Retired Document
Important: OpenCL was deprecated in macOS 10.14. To create high-performance code on GPUs, use the Metal framework instead. See Metal.
Controlling OpenCL / OpenGL Interoperation With GCD
An application running on a host (a CPU) can route work or data (possibly in disparate chunks) to a device using the standard OpenCL and OpenGL APIs and OS X v10.7 extensions. While the device does the work it has been assigned, the host can continue working asynchronously. Eventually, the host needs results that have not yet been generated by the device performing the work. At that point, the host waits for the device to notify it that the assigned work has been completed.
OpenCL and OpenGL can also share work and data. Typically, use OpenCL to generate or modify buffer data which is then rendered by OpenGL. Or, you might use OpenGL to create an image and then post-process it using OpenCL. In either case, make sure you synchronize so that processing occurs in proper order.
You can always make sequential hard-coded calls to standard OpenCL and OpenGL functions in order to obtain fine-grained synchronization when working on shared data. You can always just intermix calls to OpenGL and OpenCL functions. (See the OpenGL and OpenGL specifications for more information.)
This chapter shows how to synchronize processing programmatically using GCD queues. You can use GCD to synchronize:
-
A host with OpenCL. (See Using GCD To Synchronize A Host With OpenCL.)
-
A host with OpenCL using a dispatch semaphore. (See Synchronizing A Host With OpenCL Using A Dispatch Semaphore.)
-
Multiple OpenCL Queues. (See Synchronizing Multiple Queues.)
Using GCD To Synchronize A Host With OpenCL
In Listing 11-1, the host enqueues data in two queues to GCD. In this example, the queued data is processed while the host continues to do its own work. When the host needs the results, it waits for both queues to complete their work.
Listing 11-1 Synchronizing the host with OpenCL processing
// Create a workgroup so host can wait for results from more than one kernel. |
dispatch_group_t group = dispatch_group_create(); |
// Enqueue some of the data to the add_arrays_kernel on q0. |
dispatch_group_async(group, q0, |
^{ // Because the call is asynchronous, |
// the host will not wait for the results. |
cl_ndrange ndrange = { 1, {0}, {N/2}, {0} }; |
add_arrays_kernel(&ndrange, a, b, c); |
}); |
// Enqueue some of the data to the add_arrays_kernel on q1. |
dispatch_group_async(group, q1, |
^{ // Because the call is asynchronous, |
// the host will not wait for the results. |
cl_ndrange ndrange = { 1, {N/2}, {N/2}, {0} }; |
add_arrays_kernel(&ndrange, a, b, c); |
}); |
// Perform more work independent of the work being done by the kernels. |
// ... |
// At this point, the host needs the results before it can proceed. |
// So it waits for the entire workgroup (on both queues) to complete its work. |
dispatch_group_wait(group, DISPATCH_TIME_FOREVER); |
Synchronizing A Host With OpenCL Using A Dispatch Semaphore
Listing 11-2 illustrates how you can use OpenCL and OpenGL together in an application. In this example, two vertex buffer objects (VBOs) created in OpenGL (not shown) represent the positions of some objects in an N-body simulation. OpenCL memory objects created from these VBOs (line [2]) allow an OpenCL kernel to operate directly on the device memory containing this data. The kernel updates these positions according to some algorithm, expressed as a per-object operation in the included kernel. The objects are then rendered in the resulting VBO using OpenGL (commented, but not shown, at [4]).
OpenCL is updating the positions on a dispatch queue that runs asynchronously with respect to the thread that does the OpenGL rendering. To ensure that the objects are not rendered before the kernel has finished updating the positions, the application uses a dispatch semaphore mechanism.
The dispatch_semaphore_t (line [1]) is created before the main loop begins. In the block submitted to the dispatch queue created in OpenCL, just after the kernel call, the semaphore is signaled. Meanwhile, the "main" thread of execution has continued along -- perhaps doing more work -- eventually arriving at the call to dispatch_semaphore_wait(...) (line [3]). The main thread stops at this point and waits until the post-kernel signal "flips" the semaphore. Once that occurs, the code can continue to the OpenGL rendering portion of the code, safe in the knowledge that the position update for this round is complete.
