-
Text Recognition in Vision Framework
Document Camera and Text Recognition features in Vision Framework enable you to extract text data from images. Learn how to leverage this built-in machine learning technology in your app. Gain a deeper understanding of the differences between fast versus accurate processing as well as character-based versus language-based recognition.
Resources
- Structuring recognized text on a document
- Extracting phone numbers from text in images
- Locating and displaying recognized text
- Presentation Slides (PDF)
Related Videos
WWDC21
WWDC20
WWDC19
-
Search this video…
Good afternoon. My name is Frank Doepke and I'm going to talk to you about Text Recognition in the Vision Framework. Now, for those of you who are familiar with Vision, you'll know that we already had the VNDetectRectangleRequest that tells you where there is text in an image.
For some mysterious reason, we always got the question, "What is the text?" So, we needed a little bit of extra code. It arrayed over your results, and then you need to train basically a Core ML model that actually can read this stuff.
Next, you run the Core ML model. You filter out the bad characterization. You take all these characters, put them into a string, and then come up with some heuristics that actually form the really sentences and words out of this.
So now you know why we need a full session to talk about Text Recognition. But today, I want to make this easier.
And we have something new, and that is the VNRecognizedTextRequest. And just that little bit of text that you see here , this allows you to take you from an image like this into recognized text like this. Thank you.
Okay, so what are we going to cover today? First we're going to talk a little bit about how Text Recognition works.
We have a number of example applications and they're also all attached to the session so you can download the sample code.
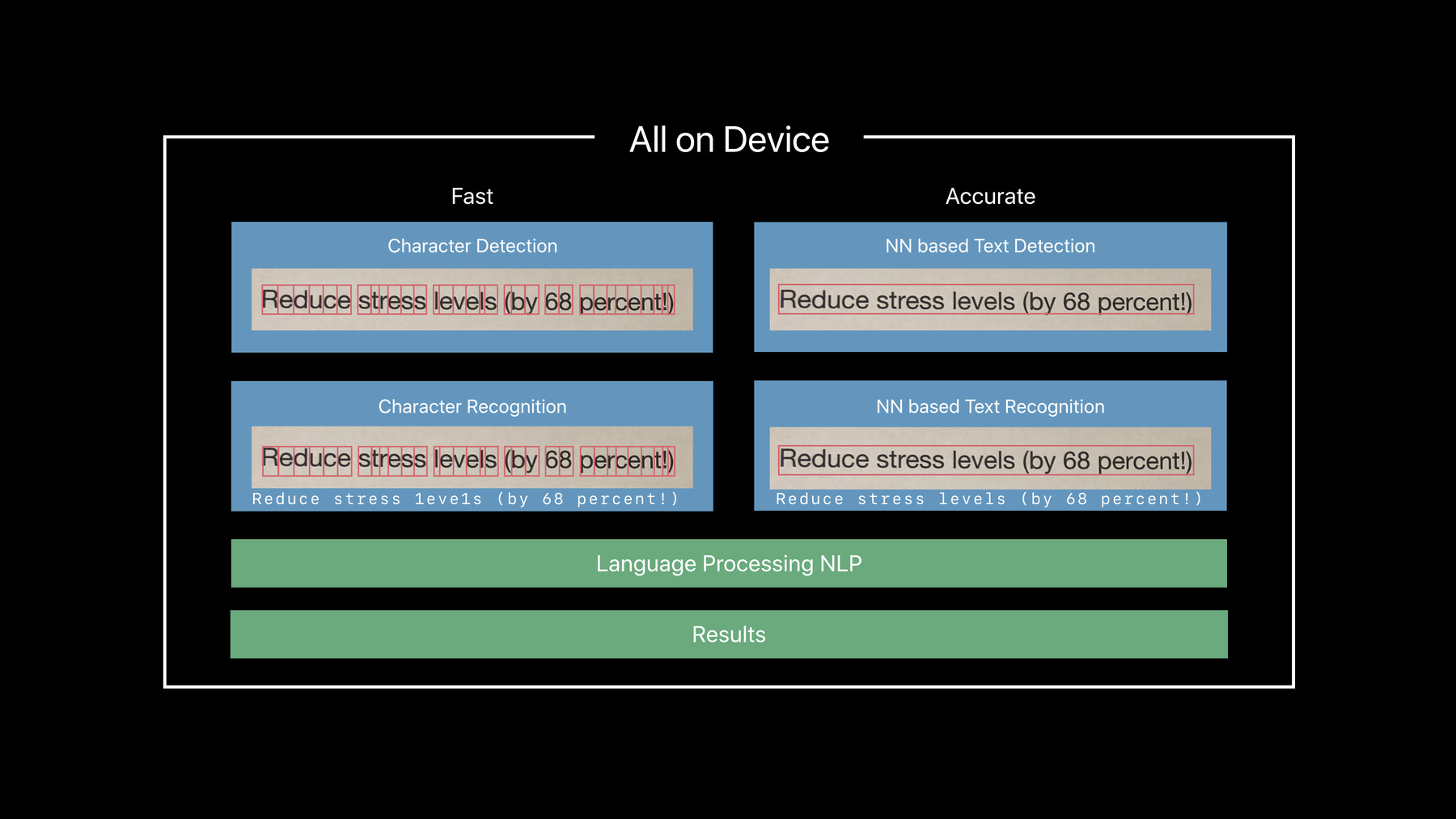
And last but not least, we're going to go over some best practices on how to use our Text Recognition. So, how does Text Recognition work in Vision? We have two paths to choose from. The fast path, and the accurate path.
The fast path works just actually on what Text Detector did before by finding characters and then advance a small machine learning model to actually recognize those characters, character by character.
The accurate path, on the other hand, uses a state-of-the-art neural network to recognize text by first finding it in terms of strings and full lines.
And then recognizing it as words and sentences.
So, it requires a deep learning model which will take a little bit more time to compute, but it reads much more as we humans actually read our text.
We don't read character by character. We look at words. And this helps us to get about, you know, there are certain characters that might be a bit like, you know, hard to read. And this is also the same reason when we try to proofread our text, that we don't see typos, because our brain interpolates over some of these mistakes. And we use the same kind of technique here in the accurate path to help us get past some of the recognition errors.
