus. If you consider this and look at it from a machine representation standpoint, now the representation is different from one hot-encoding. Each word gets a real value vector of these dimensions or you can think of it as D columns. And now if you look at the vector for food, burger and pizza they are close to each other in the vector space. Similarly the vectors for automobile, car and bus are also close to each other but far away from the food concepts. Now that you understood word embeddings let's look at the different types of word embeddings. The first is called Static Word Embeddings. Let's understand this concept.
Suppose we had an input sentence. "I want a burger from a fast food joint." And we want to extract the word embedding for the word food. For the case of static embeddings what we do is for all the words in the vocabulary we pre-compute the embeddings and stored it as a lookup table. Now this lookup table is computed and stored on -evice in an efficient manner. So when we need to look up the word embedding for a particular word such as food, we simply go into this lookup table pick the corresponding vector and give it as the output. Now static word embeddings are really useful. They are very useful to give the nearest neighbors of words in the vector space and they're also very useful as inputs to neural network algorithms.
But they do have some shortcomings. Suppose we had an input sentence such as "It is food for thought" where the word food is represented in a different kind of connotation based on the context. What happens in static word embeddings is you will still pass this to the lookup table and extract the same vector for the word food. Even though we know that the connotation is different and the context is different. So even though the semantic connotation of the word food is different because of the context in which it's used, we still get the same vector representation. So can we do better? And this is where dynamic word embeddings come into the picture. So in dynamic word embeddings what we do is we pass every sentence through a neural network. And what we get is a dynamic embedding for every word in that sequence which is completely contextual. So we passed these two sentences through dynamic word embeddings which can be a neural network such as a transformer network or an ELMo style model. What we get is an output is one vector for each word that is different based on the context. So the word food now gets completely different vector representations because the context of food in these two sentences is different. Now on the OS we support static embeddings in a variety of languages, also across different Apple platforms. For more information about static word embeddings you can refer to our 2019 WWDC sessions. In addition to static word embeddings, we also support what we call is custom word embeddings wherein you can train your own embeddings using a third party toolkit such as fasttext, word2vec, GloVe, or perhaps even a custom neural network in TensorFlow or PyTorch. Once you do this you can bring these embeddings to Apple platforms, compress them and store them and use them in an efficient way.
Once you convert them to a representation on device you can use them just the same way as static word embeddings. Now in order to use word embeddings let's look at how you use it. So you create an instance of NLM embedding, Word embedding and you specify the language. And once you have this you can perform three different operations. The first is given a word, you can get the vector representation of the word. The second is given two words, you can get the distance between these two words in the vector space. And the third is given a word, you can find the nearest neighbors of the word in the vector space. Now let's look at the use of word embeddings through a hypothetical app called Nosh. Nosh is a food delivery app and as part of this application, we have an FAQ section. Now the user experience in this app especially in the FAQ section is not great. So if I were to find some information, I have to scroll to all these questions and look for the question that I'm interested in, and then for the corresponding answer. So we want to improve this user experience in the Nosh app by adding an automatic search feature so that you can type or you can speak the query and you can pick the corresponding question and show you the relevant answer. How do we build this using word embeddings? So one way to build this is using static word embeddings. Let's say you have an input query. Do you deliver it to Cupertino? When you pass it through the Word Embeddings API, you can enumerate every word and get one vector representation for each word in the sequence.
Once you do that a heuristic way of getting a sentence representation is to simply take the average of the vectors of every word and what you'd get is an output is one vector of the same dimension. Now you can also pe-compute the word embeddings for every single FAQ question in your database. So you would take every question, run it through word embeddings, get the vectors, average them and pre-compute the embeddings. So at runtime, given a query, you find the question that is closest to the input query vector and you pick the question and show the corresponding answer in the UI.
Now this seems like a reasonable way of solving this problem but it does have several shortcomings. The first is the issue with word coverage since static word embeddings work with the finite vocabulary, if you have an input query that does not have a word in the lookup table, it will lose information.
