-
Ray Tracing with Metal
Metal Performance Shaders (MPS) harness the massive parallelism of the GPU to dramatically accelerate calculations at the heart of modern ray tracing and ray casting techniques. Understand how MPS accelerates calculations for dynamic scenes, and dive into practical examples for implementing soft shadows, ambient occlusion, and global illumination. Learn how to enable hybrid rendering applications, and explore new techniques to extend your app across multiple GPUs.
Resources
- Accelerating ray tracing and motion blur using Metal
- Metal Performance Shaders
- Metal
- Presentation Slides (PDF)
Related Videos
WWDC19
-
Search this video…
Good morning everyone. My name is Sean and I'm an engineer on Apple's GPU Software Team.
In this session we're going to talk about Ray Tracing. So, let's first review what Ray Tracing is. Ray Tracing applications are based on tracing the paths the rays take as they interact with a scene.
So, Ray Tracing has applications in rendering, audio, physics simulation, and more.
In particular Ray Tracing is often used in offline rendering applications to simulate individual rays of light bouncing around a scene. This allows these applications to render photo realistic reflections, refractions, shadows, global illumination, and more. Recently, Ray Tracing has also started to be used in real-time applications such as games. And this actually introduces some new requirements.
First, in real-time applications objects tend to move around. So, we need to be able to support both camera and object motion.
Second, performance is now even more critical.
This means that the ray intersection itself has to be as efficient as possible and we also have to make effective use of our limited ray budget.
So, we need to careful with our sampling strategies, random number generation, and so on.
Finally, even with these techniques we won't be able to cast enough rays to remove all the noise. So, we need a sophisticated noise reduction strategy.
Fortunately, Metal has built in support for Ray Tracing and Denoising. So, it's easy to get started.
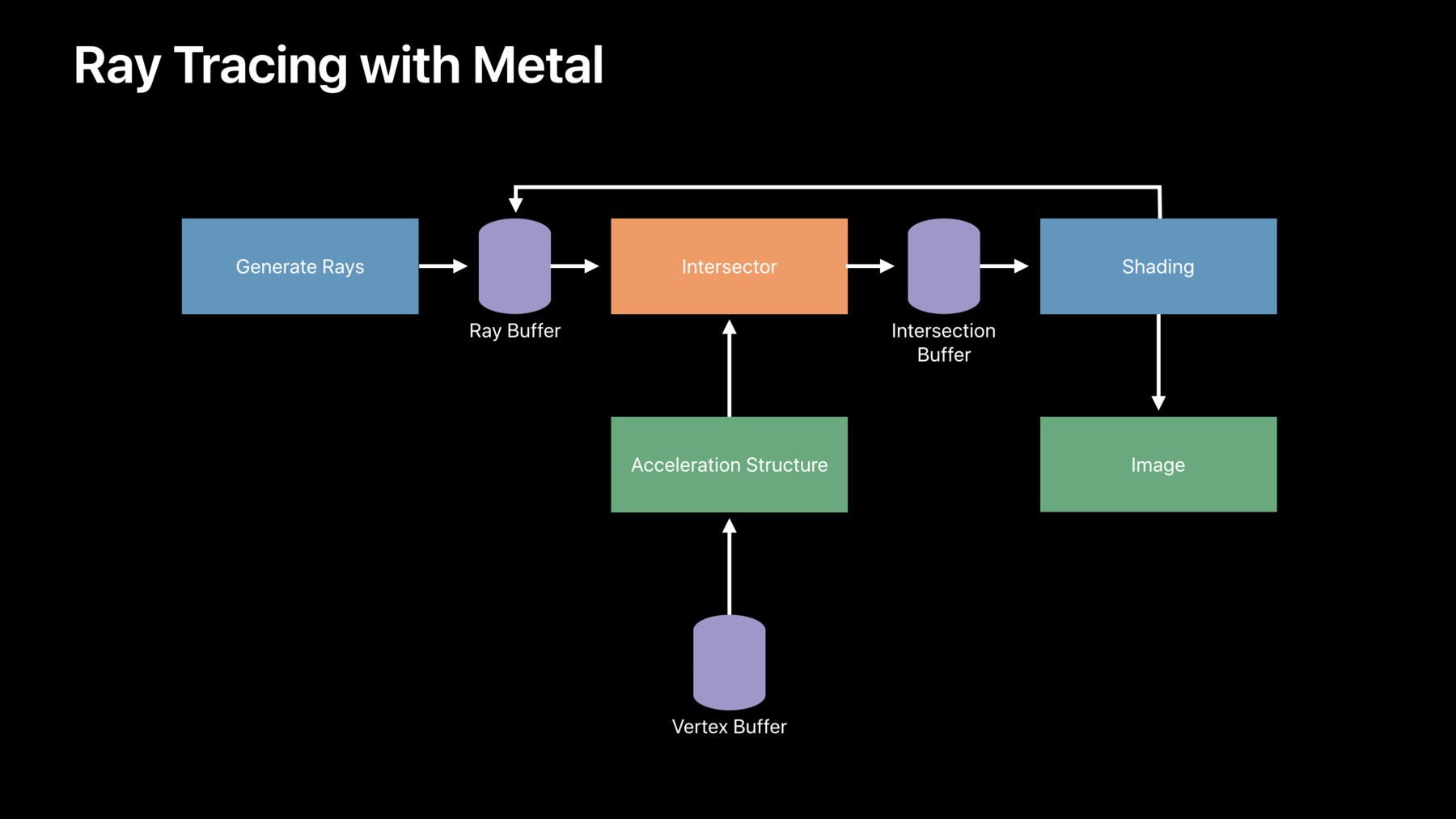
So, let's first review how Ray Tracing works in Metal and then we'll move on to some more advanced topics. So, if you look at a typical Ray Tracing application, they all follow roughly the same outline.
First, we generate some rays. Each ray is defined by its origin point and its direction vector.
Those rays are then intersected against the geometry in the scene, which is usually made of triangles. The intersection data could just be the distance to the intersection point, but it typically includes additional data such as the index of the triangle that was hit and the very center coordinates of the intersection point.