Both stages afterwards can actually go through a language correction phase which helps us to again eliminate some of the typical misreadings.
And out we get our results. So, this is a complex machinery, you might think. But all of this happens on the device.
So, let's look at what the difference is between fast versus accurate.
So, I did a little screen recording of reading this document. And I did this on a relatively old MacBook Pro. So, the times that you see are not necessarily representative, but I wanted to give you a feel. So let's look first at how fast is fast.
And we're done. Now, let's look at how long does accurate takes. And you see the progress? It took a little bit longer. And as I said, the numbers are not representative for everything, but it gives you a feel of the delta.
The other part that you see is that accurate is actually much better in reading the whole text. The fast path has a little bit of a problem with the stylized font on the top.
So there are some tradeoffs between these two paths. Let's look at these tradeoffs. The fast path is meant for real-time reading and it's optimized for that. But the accurate path is more likely to be used in an asynchronous fashion. In terms of memory budget, the fast path also uses less memory because it doesn't need to run a large neural network.
But when it comes to rotated text or perspectively misaligned text, the accurate path gives you much broader support.
And when it comes to style or fonts and as you saw already in the example, when it comes to stylized text, there's again much broader support in the accurate path.
And last but not least, when it comes to the real reading of natural language, the accurate path is what we would recommend because it performs best on that part. So, how do you choose between those two? The use cases that you have are the important part that will actually drive how you want to use the request.
You need to think about a few things. So, what is my input? Am I working off a camera or do I already have images from my photo library that I want to process? What are my processing constraints? So, how much time can I spend on the request? And how much memory do I have available? Some of the processes might be a bit more memory constrained. And last but not least, what am I going to do with the results? Am I using them to transcribe? Or for search? Or just do a, perform an action based on what I read through the camera. So, let's talk about the camera capture in a few more details.
The camera capture can be used as a live capture. So, you actually want to use now the string reading live and keep up with the frame rate. In this case, the fast path is most likely the one that you want to use. But there's also the way of opportunistic capture. What do I mean with that? It's like for instance you take a photo and there's text somewhere in the photo and you want to process that. So, you don't need to keep up with the frame rate of the camera, but you actually want to use this to read the text and the accurate path will most likely give you better results.
