Retired Document
Important: This document may not represent best practices for current development. Links to downloads and other resources may no longer be valid.
Fetching Data
This chapter discusses the mechanics of retrieving data using Enterprise Objects.
It is divided into the following sections:
Objects Involved in Fetching describes the objects involved in retrieving data.
Flow of Data During a Fetch discusses the flow of data during a fetch.
Enterprise Object Initialization discusses how enterprise objects instances are initialized.
Faulting and Relationship Resolution describes how Enterprise Objects resolves relationships and uses faulting to improve performance.
Data Integrity Mechanisms discusses some of the data integrity mechanisms Enterprise Objects uses while fetching data, including uniquing, faulting, and snapshotting.
Ensuring Fresh Data discusses how Enterprise Objects caches fetched data, when it uses cached data, how to refetch data, how to clear the cache, and in general how to ensure that the enterprise object instances in your application contain fresh data.
Advanced Faulting discusses advanced faulting topics such as deferred faulting and batch faulting.
Advanced Fetching discusses advanced fetching topics such as raw row fetching and prefetching.
Common Delegate Usage discusses delegates that are commonly implemented to customize fetching.
Constructing Fetch Specifications teaches you how to build fetch specifications and how to construct qualifiers.
Filtering Fetch Results in Memory teaches you how to filter the results of a fetch in memory.
Sorting Fetch Results in Memory teaches you how to sort the results of a fetch in memory.
Accessing Database Keys discusses how to access an entity’s primary and foreign keys when they are not class properties.
Objects Involved in Fetching
There are many objects involved in retrieving data in an Enterprise Objects application. The ones you’ll most commonly work with are introduced here.
- EOFetchSpecification
A fetch specification provides a description of what data to retrieve from a data source. A fetch specification always includes the name of an entity—in Enterprise Objects, a single database fetch operation is always done from the perspective of a particular entity. A fetch specification usually includes a qualifier—specific criteria to look for when searching the database. A fetch specification can also include a sort ordering, which specifies that the result set should be sorted in a particular way.
- EOQualifier
A qualifier is often included in a fetch specification to provide criteria for a particular database fetch. There are a number of different kinds of qualifiers, some of which map to a SQL expression such as AND or OR. A qualifier is commonly compound—that is, a qualifier often consists of multiple qualifiers.
- EOSortOrdering
A sort ordering is often included in a fetch specification to specify that the fetch’s result set should be sorted in a particular way.
- EOEditingContext
In Enterprise Objects, a fetch almost always takes place within an object workspace called an editing context.
Other objects are involved in a fetch specification, such as EODatabaseContext and EOAdaptorChannel, but you rarely need to interact with these objects programmatically.
Flow of Data During a Fetch
A fetch begins with the construction of a fetch specification. You can create fetch specifications programmatically, but they are also created by various components within a WebObjects application such as display groups. You can also use EOModeler to build fetch specifications.
Once a fetch specification is created, the fetch must be initiated. Again, you commonly do this programmatically by invoking objectsWithFetchSpecification on an EOEditingContext, but it is also often done automatically by objects such as display groups.
Figure 6-1 illustrates the flow of data during a fetch.
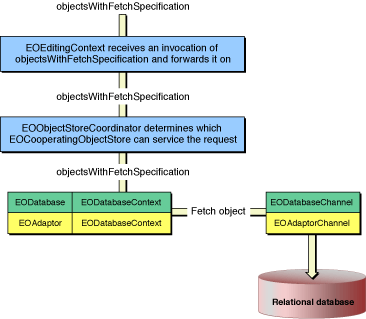
Once a fetch is initiated, the following sequence occurs to retrieve data from a data source:
When
objectsWithFetchSpecificationis invoked on an EOEditingContext, that editing context forwards the invocation on to its parent object store. The parent object store again forwards the invocation on to its parent object store until the root object store is reached (the root object store is usually an instance of EOObjectStoreCoordinator).The root object store (EOObjectStoreCoordinator) determines which of its EOCooperatingObjectStores should service the fetch specification. It forwards the
objectsWithFetchSpecificationinvocation to the determined cooperating object store to ask it to retrieve data from the data source.
How does an EOObjectStoreCoordinator determine which of its EOCooperatingObjectStores should service a particular fetch specification? Remember that within an EOModelGroup, entity names must be unique. Also remember that fetch specifications are entity-centric—every fetch specification is specified on the basis of a particular entity. So an object store coordinator simply looks for the list of entities registered within its cooperating object stores to match an entity name to particular cooperating object store.
When an EOCooperatingObjectStore receives a request to fetch data from a data source, it invokes objectsWithFetchSpecification on its EODatabaseContext object to do the work. When a database context receives this fetch request, it fetches a number of rows from the database, transforms them into enterprise objects (in most cases), and registers them as needed with the EOEditingContext that initiated the chain of objectsWithFetchSpecification invocations.