The next step consumes the intersection results. For example, in a rendering application this is typically a shading step which outputs an image.
And this step may also generate additional rays, so we repeat this process however many times we need until we're done. Applications typically intersect millions of rays with the scene every frame.
And this core intersection step is common to all Ray Tracing applications. So, this intersection step is what we accelerate in Metal. Last year, we introduced the MPSRayIntersector API, which is part of the Metal performance shaders framework.
This API accelerates ray intersection on the GPU on all of our Mac and iOS devices.
We talked a lot about this API in last year's talk, so we'd encourage you to go back and review this talk for more information.
At a high level, this API takes in batches of rays through a Metal buffer.
It finds the closest intersection along each ray and returns the results in another buffer. And all of this work is encoded into a Metal commandBuffer at the point in your application where you'd like to do intersection testing. Much of the speed up comes from building a data structure we call an acceleration structure. This data structure recursively partitions triangles in space so that we can quickly eliminate triangles which cannot possibly intersect a given ray during the intersection search. Metal takes care of building this data structure for you. All you have to do is specify when you'd like to build the acceleration structure, then simply pass it to the intersector for intersection testing.
Now, building this data structure is typically a fixed cost paid when your app starts up.
In last year's version of the API this data structure was always built on the CPU. This year, we've moved the acceleration structure build to the GPU, which can significantly reduce the startup cost. And even better, the GPU will be used automatically whenever possible. So, you don't need to do anything to see the speed up in your applications.
So, let's now revisit our typical Ray Tracing application and see what we need to do to translate it into a Metal Ray Tracing application. So, like I said, we'll start by generating rays.
This is typically done using a compute kernel, but it could also be done from a fragment shader or really any mechanism that can write to a Metal buffer.
We then pass the ray buffer to the intersector.
It'll find the intersections and return the result in our intersection buffer. And remember that to use the intersector we need to provide an acceleration structure.
We can often build this just one and reuse it many times.
Finally, we'll launch one last compute kernel which will use the intersection data to write a shaded image into a texture.
And this compute kernel can also write additional rays back into the ray buffer for iterative applications.
So, let's see how this works in a real application.
For this example, we'll talk about how Ray Tracing is being used in AR Quick Look. AR Quick Look was introduced last year and allows you to preview 3D assets in augmented reality.
We talked a lot about AR Quick Look in this morning's session. So, I'd encourage you to watch that talk as well. For this talk, we'll focus on how AR Quick Look is using Ray Tracing to render an Ambient Occlusion effect.
We'll talk more about Ambient Occlusion later, but for now, what you need to know is that Ambient Occlusion computes an approximation of how much light can reach each point in the scene.
So, this results in the darkening of the ground underneath the robot model as well as soft contact shadows between the robot's legs and the ground. The effect is somewhat subtle, but if we turn it off, we can see that it actually goes a long way towards grounding the robot in the scene. And this is really important for AR applications to prevent objects from looking like they're floating above the ground. In last year's version of AR Quick Look, the shadows are actually precomputed, so they wouldn't move as objects moved around.
This year, we've used Metal support for dynamic scenes to render these shadows in real time. So now as objects move their shadows will move with them. And this even works for deforming objects such as skinned models. We can see the shadows follow the motions of the fish as it swims around the scene.
So, what we just saw actually has three types of animation going on. If we were just using the rasterizer, we'd simply rasterize the triangles in their new position.
But because we're using Ray Tracing, we need to maintain an acceleration structure.
So, the first type of animation is simple camera movement. And this is movement due to just moving the iPad around.
We don't need to update the acceleration structure just because the cameras moved. So, we actually get this type of animation for free. We can simply start firing rays from the new camera position.
The other two types of animation do require updating the acceleration structure. So, the first is Vertex Animation.
This could be skinned models like the fish, but it could also be plants blowing in the wind, cloth, or other types of deformation.
Metal includes a special acceleration structure update mechanism optimized for cases like this. And the last type of animation is rigid body animation. This is where objects can move, rotate, and scale, but otherwise completely maintain their shape.
So, a large portion of the acceleration structure is actually still valid. So, Metal also includes a special mechanism to reuse the parts of the acceleration structure that hasn't changed.
So, let's first talk about Vertex Animation.
As the geometry changes, we need to update the acceleration structure.
We could rebuild it from scratch every frame, but we can actually do better. In Vertex Animation use cases objects tend to mostly retain their shape. For example, a character's hands will stay connected to their arms. Their arms will stay connected to their body and so on. So, the spatial hierarchy encoded into the acceleration structure is mostly still valid. It just needs to be adjusted to the new geometry.
Let's look at an example.
So, here's the acceleration structure we saw earlier.
If the triangles move, we can see that the bounding boxes no longer line up with the triangles.
But the tree structure itself mostly still makes sense. So rather than rebuild it from scratch, we can simply snap the bounding boxes to the new triangle positions from bottom to top. We call this operation Refitting.
As we can see, this still results in a valid acceleration structure, but it's much faster than building from scratch because we can reuse the existing tree. This also runs entirely on the GPU, which makes it even faster, but also means that we can safely encode a Refitting operation after say a compute kernel which updates the vertices. The downside is that we can't add or remove any geometry because the tree will still encode references to the old geometry.
This also potentially degrades the acceleration structures quality which can impact Ray Tracing performance.
This is because the triangles were originally partitioned using a set of futuristics which won't be accurate after the triangles move. The impact is usually minor, but extreme cases like teleporting geometry could cause performance problems.
Nonetheless, this works great for typical deformation and character skinning use cases. So, let's see how to set this up in code.
First, before we build the accelerations structure, we need to enable support for Refitting. And note that just enabling Refitting is enough to reduce the acceleration structure's quality. So definitely only turn this on if you really need to refit the acceleration structure.
Then we simple call encodeRefit into a Metal commandBuffer. And that's all we need to do for Vertex Animation.
So next, let's talk about Rigid Body Animation.