The second is using this averaging process is very noisy. It's akin to a bag of words representation that loses compositional knowledge. For instance if we had a query such as "Do you deliver from Cupertino to San Jose?" By simply taking the average we are jumbling up the words and we lose the compositional information contained in words such as from and to. So the big question is can we do better? And yes we certainly can. And we are delighted to tell you that we have a brand new technology called a sentence embedding that solves this problem. Now by using Sentence Embedding API then you pass an input query on a sentence such as "Do you deliver to Cupertino," it analyzes this entire sentence and encodes this information into a finite dimensional vector in the current API. The dimension of this vector is 512 dimensions. So how does this work? Intuitively you can think of it as starting from a text corpus and in the text corpus, if you were to tokenize the text at the sentence level when you pass it through the Sentence Embedding instead of working with words, now you have sentence representations. Each of these sentences are represented in this vector space in such a way that sentences that are conceptually similar are clustered together and sentences that are dissimilar are clustered away from each other. Now the technology under this is fairly complex and utilizes several machine learning techniques, one of which is pre-trained models in conjunction with custom layers such as bi-directional listing as well as fully connected layers. And we train these networks in a multi-task training set up on different tasks such as natural language inference, binary text similarity as well next sentence prediction.
But to use it, you don't have to worry about these details. You simply have to ask for it. So you start by importing NaturalLanguage. And you create an instance of NLEmbedding and sentence Embedding and specify the language as English. Once you have this you can ask for the vector of an input sentence. When you do this the sentence is run through the neural network. And what you get is an output is a finite 512 dimensional vector that encodes the meaning of this sentence. Given two sentences you can also find the distance between these two sentences in the vector space.
You simply run these two sentences underneath this API through the neural network, get the vector representation and then compute the distance. Now there are a wide variety of other potential applications for this technology.
But since we don't have a finite list of sentences right now and you cannot pre-compute the embedding for all the sentences a priori that is no nearest neighbors API available for this technology. But later in the session Doug will tell you how you can use sentence embeddings and do nearest neighbors by leveraging custom embedding technology. Now if you had to go back to the Nosh application then when you have a query such as "Do you deliver to Cupertino," you simply pass this through the Sentence Embedding API and you get one vector that encodes all of the meaning. Similarly for all of the FAQ questions in your index you can pre-compute the sentence embeddings and at runtime given an input you simply find the closest question.
And once you do this you show the relevant answer in the application at the UI level. To see the sentence embeddings in action I'm going to hand it over to Doug who's going to show us a demo of this working in the Nosh application. Over to you Doug. Thanks Vivek. So let's see some of this in action. In our Nash application, what we're going to do is to let the user type in a query string and then we're going to return an appropriate answer from our frequently asked questions using Sentence Embeddings. So let's look at some code. So the first thing we're going to do in this method is to just get a Sentence Embedding, in this case for English. Very simple. And then we'll ask that embedding for the vector for the user's query string. When we first constructed this application we took each of our answers and constructed for it, two or three example queries and pre-calculated the Sentence Embedding vectors for each one and put them in a table. So what we're going to do is just iterate through that table. We'll go through for each key, we have two or three vectors representing these example queries. We'll find the distance between each of those and our query factor. And the smallest distance is our nearest neighbor which represents the answer that we're going to show and will return that answer. So let's try it out.
So if the user types for example "how do I use it," then we can search and go through and find the nearest neighbor and point them to the "How does it work" section of our frequently asked questions. Or maybe they ask "Where do you deliver?" And then we'll search and find the nearest neighbor and point them to the delivery area section of our frequently asked questions. Or maybe the user wants to know "where is my order?" In which case we search, and we can point them directly to the order status section of our frequently asked questions.