A database context uses an EODatabaseChannel to do all this. That object in turn uses an EOAdaptorChannel object to communicate directly with data sources and model-level objects—EOEntity, EOAttribute, EORelationship—that are necessary to perform the fetch.
Within EODatabaseContext, fetching occurs in two major steps:
A database context uses a database channel to select the rows in the database for which objects are being fetched. It does this using the EODatabaseChannel method
selectObjectsWithFetchSpecification, which takes as an argument the fetch specification that originated in the editing context.The database channel fetches each enterprise object, one at a time, as the database context repeatedly invokes on it the method
fetchObject. This method uses state built up in the first step to get data from the object, create an enterprise object instance if necessary, and register the new instance with the fetch’s editing context. The database channel uses the entity name specified in the fetch specification to know which enterprise object class to instantiate for every fetched object.
When an EODatabaseChannel receives an invocation of fetchObject from an EODatabaseContext, the following sequence of events occurs:
The database channel uses an EOAdaptorChannel to retrieve a record for the requested entity. The record retrieved includes the record’s primary key, class properties and client-side class properties, attributes used for locking, and any foreign keys used by the entity’s relationships.
The database channel then assigns an EOGlobalID to the row by invoking
globalIDForRow.The database channel records a snapshot for the fetched row. A global ID may already have a recorded snapshot, but if this is not the case, the method
recordSnapshotForGlobalIDis invoked on EODatabase. However, if a snapshot is already recorded for the given global ID, the database context delegate methoddatabaseContextShouldUpdateCurrentSnapshotis instead invoked. The default behavior does not update the already recorded snapshot with the new one, but you can change this by implementing the delegate method.At this point in the fetch, if the fetch specification is set to refresh refetched objects, an ObjectsChangedInStoreNotification is posted to invalidate (refault) any existing enterprise object instances that correspond to this global ID.
The database channel records whether the object was locked when it was selected. This would be the case only if you enable pessimistic locking (row-level locking) in your application.
The database channel then checks with the editing context in which the fetch originated to see whether a copy of the object already exists in that editing context. It uses the EOEditingContext method
objectForGlobalIDto do this.If the editing context contains an enterprise object for the global ID and if that enterprise object is not a fault, the editing context returns the enterprise object. Otherwise, the enterprise object returns
null.If the editing context doesn’t return an enterprise object for the global ID, the database channel invokes the EOEntityClassDescription method
createInstanceWithEditingContext, which determines the object’s class based on the fetch specification’s entity and instantiates an object of that class.The database channel invokes the method
recordObjecton the editing context to unique the newly created object. This is discussed in more detail in Uniquing.If the editing context has a fault for the global ID, the fault is cleared and initialization proceeds just as if an empty enterprise object had been created and registered.
To initialize the object, the database channel invokes the method
initializeObjecton the editing context, which is passed down the object store hierarchy. If the editing context is nested, it passes the message to its parent editing context. If the parent editing context contains an object with a matching global ID, that object is used to initialize the object in the child editing context.Otherwise, the
initializeObjectinvocation is forwarded down to the editing context’s EODatabaseContext, which initializes the new instance from the appropriate snapshot and creates faults for its relationships.initializeObjectin EODatabaseContext sets the values of the newly instantiated enterprise object’s properties usingtakeStoredValueForKey. This is described in more detail in Enterprise Object Initialization.The database channel invokes
awakeFromFetchon the new enterprise object. Custom enterprise object classes can override this method to perform additional initialization after an object has been created from a database row and initialized with database values, as described in Providing Initial Values.
Enterprise Object Initialization
The following sequence of events occurs when an object is fetched from the database:
A database row is fetched as raw binary data.
The values retrieved from that row are converted from their database-specific types to instances of standard value classes. A sample mapping of this conversion appears in Table 6-1. An application’s EOModel specifies the mapping from external data types (database type) to internal data types (Java value type).
Table 5-1 Database type to Java value type mapping Database type
Java value type
charString
dateNSTimestamp
blobNSData
intInteger
nullvalues in the database are mapped to an instance of NSKeyValueCoding.NullValue.Once the data has been converted to objects, these objects are put in an NSDictionary. The elements of the dictionary correspond to columns in the database table: Their names are the names of the attributes they map to in the EOModel and their values are the values retrieved from the database.
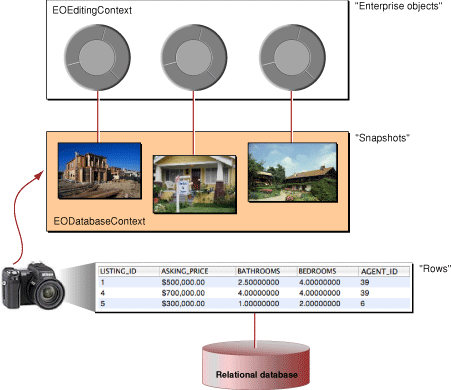
The dictionary provides a snapshot of the database row and is eventually used to initialize an enterprise object. This snapshot also participates in optimistic locking.