One more thing to think about when we talk about camera is I need to design which resolution do I want to use in my application, and the text size will actually drive this. If for some mysterious reason you want to read the fine print of a legal document where you might actually have to increase the resolution of the camera, or when you read a billboard with large text, you can actually turn down the resolution and work with less memory it actually will be faster as well.
Now, when it comes to post processing, so we already have the image in a file.
Most likely you want to favor the accurate path, because you can actually use the better accuracy and speed is not as important.
Next, let's talk a little bit about language processing. As I mentioned, language processing is one of the stages that you can use in the text recognition.
It helps us to get past some of the typical missed readings that can happen when you read the text, but it can also get in the way. When I want to read codes or a serial number, think of the serial number like C001 that can very easily be misconstructed as cool.
Also, this language correction does not come for free. It does take some processing time and of course it uses a little bit of memory.
So now that we have some of the fundamentals out of the way, let's talk actually how we can perform Text Recognition.
Everything in Vision starts with an image RequestHandler.
Then I create my request. I set my completionHandler on it; that's where actually I deal with the results. Then I set the recognitionLevel. As I said, I can switch between the fast and accurate.
Next, I would recommend that you actually set the revision. The revision, of course here there is only one, but down the line we will come up with improved versions and you might have tuned your algorithm to a specific behavior that we have. And if you otherwise don't specify a revision, you will always get the latest and that might appear with some surprises.
So, I would recommend getting to the behavior of using a revision. And I can turn on and off the language correction and last but not least, of course, I need to perform my request.
When we perform it, and we get our results back.
These come back as VNRecognizedTextObservations, and we get them pretty much in terms of lines and strings that we find.
So, we need to iterate all of these results. And when we want to get the text out, we actually have multiple candidates. We'll talk about some of the candidates later. Here to make it simple, I just get my top candidate and I have my text. And I can get to the bounding box which actually helps me where all this text is on screen or in the image, the image onscreen.
But now when I want to use search, and so for instance the user types in a word that you read in the document, and we want to find actually where is this again in the image, I can actually ask the candidate for where is the bounding box for this string that I actually see in my results.
Now, after all this theory, let's go into some example, and we want to do some real-time Text Recognition. So, that's when we want to use the fast path. The use case here is I want to read something like a serial number or a code. The serial number that I'm using here actually is a phone number because it's the easiest for everybody, easiest to understand here. And I want to read them really just like a barcode reader. With that, I can constrain actually how the camera should actually look for the text, but interactivity is key because it should be snappy. It should be fast, so that the user can be guided, and it reads the text right away.
So, that's why I'm choosing the fast path here. And with that, let's look at the demo.
All right. The sample code that I have here and which as I said is also attached to this session, allows me to read phone numbers. So, when I'm scanning over this text here, you see a little white box. That means I find text, but I'm not reading it because it's not a phone number. Even the zip code here.
But the moment I find a phone number, it reads it and stops the scanning. Let me show that once more.
You see it feels interactive. It's easy for me as a user to use this, even though my hands are shaking here.
So, how does this look in code, because that's what's really interesting part here.
So, I start by creating my text request.
And as I said, I'm going to use the fast path here. I disabled the language correction because I know I'm looking for codes. I'm not looking for natural text. And then I'm using the regionOfInterest. Now, this is a concept envisioned and generally available. You'll notice that in my app I have this little box that kind of guides the user of like where he wants to frame the text, but I also use this area as my region of interest which crops Vision to only work on that specific subject. That helps me to A, get rid of all the noise that's surrounding it and because it's less data that I have to process, it enhances the performance. So, now I have my request and I'm using an AVCapture session here.
So, my capture output, all I have to do is that I get my image from the session, create a RequestHandler, and perform the request. And then this is mostly the drawing of the boxes. That's not the interesting part.
The interesting part happens in our string utils. As I said, we turned the language correction off. So, I'm now left on my own to kind of correct some of those results, but I can do this because I actually have intrinsic knowledge of what I need to solve here. And I know I'm looking for phone numbers, and this means I know I'm not looking for any characters. I'm only looking for numeric paths. So, I can simply say if it reads something like an S, which would be a 5, or if I get an L, this should be a 1, I'm using my domain knowledge of kind of correcting for some of the typical mistakes that can happen.