Now there are many other possible uses for this. Let's consider another hypothetical sample application called Verse and Verse is an application for showing poetry. So Verse has many many different poems in it. And one obvious UI for this is that we could just have a long list of the poems where the user picks one and the new user sees that poem. And that's fine but wouldn't it be nice to have some additional ways of looking for these poems. For example, suppose that I type in "You're beautiful." Well then we can find out that Shakespeare said it better and we can do this using Sentence Embeddings. So what we can do is take each line of each poem and calculate the Sentence Embedding vector for that line and then put them in a table and then iterate through them just as we did in the Nosh application. But there's one twist here and that is that we have hundreds of poems, and thousands of lines. So it may be that this simple linear search and table that we use in the Nosh app isn't efficient enough and we have a solution to that. And the solution is to make use of custom embeddings. And what do we need in order to create a custom embedding? We need a dictionary. The keys in the dictionary are arbitrary. So I've chosen them here to be for example poem 1 line 1, poem 1 line 2 to be strings from which we can readily determine which poem we were looking at and which line. And then the values are just these vectors that we got for each line. And from that we can produce a custom embedding. And the custom embedding has two important properties. First it gives a very efficient space efficient representation of that dictionary. And second it has geometric information that we can use to do efficient nearest neighbor search without having to go through the entire thing.
And now to create one of these customized beddings. That's very simple. You can do this and create it now and then. All you do is to take that dictionary and pass it into Create ML. And what comes out is a Core ML model that represents that custom embedding. So let's take a look at this in action. Let's take a look at some code in our verse application. And here's the corresponding method in verse that takes the user's query string and returns the answer key. So just as before, we get the sentence embedding for English and we get the query vector for that embedding. But now the rest is even simpler. We just take our custom embedding and pass it in that query vector and it will directly return to us. The nearest neighbor and it will return the key that we put into that dictionary from which we created the custom embedding. And as I mentioned we can easily determine which is the right poem to return from that key. So let's try it out.
The user types in something like let's say "I love you" we can get a poetic expression for that and find a poem that represents that sentiment. Or maybe they type in something like "Don't forget me" and we can find a poem that expresses that sentiment - just about anything we want. We can find a suitable expression. Maybe it's "love isn't everything." And here's a poem for that too as well. Now I don't want to give the impression that the only thing you can do with Sentence Embeddings is this sort of text retrieval because Sentence Embeddings are useful for all sorts of different applications. For example consider a hypothetical app called FindMyShot which stores images and happens to have captions for each of those images. Now since the images associated with captions I can use Sentence Embeddings to find an image based on similarity between the user's query text and the caption.
And there are many other possible usages for these. You can use them for detecting paraphrases. You can use them for input, for training more complicated models and you can use them for clustering. So let me spend a moment to talk about clustering. If you don't have any pre-arranged text if all the text comes in from the user then you can still make use of Sentence Embeddings. For example if you had messages or maybe reviews or maybe problem reports or users you can take a Sentence Embeddings and calculate a vector for each one of these and then you can use standard clustering algorithms to group these into as many groups as you want. And what Sentence Embedding means is that these groups are going to be sentences close together in meaning. The availability of the Sentence bEmeddings is for a number of different languages English, Spanish, French, German, Italian, Portuguese and simplified Chinese. Add on macOS, iOS and iPadOS. Now these Sentence Embeddings are intended for use on natural language text especially text that comes in from the user. You don't have to do a lot of pre-processing on this text. You don't have to move stop words for example because the Sentence Embeddings has seen all this in their training and they're intended for being applied to text that is similar in length to a single sentence, maybe a couple of sentences or a short paragraph.
If you have text that's longer than that, then you can divide it up into sentences and apply the Sentence Embeddings to each one. Just as we did with our poems.
And also you can make use of the custom embeddings in case you have large numbers of these that you want to store and look through.
So next I'd like to turn to the topic of custom models.