The dictionary contains an entry for all of a row’s columns, but an enterprise object initialized from the dictionary contains only the attributes that are defined as class properties or client-side class properties in the entity’s EOModel.
A new enterprise object is instantiated by an EOEntityClassDescription object.
The enterprise object is initialized from a row snapshot. Only objects that are class properties or client-side class properties are included. Faults are created for any references to relationships defined in the EOModel.
Figure 6-2 illustrates the relationship between database rows, database context snapshots, and enterprise object instances.
Faulting and Relationship Resolution
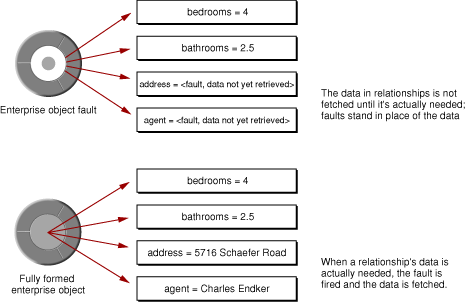
One of the most powerful and useful features of Enterprise Objects is that it automatically resolves the relationships defined in a model. It does this in part by delaying the actual retrieval of data—and delaying communicating with the database—until the data is needed, a feature of Enterprise Objects called faulting. Faulting happens in two phases: the creation of a placeholder object (a fault) for the data to be fetched, and fetching the data when it’s needed (firing a fault).
When Enterprise Objects fetches an object, it examines the object’s relationships as defined in the EOModel in which the object (entity) is defined. It then creates objects (faults) representing the destinations of the fetched object’s relationships. For example, if you fetch a Listing object that has an agent relationship and an address relationship, faults are created for the destination of those relationships, which are an Agent object and an Address object. The Agent and Address objects are not fetched (their rows in the database are not accessed) until their data is actually needed. Figure 6-3 illustrates this example.
Fetching is resource-intensive and often recursive—fetching the destination object of one enterprise object may require fetching that destination object’s destination objects, and so on until all of the interrelated rows in the database have been retrieved. To avoid this waste of time and resources, the destination objects are created as stand-ins, which are referred to as faults.
There are two kinds of faults: single-object faults for to-one relationships and array faults for to-many relationships. A single-object fault is an enterprise object instance that is associated with a particular editing context, class description, and global ID. However, the enterprise object’s data hasn’t yet been fetched from the database—you can think of a single-object fault as a shell of an enterprise object.
Array faults are instances of NSMutableArray and are triggered to fire their faults by any request for a member object or for the number of objects in the array (the number of objects in a to-many relationship can’t be determined without actually fetching them all). More specifically, array faults may start out as deferred faults, which are very small and cheap and contain little information. They may then become NSMutableArrays, which have more information about their state and contents. If an object in the relationship is then directly accessed (if an element in the array is accessed), the array fault fully fires, filling the array with enterprise objects.
You can find more information about faults in these places:
Data Integrity Mechanisms
When you work with an object graph rather than directly with data in a database, you are working with copies of that data. While working with those copies, the integrity of the data within an object graph is crucial. Enterprise Objects uses several mechanisms to ensure the integrity of the data it fetches and manages in its object graphs. These mechanisms are:
Uniquing—Enterprise Objects maintains the mapping of each enterprise object to its corresponding database row and uses this information to ensure that an object graph does not have multiple objects representing the same database row—that each enterprise object is unique within a given object graph.
Snapshotting—When Enterprise Objects fetches data, it records the state of the fetched database row in a snapshot. The information in a snapshot is used to support Enterprise Object’s optimistic locking mechanism. It is also used when changes are committed back to a data source to update only the attributes that were changed since the last fetch.
Faults—The data in the objects at the destination of a fetched object’s relationships doesn’t need to be fetched until it’s actually needed. Until that point, however, a reference to those destination objects may be necessary. These references that don’t contain data are called faults.
These topics are discussed in more detail in the following sections.
Uniquing
Uniquing is the mechanism in which Enterprise Objects ensures that a row in a database is associated with only one enterprise object in a given editing context in an application. The uniquing of enterprise objects limits memory usage and guarantees that the enterprise objects you work with represent the state of their associated database rows as they were last fetched into the object graph.
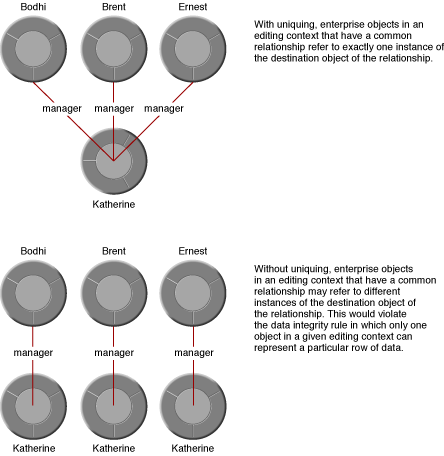
Without uniquing, a new enterprise object would be created every time you fetch its corresponding row, whether explicitly or through the resolution of relationships. For example, consider the case of a simple relationship between employees and a manager. Bodhi, Brent, and Ernest are represented by employee enterprise objects and Katherine is represented by a manager enterprise object that is the destination of the employee’s manager relationship.