So as the name implies, this is animation where objects can move, rotate, and scale, but otherwise completely maintain their shape.
So, in the example on the right, even though it looks like the robot is deforming, actually all of its joins are moving rigidly. So, this is still an example of Rigid Body Animation.
So, in a typical scene, most of the geometry is probably only moving rigidly. In fact, most of the geometry is probably not moving at all.
We may also have multiple copies of the same objects in the scene. It would be wasteful to replicate these objects multiple times in the accelerations structure and it would also be inefficient to refit or rebuild the entire acceleration structure just because a subset of the geometry is moving.
So, to solve both of these problems, we can use what we call a Two-Level Acceleration Structure. So, what we'll do is first build a high-quality triangle acceleration structure for each unique object in the scene. And we can do this just once when the app starts up. We'll then create two copies of those -- of those triangle acceleration structures using a second acceleration structure. Each copy is called an instance of one of the original triangle acceleration structures.
Each instance is associated with a transformation matrix, describing where to place it in the scene.
So, we'll do this all using two buffers and each buffer will contain one entry for each instance in the scene.
The first buffer will contain the transformation matrices for all the instances.
The second buffer will contain indices into an array of triangle accelerations structures describing which acceleration structure to use for each instance. We'll then build a second acceleration structure over just the instances in the scene.
We can then quickly rebuild just the instance acceleration structure as the objects move.
So, let's see how to set this up.
First, we'll create what's called an AccelerationStructureGroup.
All the acceleration structures in the instance's hierarchy must belong to the same group. And this allows them to share resources internally. Next, we'll create an array to hold our triangle acceleration structures.
Then finally, we'll loop over all the unique objects in the scene, building a triangle acceleration structure for each of them. Adding them to the array as we go. We're now ready to create the second level acceleration structure. We do this using the NPSInstance AccelerationStructure class.
We'll start by attaching our array of triangle acceleration structures as well as the two buffers I talked about previously. Then finally, we'll specify the num of instances in the scene. Then, whenever the objects move or if an object is added or removed from the scene, we can simply rebuild just the instance acceleration structure.
This acceleration structure is typically much smaller than a triangle acceleration structure, so we can afford to do this every frame. But note that similar to Refitting, there is some overhead when using instancing.
So, if your scene only has one object or a handful of objects, or especially if none of the objects are moving, it might be worthwhile to pack those into a single triangle acceleration structure.
This will increase your memory footprint, but it should gain back some of the performance. So, you need to experiment to find the right tradeoff for your application. So that's it for dynamic scenes. We talked about how to support Vertex Animation and Skinning using Refitting. As well as how to support Rigid Body Animation using a Two-Level Acceleration Structure.
So next, let's switch gears and talk about Denoising. So far, all the images that we have seen have been free of noise. That's because they've all been using a denoising filter.
If we turn it off, we could see what it would have looked like without the denoiser.
We can see that these images are too noisy to use in a real application. That's because we're only using a handful of samples per pixel.
Usually we would just solve this by averaging together more samples over time. But if the camera or objects are moving it's not quite that simple. Fortunately, Metal now includes a sophisticated Denoising filter.
Let's see how this works. Ideally what we'd be able to do is simply take the noisy image output by a renderer, run it through a denoiser and get back a clean image. In practice, the denoiser needs a little more information about the scene.
We'll start by providing the depths and normal for the directly visible geometry.
Many renderers have these textures lying around, and if not, it's easy to produce them. The denoiser will then run a bunch of image processing operations and output a cleaner image. But since we started with just a handful of samples per pixel, the result will still have some noise.
So, we'll revisit the idea of combining samples over multiple frames. So, we'll first set aside the clean image to reuse in the next frame.
We'll also set aside the depth and normal so we can compare them to the next frame.
Then finally, we'll provide a motion vector texture which describes how much each pixel has moved between frames. In the next frame, the denoiser will churn through all of these textures to produce an even better image. And this image will continue to get better over time even if the camera or objects move. The denoiser will use the depths and normal to detect cases where the history for a pixel has become invalid due to an object moving or getting in the way.
So, this is all implemented using the MPSSVGF family of classes.
This is an implementation of the popular MPSSVGF denoising algorithm. This algorithm makes a good tradeoff between high quality and real-time performance. So, the denoising process is all coordinated by the MPSSVGFDenoiser class.
Meanwhile, low-level control is provided using the MPSSVGF class.
This class provides the individual compute kernels used by the denoiser and exposes many parameters you can use to fine tune the Denoising in your application.
And you also just call this classes' methods directly to build a customized denoiser. Now the denoiser creates and destroys quite a few temporary textures throughout the Denoising process. To the MPSSVGF texture allocator protocol serves as a cache for these memory allocations.
You can either use the default implementation or implement this protocol yourself to share memory with your own application.
So as usual, we've optimized these classes for all of our Mac and iOS devices.
The denoiser can process two independent images simultaneously. For example, you might want to split your direct and indirect lighting terms into separate textures.
There's also a fast path for single channel textures such as Ambient Occlusion or shadow textures, which is faster than Denoising a full RBG image.
Let's see how to set this up. So first we'll create the MPSSVGF object and configure its properties. All we need to provide is the Metal device we want to use for Denoising. Next, we'll create the TextureAllocator. In this case we'll just use the default implementation.
Then finally, we'll create the high level Denoiser object which will manage the denoising process.
So now we're ready to do some denoising. We'll start by attaching all of the input textures to the Denoiser. Now we simply encode the entire denoising process to a Metal commandBuffer.
And finally, we can retrieve the clean image from the denoiser. And that's all you need to do to enable denoising your applications. So, we now talked about all of the basic building blocks available in Metal for Ray Tracing and Denoising. We reviewed how to do basic ray/triangle intersection using the MPS Ray Intersector API.
We then talked about how to extend this to dynamic scenes using Refitting and Two-Level Acceleration Structures.
And finally, we talked about how to remove the noise from your images using the MPSSVGF classes. Now, don't worry if this is all a little bit overwhelming. We've written a sample, which demonstrates how to use all of these concepts which is available online. Now, I mentioned earlier that we need to be careful with performance. Especially in a real-time setting. So next, I'd like to bring out my colleague Wayne who will talk about how to make all of this work on real devices with real performance budgets.