The idea in custom models is that you bring in your custom training data and we train a model for you for some particular NLP task. Now there are two broad kinds of NLP tasks that we support that cover a wide range of functionality. The first is a text classifier, which the object is to take a piece of text and supply a label to it. And the other is word word tagger, in which the object is to take a sequence of words in a sentence and supply a label for each one. The custom model training is exposed through Create ML. You passing your training data, Create ML passes it to Natural Language. Natural Language produces a model and what you get out is a Core ML model, either a tagger or a text classifier. And our focus for the last couple of years has been on applying the power of transfer learning to these models. With transfer learning, the idea is that you can incorporate a pre-existing knowledge of the language so that you don't have to supply quite so much training data in order to produce a good model. And this pre-existing knowledge comes in by means of word embeddings because the word embeddings have been trained on large amounts of natural language text. Now we introduced this last year for text classifiers and that provides a very powerful solution for many apps. For example we can consider a hypothetical app called Merch which is intended for transactions between buyers and sellers and they communicate with each other about these transactions. But one complaint the users have perhaps is that they get sometimes spam messages and they don't want to have to look at all these. Well one possible solution is that you can train a text classifier by bringing in large amounts of example sentences labeled as spam or not spam and then train a text classifier and transfer learning model is actually very effective for this sort of task. And then the model in your app will tell you whether a particular message is likely to be spam and then you can show it appropriately or not to the user.
But what I really want to talk about today is the application of transfer learning to word tagging which is new this year. Now let's go back and talk about the task of word tagging. As I said the object is to take sequence of words in a sentence and supply a label for each one. And probably the prototypical task for this is part of speech tagging but it can be used for many other things. For example, you can potentially use word tagging to divide a sentence up into phrases or, and this is what we're going to be talking about here, you can take a sentence and extract important pieces of information from it even though it's unstructured text. For example in a travel application I might want to know where the user is coming from and where they're going to.
Can we make use of this in our Nosh application? Well let's take a look. So we saw that with the Sentence Embedding vectors we could return general answers to the user's queries. But there are other things that I might want to look at. And a user sentence for example, I might want to know what kind of food they're looking for, or where they want to get it from. And I can label, potentially label these parts of the sentence as food or a city where the food is coming from. Now the most obvious and simple way to handle this sort of problem would be to just list all the potential foods and potential cities and then just search through the text for each of those. And of course we support that sort of thing. We have an NLGazetteer class which provides an efficient representation for any number of tables of items that you might want to look for in text.
But the problem with this approach is that in general you're not going to be able to list all the potential values that you might want to look for. So as soon as you encounter some piece of text that you hadn't thought of before then this simple search is not going to help you.
And the other problem with this approach is that it doesn't take into account anything about the meaning of words and context. And a word tagger can solve both of these problems.
In addition it's possible to combine a word tagger and an NLGazetteer for even greater accuracy. So suppose I've decided that I actually want to use a word tagger for my Nosh application. Where do I start? The first thing to do is to decide what pieces of information I want to get out and assign labels to those. Then I collect sufficiently many as ample sentences that the user might enter and I decide how I'm going to label them. And then I actually label those sentences and continue to repeat this process until I have enough data to train a good model and I might have to continue repeating it. If my model ever runs across a situation that it doesn't handle adequately, usually the solution is to add some more training data and retrain the model. So what does our training data look like? So in our Nosh application we're going to add some labels to sentences like this so we'll use a neutral label. Oh here in this case for other for the pieces of text that we're not particularly interested in and we'll use labels like food from city restaurant for the pieces of text that we are specifically interested in. Now why did I say from_city rather than just city. Because I noticed that in these example sentences there are two kinds of ways where a city can come in. The first is where it's the city where the restaurant is located where the food is supposed to be coming from. And the second is whether it's the city the user is located where the food is being delivered to. And so I'm going to label those differently as from city to city. And because the word tagger can take advantage of the meaning of words in context. It can distinguish between these two provided I give it sufficient training data. And here is what the training data looks like in Json format which is very convenient for use with Create ML. So what I want to go and train a model and Create ML. It's very simple. If I'm doing it in code I just import Create ML and then I ask Create ML to provide me a model. Now we've supported this for a couple of years using an algorithm known as CRF Conditional Random Fields and it works well. But what's new this year is that we are applying the power of transfer learning to word tagging. And as I said before what transfer learning does is to allow us to apply pre-existing knowledge of the language so that you don't have to supply quite so much training data in order to train a good model. And the way in which this knowledge comes in is via dynamic word embeddings. As we said before the dynamic word embeddings understand something about the meaning words and context. Was it just what the word tagger wants. So we use the dynamic word embedding as an input layer and on top of it we take the data that you provide and we train a multi-layer neural network and that is the thing that actually produces the output labels.