Without uniquing, when the database row representing Bodhi is fetched, an object representing Bodhi’s manager, Katherine, is created to resolve his manager relationship. Then, when the database row representing Ernest is fetched, another object representing Katherine is created to resolve his manager relationship. If the row representing Katherine is itself explicitly fetched, yet another enterprise object representing Katherine is created. In this scenario, Katherine’s row in the database can be altered by multiple enterprise object instances, resulting in objects that represent the same row but that may contain different and conflicting data.
With uniquing, however, in a given editing context, only one object representing Katherine is ever created. All the enterprise objects in a given editing context that refer to Katherine’s enterprise object refer to the same instance—they have a single view of Katherine’s data. So within a given editing context, there is no ambiguity with regard to the data in Katherine’s enterprise object. These two scenarios are illustrated in Figure 6-4.
How does uniquing work? Objects are uniqued based on their global ID. A global ID (com.webobjects.eocontrol.EOGlobalID) is formed from an object’s primary key and its associated entity. When a row is fetched to create an object in a particular editing context, its global ID is checked against the objects already in the editing context. If a match is found, the newly fetched object isn’t added to the context.
A single enterprise object instance exists in one and only one EOEditingContext, but multiple copies of an object can exist in different editing contexts. In other words, the scope of object uniquing is a particular editing context.
Snapshotting
When an EODatabaseContext fetches objects from a database, a snapshot is recorded of the state of the fetched database row. A snapshot is a dictionary of a row’s primary keys, class properties, foreign keys used in relationships that are class properties, and the attributes of an entity that participate in optimistic locking. To learn how snapshots participate in optimistic locking, see Inside Optimistic Locking.
You can imagine that an application that fetches hundreds of rows of data builds up a large cache of snapshots. Theoretically, if enough fetches are performed, an Enterprise Objects application can contain all the contents of a database in memory. Clearly, snapshots must be managed in order to prevent this situation.
So how are snapshots cleaned up? This is the responsibility of a mechanism called snapshot reference counting. This mechanism keeps track of the enterprise objects that are associated with a particular snapshot—enterprise objects that contain data from a particular snapshot. When there are no remaining enterprise object instances associated with a particular snapshot (which Enterprise Objects determines by maintaining a list of these references), that snapshot is released.
Snapshot reference counting is handled automatically by the framework, so you don’t need to think about it.
Uniquing and Faulting
When a fault is constructed for a to-one relationship, the global ID for that fault is checked to see if the fault or its fully initialized enterprise object counterpart already exists in a given editing context. If so, that object is used to immediately resolve the relationship. This preserves the uniqueness requirement for enterprise objects by ensuring that there’s never more than one global ID representing the same row in the database. Whether that global ID represents an actual enterprise object or a fault doesn’t matter, since the data is fetched when it’s needed.
If Enterprise Objects fetches data for an object that’s already been created as a fault, that fault is fired and the enterprise object finishes initializing.
Ensuring Fresh Data
When developing Enterprise Objects applications, one of the most common challenges is providing users with the freshest possible data while maintaining reasonable application performance. In a multiuser database environment, there is a risk of update conflicts occurring in which multiple users access and attempt to change the same set of data simultaneously. Providing fresher data to users can help alleviate update conflicts. The philosophy of update conflicts is discussed in Update Strategies.
This section helps you understand when and how Enterprise Objects uses cached data and how you can influence the caching architecture.
When Does Database Fetching Occur?
The first thing to understand when dealing with the issue of data freshness is to understand when Enterprise Objects uses cached data and when it fetches data from a database. In most cases, if an editing context asks an enterprise object for its data, it receives cached data unless:
the timestamp of the snapshots of enterprise objects are older than the editing context’s timestamp
the enterprise object has been invalidated
the enterprise object is a fault (its data hasn’t yet been fetched)
When multiple users access the same data source by sharing an application instance, they most often share data caches. This means that one user’s data query may not actually invoke a fetch from the data source if the data requested has already been fetched by another user and so exists in the cache. A common design pattern for this situation is to provide each user with a separate snapshot cache, as discussed in Providing Separate Stacks. But even in this scenario, a user’s fetch request may not actually trigger a fetch from the database if the requested data has already been retrieved by an earlier fetch made by that user.
Distributed Change Notification?
Often, the issue of fresh data occurs when multiple users are using different application instances that all access the same data source. You want to ensure that changes one user makes are reflected in other user’s applications. Unfortunately, Enterprise Objects does not include a distributed change notification mechanism to help you with this problem (though third parties have developed solutions).