Hi everyone. Now, what I'd like to show you in this part of the talk is how to use the Ray Tracing features that we have in Metal to implement a few different rendering techniques in your applications. So, in particular, I'll be focusing on hard and soft shadows, Ambient Occlusion, and global illumination. So, let's start with hard shadows. Now, the way that we model this with Ray Tracing is to take points on our surface and fire rays up in the direction of the sun.
If a ray hits something, then the associated point is in shadow. Otherwise, it's in sunlight.
Now, to incorporate this into an existing application, I'm going to assume that you're starting with something a bit like this. You've rasterized a G-Buffer and run a compute pass for your lighting. And the output of that is your final shaded image.
Now, to take advantage of Ray Tracing here we'll start by taking the G-Buffer and then run a compute shader to generate some rays.
We'll then pass those rays to Metal to intersect with an acceleration structure. And Metal will output the results to an intersection buffer.
You can now use this buffer in your shading kernel to decide whether your surface points are in shadow. Now the main part I'd like us to focus on here is Ray Generation.
So, let's start with a quick reminder of how rays are described in Metal.
So, Metal provides a few different ray structures for you to use, and at a minimum these contain fields for your ray origin and your ray direction.
So just fill out one of these structures for each ray that you want to trace and write it out to your ray buffer. Now, the way in which you arrange your rays in your ray buffer, that has a performance impact.
So, often you might start like this. We call this row linear order.
Now, the problem here is that as Metal works its way through these rays, they tend to hit very different nodes in the internal data structures that Metal uses to accelerate ray traversal. Now this in turn can flash the underlying hardware caches. So, a better approach is to use block linear ordering.
So, rays from nearby pixels on the screen, they tend to hit the same parts of your acceleration structure, and so by storing your rays like this it enables Metal to drive the hardware much more efficiently. Now, in the visualization here, I'm showing you a block size of 4 by 4. In practice we found that 8 by 8 works really, really well.
So, optimizing your ray storage is a great way to improve performance. But where possible, an even better way is just not to fire rays at all. Now, in the context of shadows, the reason that you might want to do this is because not all pixels need a shadow ray. For example, pixels on your background, on your skybox, or on surfaces that are facing away from the sun. Now, it's likely that your ray buffer contains a ray structure for each pixel on the screen. So, what we need here is a way to tell Metal to skip firing ways for the pixels that we just don't care about. Now, there's a few ways to do this. The approach I'm showing you here is simply to set the maxDistance field in your ray structure to a negative value. And that's the main things you need to know for Hard Shadows.
As you can see, Ray Tracing gives really great results. The shadows are very crisp and they're very precise.
But in reality, shadows cast by the sun, they tend not to look that sharp.
they look more like this.
They're soft around the edges and that softness varies with distance.
And you can see a great example of this on the left there.
the shadow from the lamp post starts off hard at the base and it softens as the distance to the ground increases. So, to model that with Ray Tracing, instead of using the parallel rays that I was showing you earlier, we'll instead extend the cone from our surface point all the way up to the sun.
And then, we'll generate some ray directions randomly within this cone. Now you can see there that some rays intersect geometry and some don't. And it's this ratio that controls the softness of your shadow. So, here's what that looks like.
What I'm showing you here is the raw direct lighting term ray traced with one ray per pixel.
So, in this image, all other effects such as reflections and global illumination, they're all disabled so we can focus purely on the shadow.
And as you can see, the result is really quite noisy. Now, to deal with that, we could just keep firing more and more rays. But since that's something we're really trying to avoid in a real time application, what we can do instead is use the Denoiser that Sean was telling us about earlier. And here's the results of that. Most of the noise is filtered away and we get these great looking soft shadows with just one ray per pixel.
And I'll be showing you this in action in our live demo later on. So now let's talk about Ambient Occlusion. So essentially, this is an approximation of how much ambient light is able to reach the surface.
And as you saw in our AR Quick Look demo earlier, it's a really great technique for grounding objects in their environments.
So, let's visualize how this works with Ray Tracing.
We have a surface point in the middle of the screen there and there's a blue block over on the right that's going to play the role of our occluder.
We define an imaginary hemisphere around our surface points and then we fire some rays. If a ray hits something, and we found that object is blocking ambient light from reaching the surface.
Now, as I've mentioned a couple of times now, in a real time application, we're really trying to limit ourselves to just one or two rays per pixel.
So, we need to use these rays as efficiently as we can. Now, one of the ways to do this is importance sampling. And the general idea here is to fire rays in the directions where we expect they'll contribute most to our final image. Now with Ambient Occlusion the most important rays are the ones closer to the normal.
So instead of firing rays evenly in a hemisphere like you see here, we instead use cosine sampling. Now, this distributes fewer rays around the horizons and more rays around the surface normal. And that's great. That's exactly where we need them. Now in addition to this angular falloff, Ambient Occlusion also has a distance term. So, objects close to the surface, they tend to block the most light. And there's usually a fall off function in there too, proportional to the square of distance.
Now, interesting thing we can do here is bake that fall off function right into the ray distribution itself.
And the way we do this is by firing rays of different lengths.
So, as you can see here, because of that distance squared fall off function I was telling you about, the majority of rays end up being quite short. Now this is great for performance. Short rays are much easier for Metal to trace through the acceleration structures. So, a couple of times now, I've talked about generating rays in various shapes and various distributions, such as the cones we were using for Soft Shadows and the hemisphere's that we're using for Ambient Occlusion. Now, the way that this works in practice is we begin by generating points in 2D parameter space and then we map that space with whichever ray distribution you want to use. Now the position of these points in parameter space can have a big effect on image quality.
If you choose them randomly, you tend to end up with regions where sample points clump together. Now this causes us to fire rays in pretty much the same direction and that's just wasting rays. You can also get areas without any sample points at all. Now this impacts image quality because we're undersampling the scene in these areas. So, a better approach to generate sample points is to use something called a low discrepancy sequence. So, the one I'm showing you up on the screen here is the Halton 2,3 sequence.