Now this sounds complex but if you want it all you have to do is ask for it.
So instead of asking for the CRF algorithm you just ask for a transfer learning algorithm with dynamic word embeddings and then it will train a model for you. So let's take a look at that in action.
So here's the Nosh application and here is some of the training data that I have trained, added for it. And I produced, oh somewhat over a thousand sentences of this format. And you'll notice these are in Json format. So each example is a parallel sequence of tokens and labels one label for each token and you'll notice that cities are labeled from_city or to_city and you'll notice that foods are labeled and restaurants are labeled. And this is the data that I'm going to use to train my model. And so it's possible to train it in code but I'm going to train this model using the Create ML application which makes it very simple. So here's the Create ML application. All I have to do is point it to my training data, tell it which of the labels and tokens, and tell it which algorithm I want to use. In this case we're going to use the transfer learning algorithm. And this is going to be for English.
And that's really about all there is to it. I just started off and sent it to train. And the first thing that does is to load all the data extract features from it. And then it's going to start training using transfer learning. And it will train a neural network. So this takes a number of iterations with each iteration it gets more and more accurate. Now this particular training process takes two or three minutes. So I'm not going to make you sit through all of it.
I actually have a pre-trained model. So let's go back to the application and take a look at some code.
So here is an example method in the Nosh application that's going to make use of our trained model. So we're going to be passed in the user's string that they've typed. First thing we'll do is load our model our word tagger model as an NL model. And then what we're going to do here is use it with a NL tagger. That's convenient because the NL tagger will take care of all of the tokenization and application and just give us the results. So we've created a custom tag scheme that's just a string constant that refers to this set of tags and we'll tell our tagger that's what we want to use. And then we tell our tagger to use our custom model for this custom tag scheme. We attach the user's string to the tagger and that's really all there is to it. We can then use the tagger to go through the words and it will tell us for each one what it thinks the label should be whether it's restaurant or food or from_city or to_city or nothing. And then we take note of those particular pieces of what the user has entered and then we can use that according to the needs of the application to generate any sort of custom response that we might want to provide. So I've taken the liberty of adding a few custom responses to the Nosh application. Let's try it out. So the user might type something like "Do you deliver to Cupertino?" So what is our model going to tell us? It's going to look at all these words and it will notice that Cupertino is a city and it's a city they want delivery to. So we can generate a customer response that is specific to Cupertino. Or they might ask you "Do you deliver pizza" and then our model will notice that pizza is a food name so we can generate a custom response based on pizza. Or maybe they ask if we deliver from a specific restaurant Pizza City and the one in Cupertino.
And in that case the model will tell us that Pizza City is a restaurant name and Cupertino is a city where the food is coming from. And we can use either or both of those to generate a custom response that mentions those. So that shows the power of word tagging to extract pieces of information from unstructured text. So let's go back to the slides and let me turn it back over to Vivek.
Thank you Doug for showing us a demo of transfer learning for word tagging. Now transfer learning for word tagging is supported for the same languages as static embeddings and sentence embeddings across Apple platforms.
To get the best use out of transfer learning for word tagging technology. we have a few recommendations. We recommend that you first start off with a conditional random field, especially for languages such as English. The conditional random field, or CRF, pays attention to syntactic features which are quite useful in many applications. However if you do not know the kind of distribution that you'll be encountering at runtime it is better to use transfer learning because it provides better generalization.
We also recommend you to use more data for transfer learning for word tagging since the prediction is at a per token level in contrast with text classification, it requires an order of more magnitude data. As I mentioned NL Linguistic Tagger Class has now been marked for deprecation. We strongly encourage you to move towards Natural Language framework. We also told you how to use confidence codes along with existing APIs. And this can be used to prune out false positives in your application. Then we provided an overview of Sentence Embedding technology and demonstrated how you can use this in several hypothetical apps. We concluded with a new technology for transfer learning for word tagging.