But a distributed change notification mechanism isn’t necessarily the solution. In any multiwriter database environment in which multiple users have concurrent write access to the same database, it is fundamentally impossible to guarantee fresh data. In this scenario, recovery is a better mechanism than prevention.
That is, instrumenting your applications to be resilient when update conflicts occur is a more reasonable approach than trying to prevent update conflicts altogether. Strategies for implementing resiliency are discussed in Update Strategies. That said, a mix of prevention and recovery is probably the best solution for most cases. The following sections discuss the built-in prevention mechanisms provided by the Enterprise Object frameworks.
Fetch Timestamp
Each editing context in an application includes a fetch timestamp that it uses to tell its parent object store that it wants cached data or fresh data from the database. An editing context prefers data that was fetched on or after an absolute time that is tracked by an editing context’s fetch timestamp. (Ultimately, an editing context’s parent object store decides when to perform database fetches. In the default case, an editing context’s parent object store does honor its editing context’s fetch timestamps, but this may not be the case for all object stores).
When enterprise objects are requested from an editing context, the editing context sends this request along with a fetch timestamp to its parent object store. If the requested enterprise objects have already been fetched, the parent object store finds the snapshots of those enterprise objects and compares their fetch timestamps with the fetch timestamp sent by the editing context that requested the objects.
If the timestamp of the snapshots from which the requested enterprise objects were formed is older than the editing context’s fetch timestamp, the snapshots are considered stale and fresh values for those enterprise objects are requested from the database. Otherwise, cached enterprise object values are used (these cached values are in the database context’s snapshots).
Timestamp Lag
An editing context’s fetch timestamp is set to the time of a fetch minus the default timestamp lag. The default lag is sixty minutes so the default fetch timestamp on an application’s editing contexts is one hour before a fetch occurred. So, if the timestamp of an enterprise object’s snapshots in the database context are within an hour of the fetch timestamp of the object’s editing context, a fetch returns the cached data in those snapshots rather than refetching from the database. However, if the timestamp of the snapshots in the database context are older than an hour (or older than the editing context’s fetch timestamp), the snapshots are discarded and data is refetched from the database.
A common design pattern is to set the default timestamp lag to a smaller number to encourage more refetching from the database. You can change the default timestamp lag for all the editing contexts in an application using the static method on EOEditingContext called setDefaultFetchTimestampLag. In some cases, you may want to explicitly set the fetch timestamp of a particular editing context to encourage refetching of its data. You can do this by invoking setFetchTimestamp on an editing context.
Nested editing contexts use the fetch timestamp of their parent, so applications that make heavy use of nested editing contexts may have to take additional measures to ensure fresh data.
Other Mechanisms to Ensure Freshness
Enterprise Objects provides other mechanisms to ensure the freshness of data in enterprise objects. By using the method refreshesRefetchedObjects, you force data values to be updated with fresh values from the data source when those objects are refetched. Using refreshesRefetchedObjects is described in Refreshing Cached Data.
Another, more severe mechanism to ensure fresh data is the method invalidateObjectsWithGlobalIDs on EOEditingContext, which flushes all the snapshots corresponding to the given global IDs and refetches those snapshot’s rows. It has an even more severe counterpart, invalidateAllObjects. These are rather drastic measures that you should use cautiously. See Discarding Cached Objects for more information.
As an alternative to both, you should instead consider using the method setFetchTimestampLag along with refaultAllObjects or refreshAllObjects on an editing context to update the data in enterprise objects in a given editing context.
Advanced Faulting
This section discusses the advanced faulting techniques available in Enterprise Objects.
Deferred Faulting
As described in Faulting and Relationship Resolution, Enterprise Objects uses faults to improve application performance. Fault creation is much faster than enterprise object creation and faults consume fewer resources than whole enterprise object instances. However, fault instantiation still takes time. To improve performance even further, Enterprise Objects uses deferred faults.
In an enterprise object class that can use deferred faulting, the object’s relationships are initialized as deferred faults. For a particular relationship, a single deferred fault is shared between all instances of an enterprise object class. This sharing can significantly reduce the number of faults that need to be created and usually reduces the overhead of fault creation during a fetch.
For example, consider a Listing entity that has an agent relationship. Assuming the worst case in which each Listing enterprise object has a different Agent enterprise object, without deferred faulting, a fetch of twenty Listing objects results in the creation of twenty faults for the agent relationship—a fault for each Listing. With deferred faulting, only one fault is created—a deferred fault that is shared by all the Listing objects.
If you use EOGenericRecord subclasses for your custom enterprise object classes as described in Which Enterprise Object Class?, those classes automatically use deferred faulting. If your custom enterprise object classes instead inherit from EOCustomObject and you want to enable deferred faulting in them, override the method usesDeferredFaultCreation to return true in those classes, as Listing 3-2 does. In those classes, you must also invoke willReadRelationship before accessing a relationship that might be a deferred fault.