You can see that sample points generated in this way, they cover the space far more evenly and we vanish the void by plumping and undersampling. So that's how to generate good rays for a single pixel. And what we need to do now is scale that to generate good rays for all pixels on the screen. Now, the way that we're doing this is by taking one of those low discrepancy sample points I was just showing you and then we apply a random delta for each pixel. Now, the effect of that is that each pixel still runs through a low discrepancy sequence, but the exact positions of the sample points are offset from neighboring pixels on the screen. Now, there's a couple of different ways to generate these deltas.
One way is just to sample an RG texture full of random numbers. What we saw previously that random numbers aren't always a great choice for Ray Tracing. And an alternative that works really well for Ambient Occlusion is blue noise. So, you can see on the right there that the randomness is the blue noise texture, it's distributed far more evenly and that's great for image quality. Particularly when we're limited to just a couple of rays per pixel. So, let's look at the effect of all of this on the Ambient Occlusion result that we were trying to generate.
So, here's what we started with.
This is using hemisphere sampling and random deltas for all pixels. And this is what we get with cosine sampling and the blue noise that I was telling you about. So, I'll flip between these images so you can see.
Now, both of these images are generated using just two rays per pixel. But you can see by being selective about how we use those rays, the amount of noise is significantly reduced. And we've managed to capture much more of the fine surface detail. And if we were to keep firing rays, eventually the two approaches would converge on exactly the same image. But using importance sampling gets us there much faster.
So that's Shadows and Ambient Occlusion. And for these effects we were really only interested in whether our rays hit something or whether they missed.
Now, for many of the other effects that we typically associate with Ray Tracing, such as Global Illumination, you need to model your rays as they bounce around the scene. And to talk some more about that I'll invite up my colleague Matt.
Thanks Wayne. So, we're going to cover a few topics in this section, starting with a brief overview of Global Illumination. Then, we'll go into some best practices for memory and ray management. Finally, we'll cover some strategies for debugging your Ray Tracing application.
So, what is Global Illumination? Conceptually it's pretty simple. Light enters the scene and directly illuminates the surfaces that it hits. And rasterization, that's typically the end of the rendering process. But in the real world, those objects absorb some of the light and then the rays bounce off and keep traveling around the scene. And as they bounce around, some interesting visual effects emerge.
After light has bounced once we start to see specular reflections on the mirrored surfaces like the ball and wall to the right. You can also see that objects and shadows get brighter as they pick up light that's been reflected off nearby surfaces. After the light has bounced twice, we start to see reflections between mirrored surfaces and eventually, some rays have refracted all the way through transparent objects, and they're showing the surfaces behind them giving us the glass effect of the box. Now, if we tried to model all the light bouncing around the scene only a small portion of it would actually make it back to the camera and that would be pretty inefficient. So instead, we'll work backwards from the camera towards the light source.
We cast rays from the camera towards the pixels in our image.
The intersection points of those rays tell us what objects are visible. But we'll need to figure out how much light is reaching them in order to figure out what their color in the final image should be.
Earlier, Wayne described how to calculate soft shadows and here we're going to be performing exactly the same process.
We cast shadow rays from the intersection points towards the lights in the scene in order to approximate how much light's reaching them.
That's used as the light contribution towards the final image. Next, from the intersection points we cast secondary rays in random directions. We use Metal to figure out what those rays hit and then cast shadow rays to determine their direct lighting and then use that to add light to the final image. By repeating this process, we can simulate light bouncing around the room. We described this extensively in last year's talk, so I'll refer you to that for more details on how to go through this process. Our pipeline for this will look a little bit different than the hybrid pipelines that we've seen so far.
First, we set up rays and use Metal to find their intersections with the scene. Then, we write a shader to process the results of those intersection tests to tell us what surfaces we hit.
Then, we generate shadow rays from those intersection locations towards the lights in the scene. I'll write a shader to figure out which of those rays hit the light and then add their light to the final image.
Finally, we use the hit surfaces as the starting positions for our next set of rays. We repeat this process over and over again until we've modeled as many ray bounces as we like. So that's how Global Illumination works. Now we'll discuss some best practices that come up with memory for this programing model.
As any ray bounces around the scene. Its state changes depending on its interactions with the objects that it hits. For instance, if a ray hits a red material that surface absorbs everything but the red component of the light. So, the secondary rays that reflect off of that surface will only carry red light. So, we'll have to keep track of that information in order to pass it to the next iteration of our pipeline. That means we'll have to allocate a bunch of resources to keep track of ray and scene properties. To the right, I've listed a few examples of scene properties you may want to keep track of. With all these new buffers relocated we're going to be using a lot of memory. For a 4K image, the ray buffer alone would be 250 MB. In one of our demos, we're using almost 80 bytes per ray. And this approach can quickly exceed the amount of available GPU memory.
One solution to this is just to batch up your rays into smaller groups or tiles. And by restricting the number of rays that you're launching simultaneously you can drastically reduce the memory footprint of your resources. Because the data in these buffers is going to be passed between pipeline iterations, storing that data out and then reading it in, in the next pass is going to be a major limiting factor. For 4K image we're using over 8 million rays. And for that number of rays, we're reading and writing almost 5 gigabytes of data per pass. There's no one solution to every bandwidth problem, but we can give you some best practices that worked well for us. First, don't index into your data buffers randomly.
It's much more efficient if you can index by thread ID, so the compiler can coalesce all of the loads and stores since the memory the threads are accessing will be in adjacent buffer positions.
This is really going to improve your cache coherency.
Next, for variables where you don't need full precision, consider using smaller data types where possible. Try to use half instead of float data types for ray and scene and material properties if you can.
Finally, split up structs if possible, to avoid loading or storing data you're not going to use. For example, we have a struct that contains material properties. We get a nice performance boost by stripping out the transparency variables because not every ray hits a transparent surface. And we didn't want those rays to have to pay the penalty for reading and writing that data.