So, that's helped us to not probably get any characters through, but then comes the next part.
How did I difference it between zip code and a phone number? Well, I knew the structure. The structure of an American phone number is very simple, and I'm using that knowledge again to filter out results that I don't want.
Last but not least, let me find this as well, is our string tracker. And now I'm using a little trick here. If you ever dealt with reading something live from a camera feed, you will realize that very often from frame to frame you get different results. They slightly fluctuate because of noise, lighting and so on.
But it would be bad if I flicker out the wrong phone numbers. So, what I try to avoid is to show incorrect results. What I'm using here is a technique where I actually look over multiple frames and build evidence over time. This building of evidence over time means I simply store the phone numbers and at the very end, all that I'm doing is very simple. If the same number showed up in 10 consecutive frames, I know I've read it and actually propagated up to the user. Now, 10 was an empiric number that we picked, but it worked really well for us. And with that, I basically filter out all the noise that I would otherwise have. And that is all that we needed to do to get our demo to run. Let's go back to the slides.
So, let's quickly recap. I use the fast path to keep up with the frame rate of the camera. I was able to guide the user how to use the camera. I use the region of interest to crop down to really what I only want to read to get rid of the noise surrounding it and enhance the performance. I turned off the language correction because I knew I'm reading actually code. And I use my own domain knowledge, and this is like the same thing as you as app developers would do of this phone numbers to actually read them correctly. And last but not least, I use this building of evidence over time to actually help to reduce some of the noise.
Next, I would like to introduce the Document Camera.
The Document Camera was already introduced two years ago by Notes. And it's a really great companion when you don't need to use a live stream to capture. This year, you've seen it in Notes, Mail, Files, and Messages. And it already is perfect for reading a document. Because as you can see here, it finds the document, crops it out, and now I could just simply pipe it into my text recognition request. This is a great companion because what it does is already just a prospective correction of these scans for you and it evenly lights also the image. That makes it much easier to process afterwards.
So, how does this look in code? First, I need to bring in VisionKit as this is a new framework and then I create the VNDocumentCameraView Controller.
I present it on the screen and my camera is running.
So, once the user is done, in my delegate I get the results back. Now, there's one thing to keep in mind. We can actually scan multiple documents at once, so they come back as pages.
From each of them, I simply take my CG image and pipe them into my Vision Request, and I get my results out of it. And now to get to some of the best practices, I would like to introduce my colleague Cedric Bray onstage, who will give you some more information about that. Thank you. Thank you, Frank. I am super excited that we have Text Recognition coming into the Vision Framework this year. And to help you take best advantage of this new API, we're going to talk about best practices.
So, in this section, you will learn about language knowledge, how to leverage language knowledge for getting the best results. You will learn how to tune for better performance in your application. And you will learn a bit more about how to process your results in the most effective way.
So, the image that you are processing maybe are in a language that you have identified. And if there are, in this particular language, then you want to take advantage of this information. To do so, you enable language-based collection. First you have to set the language that you are targeting. For this we will support English. And once language-based correction is enabled, it will improve the transcription of the results by using on-device language models. On-device language models are great. They have large generic coverage.
But you may have domain-specific words, domain-specific vocabulary like medical terms or business-specific codes or references that appear in the documents. And so we can, you can specify this information, this vocabulary, by passing a custom lexicon to the Text Recognition request.
When you do so, this custom vocabulary will complement the language-based correction to give you the correct transcription, even in cases where the images are more challenging.
So, let's see how this looks in code.
First, a prerequisite, you need to check the languages that are supported by language-based correction.
And so this list of supported languages is defined for a combination of recognition level and for the API version that you are targeting.
Enabling language-based correction is simple. Just set the corresponding property to true on the Text Recognition request. Initialize custom words. You can specify this list of words as an array of strings that you pass to the custom words property on the text recognition request.
So, this is great for optimizing for accuracy, transcription accuracy. But what about performance? And there's a very common case where you're probably not interested in smaller text that is in the image. So for that case, we recommend that you adjust the minimumTextHeight. And the way it works is that when you set up these minimumTextHeight, all text that is smaller than the height that you specify will be ignored. It won't be processed. It won't be part of the results. And the input image will be downsized, and the execution time will be smaller. Recognition will go faster. And the memory usage will go down.