Batch Faulting
Another advanced faulting feature is batch faulting. When a fault is fired, its data is fetched from the database. However, firing one fault has no effect on other faults—firing one fault just fetches the object or objects for the one fault. By batching fault firings together, you can more efficiently use the round trip to the database that is necessary when a single fault is fired.
For example, given an array of Employee enterprise objects, you can fetch all of the objects that are the destination of their department relationship with one round trip to the server. Without batch faulting, a round trip to the database is made to resolve each Employee’s department relationship.
There are a number of ways to implement batch faulting. You can configure batch faulting in three contexts: on entities, on relationships, and on relationships under certain circumstances.
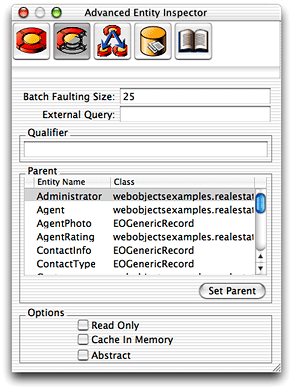
You configure batch faulting for an entity in EOModeler in an entity’s advanced inspector, as shown in Figure 6-5. The integer you specify in the Batch Faulting Size field specifies the number of faults to fire the first time a fault is fired for any relationship in that entity. You can set this size programmatically using the method in EOEntity called setMaxNumberOfInstancesToBatchFetch.
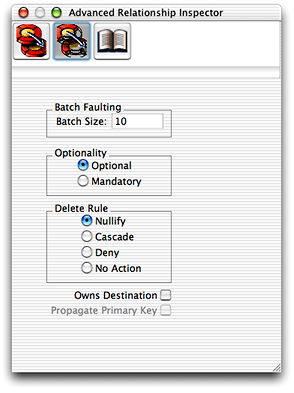
You can also specify a batch faulting size for a particular relationship. The easiest and most common way to do this is in EOModeler using the advanced relationship inspector, which is shown in Figure 6-6. The batch size specifies the number of faults to fire when the first fault in the relationship is fired.
Finally, you can take more precise control of batch faulting by explicitly batching together faults for particular objects. When you specify the batch size in EOModeler for all of an entity’s relationships or for particular relationships, you don’t actually control which faults are fired. The method batchFetchRelationship in EODatabaseContext allows you to batch fetch all of the faults in a particular relationship. The method databaseContextShouldFetchArrayFault in EODatabaseContext.Delegate allows you to turn batch faulting on and off arbitrarily. See the API reference for EODatabaseContext and EODatabaseContext.Delegate for more details.
Advanced Fetching
Enterprise Objects supports a number of advanced fetching techniques.
Prefetching
As described in Faulting and Relationship Resolution, when Enterprise Objects fetches an enterprise object, it creates faults for the object’s relationships. Each time a fault is fired, a round trip is made to the database to retrieve the fault’s data. You can batch together fault firing as described in Batch Faulting to reduce the number of round trips to the database. However, you can go even further in reducing the number of round trips to the database by prefetching all the objects in a particular relationship. Prefetching allows you to anticipate that some of an enterprise object’s relationships will be fetched and provides a mechanism to preload them; it provides a performance opportunity.
For example, consider a Listing entity that has an agent relationship. When you fetch twenty Listing objects, faults are created for each Listing’s agent relationship. When the data in the agent relationship is accessed for a particular Listing object, a fault is fired to retrieve the relationship’s data, which invokes a round trip to the database. Implementing batch faulting reduces the number of round trips but you can further reduce the number of round trips by simply prefetching all of the agent data in the database. With prefetching, when a fetch is performed for a particular entity, the objects in the relationships specified by the prefetching key paths (agent in this case) are immediately fetched.
You instrument your application for prefetching by configuring certain fetch specifications for prefetching. You can use the Prefetching pane of EOModeler’s fetch specification builder to configure it for a particular fetch specification or you can invoke setPrefetchingRelationshipKeyPaths on a fetch specification, which takes an array of strings representing the relationships to prefetch.
There are a few guidelines to consider when using prefetching. First, if memory usage is an issue for your application rather than database performance, don’t use prefetching as it consumes more memory. In fact, prefetching can consume an inordinate amount of memory depending on the size of the data set, so it’s probably more appropriate to prefetch only those relationships that have a small number of destination objects.
Second, don’t use prefetching on a fetch specification that uses a fetch limit. The prefetching hint ignores the fetch limit.
Third, don’t use prefetching when performing multiple queries that return the same records. The performance benefits of prefetching are negated by the overhead of re-creating enterprise objects of the same rows of data multiple times.
Entity Caching
Many applications have read-only entities that contain static data such as lists of states and countries, building names, or department names. Since many users of an application use the data in these entities, it makes sense to cache the data in memory to reduce the number of fetches to the database. In Enterprise Objects, you can cache an entire table in memory, thereby eliminating unnecessary fetches for the same static data by multiple users.