We're going to see a more concrete example of this later in the GPU debugging section. It might be counter intuitive, but it may be more efficient to allocate your own buffers to store origin and direction data rather than reusing the Metal ray buffer structs.
This is because the Metal ray buffers may contain extra data numbers that you don't want to have to load and store for every shader that may access the ray.
To maximize your GPU usage, you need to be mindful of your shader occupancy. Occupancy is a huge topic, so we won't go into it in depth here. But if you are getting occupancy problems the easiest way to improve it is to reduce your register pressure.
So, be conscious of the number of simultaneously live variables that you have in your shader.
Be careful with loop counters, function calls, and don't hold on to full structs if you can avoid it. When we process ray intersection points we need to evaluate the surface properties of whatever object a ray hits. And graphics applications typically store a lot of the material properties in textures. The problem here is that because a shader may need access to any texture that an object references, and we don't know in advance what object a ray is going to hit, we may potential he need access to every -- every texture that's in the scene.
And this can get out of hand quickly. For instance, the commonly used Sponza Atrium scene has 76 textures, which is over double our available number of bind slots. So, we'll pretty quickly run out of binding locations.
One way to address this is by using Metal Argument Buffers. A Metal Argument Buffer represents a group of resources that can be collectively assigned as a single argument to a shader.
We gave a talk on this at WWDC two years ago. So, I'll refer you to that for more details on how to use them. Assuming we have one texture per primitive, our argument buffer will be a struct that contains a reference to a texture.
Here, we've set up a struct that we called material that contains a texture reference and any other information we'd like to access.
Next, we bind our argument buffer to a compute kernel. It will appear as an array of material structs.
We read from our intersection buffer to find out what primitive the ray hit and then we index into our argument buffer using that index. That lets us access a unique texture for every primitive.
That covers our memory topics.
Now we'll discuss managing the lifetime of your rays.
As your ray bounces around the scene it can stop contributing to the final image for a variety of reasons. First, it may leave the scene entirely. Unlike the real world, your scene takes up a finite amount of space, and if the ray exits it there's no way for it to make its way back in. If that happens, we typically evaluate an environment map to get a background color, but that ray is effectively dead.
Second, as the ray bounces, the light it carries will be attenuated by the surfaces is interacts with. If it loses enough light it may not be able to have a measurable impact on the final image.
And finally, with transparent surfaces, there are some rays that can get trapped in position, such that they can never get back to the camera. So how quickly to rays become inactive? Well, depending on the kind of scene it can be quite rapid. For example, this scene has an open world and a lot of the rays will exit quickly by hitting the environment map. On the right, we're showing a simplified representation of a fully active ray buffer as it would exist for the first iteration of our pipeline. This is the step where we cast rays from the camera towards the scene. Some of those rays will hit the environment map and become inactive. Here, we've colored inactive rays yellow and we've removed them from the ray buffer.
After the first pass only 57 percent of our rays are still active.
When we let the rays continue traveling, some of the rays that initially hit the ground bounce up and hit the environment map. Now we're down to 43 percent of rays that -- left active. Now, some of the rays travel all the way through the transparent objects and eventually exit the scene. We've only got about a third remaining active.
And of course, the more we iterate, the more rays become inactive. In this example we know a lot of the rays in our ray buffer will be inactive, and anytime we spend processing them will be wasted. But because we don't know in advance which rays are going to be inactive, the Metal Ray Intersector and all of the shaders that process its results are still going to have to be run on all of them. That means we'll have to allocate thread group memory, the compiler may be prefetching data, and we may have to add control flow statements to cull inactive rays.
Our occupancy here stays the same, but our thread groups have become sparsely utilized. And we're wasting all that processor capacity. Our solution to this is to the compact the ray buffers.
For every pass we only add active rays to the next passes ray buffer. This adds some overhead, but it results in the cache lines and thread groups being fully utilized so there's less waste of processing and less bandwidth required. It's also important to note that this can be used for shadow rays as well. Some rays will hit surfaces that are pointing away from a light or they may hit the background. So, we won't want to cache shadow rays for them.
The downside is that because we're shuffling ray positions within the ray buffers, the indices in our ray buffer no longer map to constant pixel locations. So, we'll need to allocate a buffer to start tracking pixel coordinates along with each ray. Even though we're using extra buffers, we'll actually be using much less memory if we factor in all of the rays that we don't have to process.
When we're compacting the rays, we don't want two shaders to try to add rays to the new ray buffer at the same location.
Therefore, we need to produce a unique index into the ray buffer for every ray that remains active between passes.
We use an atomic counter to do this.
Here, the atomic integer outgoingRayCount contains the current number of rays in the new ray buffer.
We use atomic fetch add explicit to grab the current value of outgoing ray count and increment it by one. Using that value as the index into the outgoing ray buffer ensures that we don't get conflicts. It has the added benefit of leaving the number of rays that remain active in outgoing ray count. Now, Ray Compaction doesn't help you much if you can't restrict the number of threads that you're launching. The outgoing ray count buffer we just produced contains the total number of active rays in our outgoing ray buffer.
We can use that to fill out an MTLDispatch ThreadGroups IndirectArguments object.
That just specifies launch dimensions to be used with the dispatch.
Then, by using IndirectDispatch with that indirectBuffer object we can restrict the number of threads that we're launching to only process the rays that remain active. There's also a version of the ray intersection function that corresponds to this. The important point here is that we can pass our ray count via a buffer, so we can feed the result of our ray compaction step in as the number of threads to launch.
After Ray Compaction we get about a 15 percent performance gain in this scene. But of course, your results will depend on the complexity of the scene you're using and the number of ray bounces. So that covers ray lifetime and culling.
Now we're going to discuss debugging your application with Xcode. Debugging on the GPU is notoriously difficult process. And this is especially true for Ray Tracing.
Any change you make may get invoked multiple times per ray and you might have to write a lot of code to dump out buffers and textures for a bunch of different stages of your algorithm to get a clue about where an error was introduced.