One important note about this property is that it is expressed as a fraction of the image height. As you can see in this example. If I said 0.5, it means that the text that is bigger or same size as half of the height of the image will be returned. So, this is a case when you want to make text recognition faster.
But what if text recognition is not the highest priority task in your application? Maybe you have other higher priority tasks to run, like an ARKit view running in foreground might be the case for you in your app. Or Cam AR Frames that you are running and processing in real time. So, in the case of background task, we allow you to run text recognition on the CPU only, so you can leave GPU resources and optionally the neural engine, to higher priority tasks for your application.
You do that using the usesCPUOnly property. It's a property that is available for other VN requests, for all other VN requests and Text Recognition support that as well.
So, that's the case when you will have Text Recognition running slower on purpose. But there are also cases where the image is just very big and there's a lot of text and Text Recognition will be, will take longer and your user might be confused unless you provide progress management. And we highly recommend that you focus on progress management in your application. This is a new concept in Vision for this year and Text Recognition fully implement that. It comes in two ways. First, you can set a progressHandler on your request.
And when you do so, you get the progress ratio as in true parameter in the progress handler.
And you can also support cancellation in your app. For example, if you want to provide a button to the user so they can cancel a Text Recognition that's running in front of them. So, that's a bunch of concepts and to illustrate them, I would like to show you a demo of a sample app that we're making available with this session as well. It's called My First Image Reader. So, let me give you a tour of this app.
So, as you will see with this sample code, My First Image Reader as the main window. As you can see here. And a transcript panel. The main window will show the image and the geometry of the results. The transcript window will show the text. If I take a closer look at the top of this window, at the toolbar, you'll see that you can choose between accurate and fast. So, that's in fact a very nice, simple app for you to experiment with this mode. But also with other setting that we have just talked about. Performance setting, minimum text height, I'll get back to that later, and in this view, you also have access to the language settings, setting, enabling the language model, sorry. And the custom words. Let me show you quickly with a crafted example how this looks like.
If I take one image that I created and say that's a book cover and happens to have very small text and happens to be my name.
You see that you get very small text, my name here, located and recognized. And same obviously for the very large text.
Now let's say I have a bunch of those and I just want to index the titles of these images. I wouldn't care so much about the small print, in particular my name on it. So, I will adjust the minimum text height to make the recognition run faster. You can just set it to 0.1, so the text has to be at least 90 percent of the image height. And that's the case for the large text, Desert Dunes, here. So, setting these back to 0, let me show you the language settings, in particular the impact of custom words.
If I drag this flyer here, it's for a project called Hill Side. It also has a probable number, which is a reference number. It happens to be HI11. So, there's possible confusion here. So, let me show you the transcription results.
You see that the code is in fact misrecognized here.
So we're changing. So if I specify HI11 as custom word, because it's part of my known references, then the custom, the list of custom words and this one in particular we complemented by this correction and give us the correct transcription for that reference.
Back to the slide. Thank you. So, quick recap.
You need to choose the recognition level that is the best fit for your use case for your application. Fast, accurate, it needs to be the right one.
For the language settings, we recommend that you check based on the type of documents that you have. If there's an obvious language, a neighbor languages correction, and if you have a domain-specific vocabulary, enable custom words, specify your custom words.
And also, very importantly, you need to support progress update in your app for the best user experience.
Now, even if you follow this recommendation, there's still one very important aspect to be aware of.
You need to process your results and you need to provide a recipe, have your own recipe for presenting your results to your users.
And the recipe you want to have is probably not alphabet soup.
What I mean by that is that you need to process your results in the most effective way for the best user experience.
So, let's check how to do that.
One very important statement first. You should expect ambiguity in the input.
This is computer vision. This is an open-ended problem. And our terms of excellent parameter that will influence the content of the images that you are processing. In fact, the case of house number is quite interesting here.
Because some of them are very stylized. And when you run the generate Text Recognizer on those, it has no clue that they should be numbers, right? And instead of getting 101, you get lol or you might get the ASCII art for the happy guy raising hand, meaning this case.