To enable entity caching for an entity, select the Cache In Memory option in EOModeler’s advanced entity inspector for a particular entity, as shown in Figure 6-7. You can enable this option programmatically using the method setCachesObjects on EOEntity.
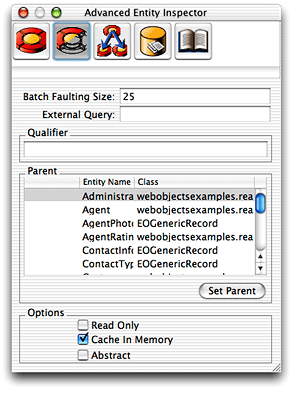
When entity caching is enabled for a particular entity, the first fetch of that entity’s table causes the whole table to be fetched into memory. Clearly, this option is appropriate only for tables with a small number of rows.
An entity’s cache of objects is maintained by an EODatabaseContext. If you provide a separate access layer stack for each user as described in Providing Separate Stacks, each session has its own EODatabaseContext, so bear in mind that entity caching in this scenario may consume a lot of memory.
Raw Row Fetching
Fetch specifications provide an option to fetch raw rows. When you use raw row fetching, database rows that are fetched are not automatically transformed into enterprise object instances. There are a number of reasons why you’d want to specify raw row fetching for a particular fetch specification. These include:
reducing memory usage when fetching large data sets
improving application performance when fetching large data sets
reducing the general overhead of an application instance
You can specify raw row fetching for a particular fetch specification either in EOModeler’s fetch specification builder or by invoking the method setFetchesRawRows on a fetch specification. You can more closely control which rows are fetched as raw rows using the method setRawRowKeyPaths on a fetch specification.
When you fetch raw rows, you lose many of the benefits of using full-fledged enterprise object instances such as the object graph, change notifications, and so forth. But many of the cases in which you need to fetch raw rows involve fetching large data sets that don’t need the benefits of the object graph, so this is an acceptable trade-off in light of the performance benefits of raw row fetching.
Plus, you can always instantiate an enterprise object of that row using the method faultForRawRow on an EOEditingContext.
Raw SQL Fetching
Although fetch specifications are the most common type of objects used to fetch data in Enterprise Objects applications, a lighter-weight mechanism is also provided that fetches raw rows based on an SQL expression you provide. This mechanism is provided as a method called rawRowsForSQL on the EOUtilities class. You pass to the method as arguments an editing context, a String representing the model that contains the entities on which to perform to the fetch, and a valid SQL expression. The results are returned as raw rows rather than as full-fledged enterprise objects.
Common Delegate Usage
A number of control points are provided that let you customize fetch operations in Enterprise Objects applications. Table 6-2 lists the delegate methods in EODatabaseContext that you can use to customize fetch operations.
You can set the delegate of EODatabaseContext by invoking the class method EODatabaseContext.setDefaultDelegate.
Constructing Fetch Specifications
You commonly create and configure fetch specifications using EOModeler’s fetch specification builder. This is described in the chapter “Working With Fetch Specifications” in EOModeler User Guide. However, you also commonly create and configure fetch specifications programmatically, as this section describes.
As discussed in Objects Involved in Fetching, a fetch specification includes an entity name, a qualifier (optional), and a sort ordering (optional). The trickiest part of building a fetch specification programmatically is building qualifiers. The code samples here assume that you’re using the Real Estate model and database.
Qualifiers
There are many ways to programmatically create a qualifier. One of the most common ways is to provide a format string to a qualifier. A format string is a logical expression that specifies parameters for performing a comparison. In a format string, you specify a data attribute to compare and a value with which to compare it. Enterprise Objects supports comparisons of equality, greater than, less than, greater than or equal to, less than or equal to, not equal, like, and case–insensitive like.
A format string also includes a conversion character, which specifies the data type of the value in the comparison. Table 6-3 lists the available conversion characters.
The following are examples of qualifier strings:
agent.firstName caseInsensitiveLike %@bedrooms >= %dbathrooms <= %d AND bedrooms = %d
The following sections provide code examples that teach you how to build format strings. Many types of format strings are possible; only a few are presented here. See the API reference for com.webobjects.eocontrol.EOQualifier for more information. The following sections provide concrete code examples that show you how to build different kinds of qualifiers, after a section introducing qualifiers.
Simple String Qualifier
The code below constructs a qualifier to find the listings associated with a particular agent, based on the agent’s last name.
EOQualifier.qualifierWithQualifierFormat("agent.lastName = %s", new NSArray(new Object[] {“Basset”, “Travers”})); |
Simple Integer Qualifier
The code below constructs a qualifier to find the listings with at least 3 bedrooms.
EOQualifier.qualifierWithQualifierFormat("bedrooms >= %d", new NSArray(new Object[] {3})); |
Wildcard Qualifiers
The code below constructs a qualifier to find the Listings associated with Agents whose first names begins with the letter b.