Xcode's frame capture tools are amazing for debugging exactly these kinds of issues. It's incredibly powerful and a real time saver.
So, I'm going to walk you through debugging a real-world issue that we hit when we implemented super sampling in our ray tracer. We implemented the ability to sample a single pixel multiple times per frame and all of a sudden, our ray tracer is producing a blown-out image.
The first step is just to do a frame capture as your application is running.
This records the state of the GPU for every API call and shader over the course of a frame.
By selecting any shader, we can examine the resources that are bound to it so we can really quickly narrow down exactly what shader's failing by just selecting all of the shaders that write to the frame buffer and examining the frame buffer contents directly. So here we can see the first image is pretty light. The second image is pretty washed out. And the third is almost white. But here we're going to select the shader that outputs the lightest image and we're going to take a look at the two input buffers that we used to calculate the frame buffer.
And the first buffer just contains the sum of all the light a ray has accumulated.
The second buffer contains our new variable. And that's just the number of times we've sampled a given pixel.
Both of these buffers look like they have valid data in them, so we'll go directly to the shader debugger to examine what our shader is doing with this data. Our color calculation is just that some of the luminance for all the rays that were launched for a given pixel. When we only had one ray per pixel, this worked just fine.
But now, we're failing to compensate for the fact that we're sampling multiple times per pixel. So, we're going to change that code in the shader debugger to divide the total luminance by the number of input samples.
We reevaluate directly in the shader debugger and we can instantly see that our output image has been fixed. It's just that easy. Another issue we hit frequently was trying to understand the performance impact of our changes. Xcode frame captures tools make this easy as well.
Here's an example of a struct that tracks surface characteristics across ray bounces.
Not every surface in our scene uses transparencies. The final two values, transmission and index of refraction, won't be used for some rays. But, because we've packed all of that data into a single struct, rays that don't hit transparent surfaces are still going to have to pay the penalty for reading and writing those fields out between passes. Here, we've refactored the index of refraction variables into their own struct.
By separating the structs only rays that hit transparent surfaces will have to touch the refraction data.
But we can still do a bit better. Now we've changed all of our variables to half data types to save even more space.
We've reduced our memory usage from 40 to 20 bytes, and rays that don't hit transparent objects will only need 12 bytes. So how do we understand the performance impact of this? Here we grab GPU traces using the frame capture tool both before and after our change.
The most basic version of performance analysis we can do takes place at this phase.
By comparing the shader timings in our before and after captures, we can isolate shaders whose performance has changed. Here, we can see that the shader that we've labeled sample surface has gone from 5.5 milliseconds to 4 milliseconds. That's almost a 30 percent savings for one of our more costly shaders.
If we want to quantify exactly why we're getting a performance gain, Xcode helpfully displays the results of all the performance counters that it inserts when it does a frame capture. Because we're interested in how we've affected our memory usage, we can take a look at the texture unit statistics and we see that our average texture unit stall time has gone down from 70 percent to 54 percent. And we've reduced our L2 throughput by almost two-thirds.
Even more helpfully Xcode will do some analysis of its own and report potential problems to you. Here, it's telling us that our original version had some real problems with memory and that our new version's performing much better. One more tip that you may find useful, is that the compute pipeline state had some interesting telemetry as well.
Look at MaxTotalThreadsForThreadgroup. This is an indication of the occupancy of a shader. You should target 1024 as the maximum and anything less means that there may be an occupancy issue that you can fix. So that's debugging in Xcode. It makes developing Ray Tracing and Global Illumination algorithms on the Mac platform incredibly easy.
And now, here's Wayne to give you a live demo of all of this. Thanks Matt.
So, you may recognize this scene from our platform State of the Union session earlier this week.
To render it here, I'm using a MacBook Pro along with four external GPUs. And everything you can see on the screen there is being ray traced in real time. So, I can just take hold of the camera and move around the scene.
So, let's start over here. You can see these great shadows that we're getting with Ray Tracing. They're hard at the contact points and they become softer and softer as the distance to the ground increases.
And remember, for these shadows we're firing just one ray per pixel and then we're using the Denoiser that Sean was telling us about to get this great filtered result. And this is all calculated dynamically. So, I can just take hold of the light and move it around.
And I can see the effect of that pretty much immediately. There's a really great effect going on here too. If we fly over and look in the window of the tram here, you can actually see the reflections of our shadows, and again, you can see the shadow moving around as I take control of the light.
And if we head over to this part of the scene now, there's a really great reflection effect going on here. So, if we look at the left most tram you can see the reflection of the tram behind this.
But you can also see reflections in the windshield of the tram behind us. So, there's reflections within reflections going on here and we have to simulate a couple of ray bounces per pixel to achieve that effect.
So, I'm going to zoom out here a bit now. And of course, in this scene it's not just the camera and the lights that can move.
Sean was telling us about Metal's Two-Level Acceleration structures earlier. And we're using those here to enable the trams to move around the scene. What I really want to show you now though is this fantastic lighting effect we have going on up on the roof. So, if we focus on the wall on the right there you can see that currently it's being lit primarily by direct sunlight. But as I take control of the sun and I rotate it around you can see the wall falls into shadow and now it's being lit by this really great indirect illumination.
So, what's going on here is sunlight is hitting the roof on the left and it's bouncing and illuminating the wall on the right. Giving us this great color bleeding effect. And if I continue to rotate the sun you can see these really dramatic shadows start to come in and they travel across the surface of the roof there. If I spin the camera around a bit you can really see the reflections as well hitting the roof on the left. So, this is -- I really like this shot. There's a lot of Ray Tracing effects all going on at the same time here. We have the indirect illumination, we have the shadows, we have the reflections. And it's all being ray traced in real time with Metal and multi GPU.
So, I'm going to switch back to the keynote now and it's this multi GPU aspect that I'd like to talk a bit more about.