With that, we'd like to conclude by saying make your arm smarter by using the Natural Language framework. Thank you for your attention.
-
-
3:53 - Confidence Scores: tagHypotheses
import NaturalLanguage let tagger = NLTagger(tagSchemes: [.nameType]) let str = "Tim Cook is very popular in Spain." let strRange = Range(uncheckedBounds: (str.startIndex, str.endIndex)) tagger.string = str tagger.setLanguage(.english, range: strRange) tagger.enumerateTags(in: str.startIndex..<str.endIndex, unit: .word, scheme: .nameType, options: .omitWhitespace) { (tag, tokenRange) -> Bool in let (hypotheses, _) = tagger.tagHypotheses(at: tokenRange.lowerBound, unit: .word, scheme: .nameType, maximumCount: 1) print(hypotheses) return true } -
12:19 - Word Embedding
import NaturalLanguage if let embedding = NLEmbedding.wordEmbedding(for: .english) { let word = "bicycle" if let vector = embedding.vector(for: word) { print(vector) } let dist = embedding.distance(between:word, and: "motorcycle") print(dist) embedding.enumerateNeighbors(for: word, maximumCount: 5) { neighbor, distance in print("\(neighbor): \(distance.description)") return true } } -
16:32 - Sentence Embedding
import NaturalLanguage if let embedding = NLEmbedding.sentenceEmbedding(for: .english) { let sentence = "This is a sentence." if let vector = sentenceEmbedding.vector(for: sentence) { print(vector) } let dist = sentenceEmbedding.distance(between: sentence, and: "That is a sentence.") print(dist) } -
18:36 - Finding nearest neighbor with sentence embedding
func answerKey(for string: String) -> String? { guard let embedding = NLEmbedding.sentenceEmbedding(for: .english) else { return nil } guard let queryVector = embedding.vector(for: string) else { return nil } var answerKey: String? = nil var answerDistance = 2.0 for (key, vectors) in self.faqEmbeddings { for (vector) in vectors { let distance = self.cosineDistance(vector, queryVector) if (distance < answerDistance) { answerDistance = distance answerKey = key } } } return answerKey } -
22:19 - Sentence embedding compressed as custom embedding
import NaturalLanguage import CreateML let embedding = try MLWordEmbedding(dictionary: sentenceVectors) try embedding.write(to: URL(fileURLWithPath: "/tmp/Verse.mlmodel")) -
22:47 - Finding nearest neighbor with sentence embedding and custom embedding
func answerKeyCustom(for string: String) -> String? { guard let embedding = NLEmbedding.sentenceEmbedding(for: .english) else { return nil } guard let queryVector = embedding.vector(for: string) else { return nil } guard let (nearestLineKey, _) = self.customEmbedding.neighbors(for: queryVector, maximumCount: 1).first else { return nil } return self.poemKeyFromLineKey(nearestLineKey) } -
33:29 - WordTagger
import CreateML let modelParameters = MLWordTagger.ModelParameters(algorithm: .crf(revision: 1)) -
36:46 - Using custom word tagger
func findTags(for string: String) { let model = try! NLModel(contentsOf: Bundle.main.url(forResource: "Nosh", withExtension: "mlmodelc")!) let tagger = NLTagger(tagSchemes: [NoshTags]) tagger.setModels([model], forTagScheme: NoshTags) tagger.string = string tagger.enumerateTags(in: string.startIndex..<string.endIndex, unit: .word, scheme: NoshTags, options: .omitWhitespace) { (tag, tokenRange) -> Bool in let name = String(string[tokenRange]) switch tag { case NoshTagRestaurant: self.noteRestaurant(name) case NoshTagFood: self.noteFood(name) case NoshTagFromCity: self.noteFromCity(name) case NoshTagToCity: self.noteToCity(name) default: break } return true } }
-