EOQualifier.qualifierWithQualifierFormat(“agent.lastName caseInsensitiveLike %@”, new NSArray(new Object[] {“B*”})); |
Compound Qualifiers
Providing a fetch specification with a single qualifier often doesn’t provide the precision you need for search criteria. Fortunately, you can easily form boolean combinations of qualifiers. These types of qualifiers, qualifiers composed of other qualifiers, are called compound qualifiers. Enterprise Objects supports AND, OR, and NOT boolean combinations of qualifiers.
This code builds a compound qualifier that combines the qualifiers constructed in Simple String Qualifier and in Wildcard Qualifiers:
EOQualifier compoundQualifier = new EOAndQualifier(new NSArray(new Object[] |
{EOQualifier.qualifierWithQualifierFormat("agent.lastName = %s", new NSArray(new |
Object[] {“Basset”, “Travers”})), |
EOQualifier.qualifierWithQualifierFormat(“agent.lastName caseInsensitiveLike %s”, |
new NSArray(new Object[] {“B*”}))})); |
This creates a qualifier that searches for the criteria specified in both qualifiers.
Filtering Fetch Results in Memory
A common task related to fetching data is filtering fetch results in memory. Given an array of objects to filter and a qualifier that specifies how to filter them, you can use static methods on EOQualifier to sort enterprise objects in memory. The qualifier you use to filter objects in memory is the same type of qualifier you use when fetching data. The method invocation to filter fetch results in memory is:
EOQualifier.filteredArrayWithQualifier(objects, qualifier); |
If you write custom EOQualifier subclasses, they must implement the EOQualifierEvaluation interface if you want them to participate in in-memory filtering.
Sorting Fetch Results in Memory
Another common task related to fetching data is sorting fetch results in memory. Given an array of objects to filter and a sort ordering that specifies how to sort the array, you can use static methods in EOSortOrdering to sort enterprise objects in memory. The qualifier you use to sort objects in memory is the same type of qualifier you use when fetching data.
For example, to sort an array of enterprise objects in ascending order based on a sellingPrice property, you can use the code in Listing 6-1.
Listing 5-1 Sort fetch results in memory
NSArray sortedObjects = EOSortOrdering.sortedArrayUsingKeyOrderArray(objectsToSort, new |
NSArray(new Object[] {EOSortOrdering.sortOrderingWithKey(“sellingPrice”, |
EOSortOrdering.CompareAscending)})); |
Listing 6-1 illustrates the four objects required for sorting: an array of enterprise objects to sort (objectsToSort), a String representing the property of the enterprise object to sort on (sellingPrice), an NSSelector object representing how to sort the array (EOSortOrdering.CompareAscending), and an EOSortOrdering object that is made up of the sellingPrice String and the EOSortOrdering.CompareAscending NSSelector. You then invoke EOSortOrdering.sortedArrayUsingKeyOrderArray and pass in the array of objects to sort and the EOSortOrdering object. That method returns an array that is sorted with the specified criteria.
Accessing Database Keys
One of the great benefits of the Enterprise Objects frameworks is that they insulate you from the complexities of relational databases. It does this in part by managing things like primary and foreign keys for you, automatically.
However, while developing applications, you may need to access a particular entity’s primary and foreign keys for debugging and other purposes. There are a number of facilities within the frameworks that help you do this. The recommended way is to use a fetch specification to fetch certain rows of data and set that fetch specification to fetch raw rows rather than enterprise objects. The results of the fetch return an array of dictionaries; each dictionary represents one row of data and includes keys for all of an entity’s attributes, whether or not they are class properties.
For example, consider the Listing entity in the Real Estate model. Perhaps you need to determine the primary key (the listingID attribute) of all the listings in the database and the foreign key for the agent who is responsible for each listing (the agentID attribute). Neither of these properties are class properties in the Listing entity, so invoking the key-value coding method valueForKey(“listingID”) or valueForKey(“agentID”) on a Listing enterprise object results in an exception. However, if you construct a fetch specification and set it to fetch raw rows, you can easily retrieve the values for each of these keys.
The code in Listing 6-2 provides an example of fetching all Listing records as raw rows and extracting the listingID primary key and the agentID foreign key.
Listing 5-2 Fetch Listing records as raw rows
EOFetchSpecification fs = new EOFetchSpecification("Listing", null, null); |
fs.setFetchesRawRows(true); |
NSArray rawRows = editingContext.objectsWithFetchSpecification(fs, editingContext); |
java.util.Enumeration enum = rawRows.objectEnumerator(); |
while (enum.hasMoreElements()) { |
NSDictionary row = (NSDictionary)enum.nextElement(); |
if (row != null) { |
NSLog.out.appendln("\nlistingID pk: " + row.valueForKey("listingID")); |
NSLog.out.appendln("\nagentID fk: " + row.valueForKey("agentID")); |
} |
} |
Copyright © 2002, 2007 Apple Inc. All Rights Reserved. Terms of Use | Privacy Policy | Updated: 2007-07-11