So, for the demo that we just saw, the way that we implemented multi GPU was by dividing the screen into a set of small tiles and then we mapped these tiles onto the different GPUs. Now in the visualization here I'm using different colors to show you how the tiles are distributed. So, one GPU renders the tiles in red. Another does the tiles in yellow, and so on. And after all GPUs are finished, we just composite those results together to form our final image. So, if we take a step back and look at what we have here there's two things that jump out. So firstly, in the image on the left, so the way that we're assigning tiles to GPUs, it looks a bit strange. So why are we doing it like that? And secondly, for those small tiles the implication of that is that each GPU is going to render a block of pixels there and then a block of pixels somewhere else.
And that just feels like it's going to be bad for things like ray coherency, cache hit ratios. All that kind of stuff.
So, let's deal with these in turn. So, imagine we have four GPUs. The simple way to do multi GPU here is just to split the screen into quadrants.
Now the issue with that is that some parts of a scene will be much easier to render than others.
So, if we assume that the street and the building on the left there are much easier to render than the tram on the right.
It stands to reason that the red and yellow GPUs will finish before the green and purple GPUs. Now we can fix this just by splitting the screen into smaller tiles. Then we can split each of those into smaller tiles and so on. Until we reach some minimum tile size. Now this has the effect of distributing work really evenly across the GPUs. So, if one part of the screen is particularly difficult to render, it just doesn't matter, because every GPU will be assigned tiles from that part of the screen. Now in practice, this regular tiling pattern that you see here probably isn't the way to go. Because you can get cases where the tiling aligns with the geometry in your scene.
And so, we randomize a bit. And I'll give a few more details on how we're doing that in a second. And one of the really interesting things about this approach is that the mapping of tiles to GPUs, it does not change.
So, the same GPU will process the same tiles every frame. And this is great. So, you can just calculate that mapping when your application initializes or when you resize the window and that's it. You don't need to think about multi GPU load balancing anymore and there's nothing to monitor. Nothing to recalculate in your application's main loop.
So, if we know that small tiles distribute the work more evenly, why not just take it to the extreme and make them a pixel. So, the problem with that is that we need to give each GPU nice coherent blocks of pixels to be working on.
So, the tradeoff there between balancing the load evenly and making sure that each GPU can run as efficiently as possible. So, to better understand that tradeoff we did a simple experiment. We took one of the new Mac Pros with a pair of the Vega II Duo GPUs, so that's four GPUs in total, and we tried rendering the same scene with various tiles sizes to see how that effected performance. Now of course, your mileage may vary here, but what we found is that the performance window is actually really wide.
So, efficiency drops off if you make your tiles very small or if you make them very, very large.
But anywhere in the middle keeps us pretty close to peak performance.
So now we have our tile size pinned down, what we need to do next is assign them to the various GPUs. Now to do this, we start by generating a random number for each tile and then we compare those random numbers to a set of thresholds.
And whichever range the random number lands in, that gives us the GPU to use for that tile. So as an example, here, if the random number is .4, we assign it to GPU 1.
If it's .55, it goes on GPU 2. And so on.
Now, once we've done this for every tile the output is a list of tiles that we need each GPU to render.
As you can see down the bottom there the ranges that we're using for each GPU are equal.
So, when assigning tiles to GPUs they are all equally likely to be chosen. But in practice, you almost certainly don't want this. For example, you might need to reserve capacity on one of your GPUs for non-ray tracing tasks such as denoising or tone mapping. Or you might be using GPUs with different performance. In which case you'll want to send more tiles to the more powerful GPUs.
And you can account for this really easily by just adjusting the ranges.
So now if we go ahead and reassign the same tiles we used before, you can see here that now GPU 2 takes on a much greater share of the work. Now, for the actual implantation of this there was a lot of really useful information in our Metal for Pro Apps session earlier this week. So, I won't go over that again here. But it is definitely useful to highlight just a couple of areas that can have a really big impact on performance. So firstly, you'll probably want to composite your tiles together on the GPU that's driving the display.
So, it's important to find out which GPU that is and then work backwards to figure out how to get your data there efficiently. So, if the GPUs are in the same peer group then you can copy between them directly using our new peer group APIs.
Otherwise you'll need to go by the CPU.
Now secondly, it can often take a few milliseconds to copy data between GPUs and we definitely don't want to block waiting for those transfers to complete.
So, to give you an example of how we're dealing with that we have two GPUs here and we're using the tiling scheme that I was just talking about to spread the rendering across the two GPUs.
Now in GPU 0 at the top there we have two queues. One is just flat out doing back-to-back Ray Tracing. And then we have a second queue that copies the completed tiles over to GPU 1 asynchronously.
Now, we'll assume that GPU 1 at the bottom there is the one that's driving our display. And here things are a bit different. This GPU is also Ray Tracing part of frame 0, but we can't go ahead and present that frame until the rest of our tiles have been copied over from the other GPU.
So rather than wait, we just start work on the next frame.
And then a bit later on when our tiles arrive from the other GPU, that's when we go ahead and composite everything together.
So, I'll show you that one more time here. So, you can see that we end up in this steady state where we render frame N and then we composite frame N minus 1.
So essentially, what we're doing here is latency hiding.
And this together with the tiling scheme I was showing you to load balance between the GPUs, this is enabling us to achieve really great performance for our Ray Tracing workloads on our multi GPU systems. And with that, we come to the end of the talk.
We began with a quick refresher of how Ray Tracing works in Metal and then we focused on a few features of the MPSRayIntersector that are there to really help with dynamic scenes. So that's the Two-Level Acceleration Structures along with our GPU Accelerated Rebuilds and Refitting. We also introduced the new Metal Denoiser. And then we talked through a few Ray Tracing use cases such as Shadows, Ambient Occlusion, and Global Illumination.
When then showed you how to debug and profile Ray Tracing workloads using Xcode. And then, we finished by talking about how to take advantage of multiple GPUs in your Ray Tracing applications. Now, for more information be sure to visit developer.apple.com and there you'll also find a new sample demonstrating some of the features that we've talked about today.
If you're new to Ray Tracing be sure to check out our talk from last year. And finally, we have our lab session coming up next at 12. So, I hope you can join us for that.
So, thank you all for coming and I'll see you in the lab shortly. [ Applause ]
-