So, in that case, have you heard it before but we're insisting on that you need to leverage the candidate list, the list of top candidates that you have for, from the observations. So, take this candidate list and if it makes in for your application, take a look at this top one, top two, top three results or more. There's a typical example where you want to index the content of the images and so if you want to increase the recall, you can index more candidates for each of the results. Of course, at the cost of precision. Right? So, this candidate list, we need to dive into that, but that's just one dimension. That's the scale of prediction confidence. What about other dimensions? What about image space? We recommend that you evaluate and in fact reconsider using the geometry to map your results.
You have the salvation bonding box. It gives you spatial information and you can map these results together using the position, the scale of the results, but also the rotation. And the example that we are showing here, in case, in the case of the receipts, you can probably map the item name to the price.
So, that's for the geometry. But for each result in isolation, you also have the opportunity to use parsers and try to make sense of each of these results in isolation. And in this case, Data Detector is your best friend. It's initiate NSDataDetector for the types that you're interested in. As you probably know, it supports addresses, URLs, dates, phone numbers.
In the example of my business card, I can use that to make sense of some of the results. But if that's not sufficient, then you can obviously use your own domain-specific features, have your own vocabulary that you match the strings against, or use your own regular expression.
So, to illustrate these principles, we have another sample app, an iOS app this time, called Business Companion.
In fact, if you're sitting in this room because you have the idea receipt scanner. Receipt scanner, anyone? Maybe? Or a business card reader? People interested in business card? Then this app is something you really take a look at, because it mixes the two flows into the same app flow. Let me show you how.
First, it has document category picker. It gives you some - You see soon how it works, It is just the first screen. That way you pick the document type you're interested in. And from there, you go to the Document Camera that you heard about before. And from the Document Camera, we run text recognition and from the recognized result, we perform some analysis to make sense of these results, and that's what really matters here. Because based on this analysis, we'll be able to get some data model for receipt business card. In this case, we have a fall back on the type of documents. And from this results analysis, given that you make sense of the data, you can also visualize the result more appropriately in the case of the receipt which shows to display in a table view. And if we have a business card, we show mini contact card. So, let me show you this app.
Switching to the iOS device here.
So, this is Business Companion, and as I was telling you, we have here a choice between receipt, card, and other type of document. Let's just start with receipts. And first the Document Camera. We have some challenging light in here.
As the document gets captured and processed, yes, our results structured. You see the item name. You see the category names and the value for each section. Now, if I look at a business card.
Similarly I get each field of the business card analyzed , and this is my mini business card. Thank you.
Like I said, this is nice but look at this front screen. You still have to choose manually the document type. It's not really seamless. You can make that more seamless, right? Actually, we've done that. And I'm going to show you a better version of this app. It's called Better Business Companion. And what we've done, in fact, is that we've trained a classifier model using Create ML and we're using this classifier as a first step so that you don't have to specify the document type. It will be selected automatically. Enough talking. Let me show you.
So, very obviously, first button, big button, very small button.
You only have the scan button here and you can see that similarly I get my receipt here.
Get processed as a receipt without having the user specify the document type.
Just to show you how it works with business cards, with my business card again.
And yes, we get the business card correctly processed. So, I told you we integrated the Core ML model for this but I would like to show you how.
So, let's go into Xcode here and this is the code, in fact this is the code we modified from Business Companion. And we added the insertion of a Core ML model that is actually here.
So, we inserted this Core ML model to set out the request with a completionHandler. And as part of the handler, you see that we processed the top observation and date of the identifier, sorry, of this top observation. We set up the scan mode for the application that will determine the flow for the rest of the app. So, we encourage you to think about how you can improve your application flow using Text Recognition but, and processing the results appropriately but also leveraging ML models, like this. All right. Back to the slides. Just for a quick recap.
As I mentioned, we encourage you to use geometry information when it makes sense. Parse your results, make sense of them by using Data Detectors or your own parsers. And most importantly, you know what you're building. You know what type of data that you have to look at. And so we recommend that you leverage your domain knowledge for the best user experience.
So, we hope that gave you good reference point for starting integrating Text Recognition into your app. I can't wait to see all the fantastic app that you're going to create using this technology. If you have question, you can visit the machine learning lab. There's one more tomorrow. Thank you very much. [ Applause ]
-