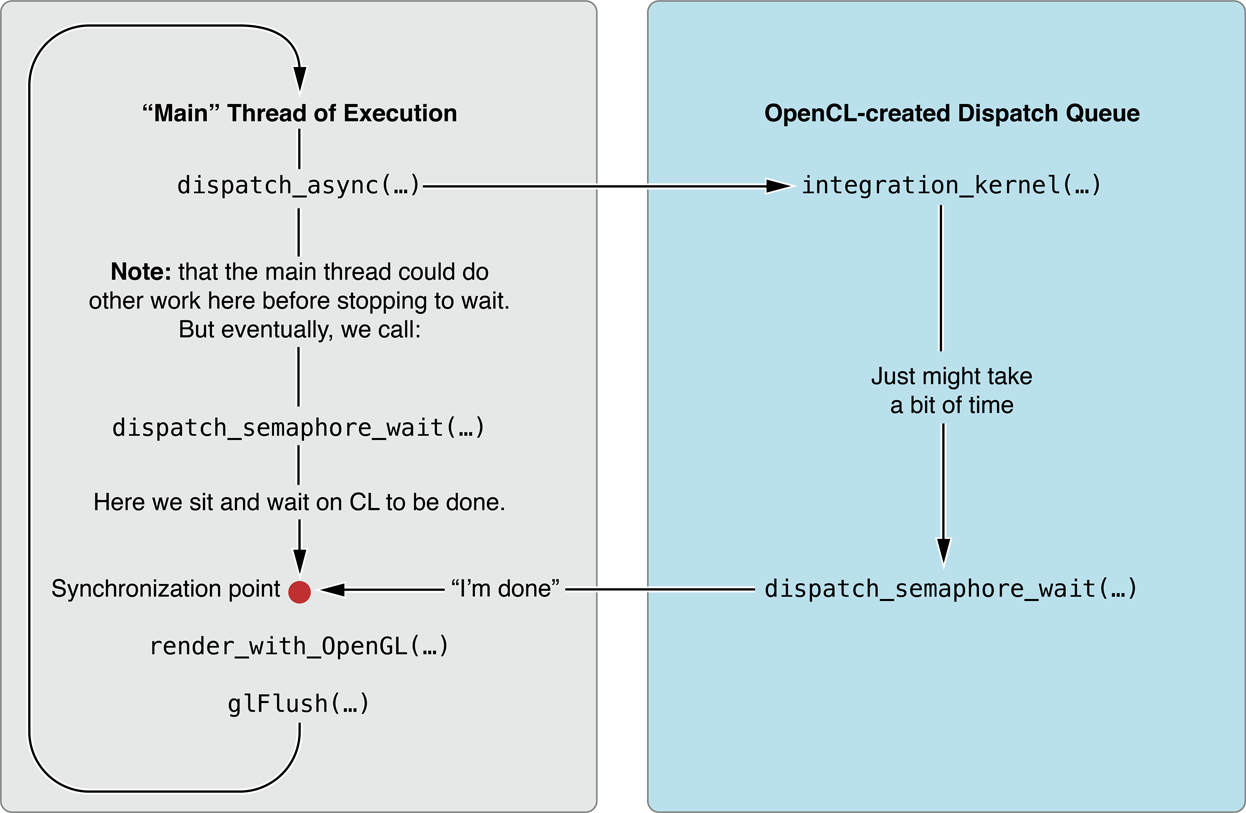
Listing 11-2 Synchronizing a host with OpenCL using a dispatch semaphore
// In this case, the kernel code updates the position of the vertex. |
// ... |
// The host code: |
// Create the dispatch semaphore. [1] |
dispatch_queue_t queue; |
dispatch_semaphore_t cl_gl_semaphore; |
void *pos_gpu[2], *vel_gpu[2]; |
GLuint vbo[2]; |
float *host_pos_data, *host_vel_data; |
int num_bodies; |
int curr_read_index, curr_write_index; |
// The extern OpenCL kernel declarations. |
extern void (^integrateNBodySystem_kernel)(const cl_ndrange *ndrange, |
float4 *newPos, float4 *newVel, |
float4 *oldPos, float4 *oldVel, |
float deltaTime, float damping, |
float softening, int numBodies, |
size_t sharedPos); |
void initialize_cl() |
{ |
gcl_gl_set_sharegroup(CGLGetShareGroup(CGLGetCurrentContext()); |
// Create a CL dispatch queue. |
queue = gcl_create_dispatch_queue(CL_DEVICE_TYPE_GPU, NULL); |
// Create a dispatch semaphore to support CL/GL data sharing. |
cl_gl_semaphore = dispatch_semaphore_create(0); |
// Create CL objects from GL VBOs that have already been created. [2] |
pos_gpu[0] = gcl_gl_create_ptr_from_buffer(vbo[0]); |
pos_gpu[1] = gcl_gl_create_ptr_from_buffer(vbo[1]); |
vel_gpu[0] = gcl_malloc(sizeof(float4)*num_bodies, NULL, 0); |
vel_gpu[1] = gcl_malloc(sizeof(float4)*num_bodies, NULL, 0); |
// Allocate and generate position and velocity data |
// in host_pos_data and host_vel_data. |
… |
// Initialize CL buffers with host position and velocity data. |
dispatch_async(queue, |
^{gcl_memcpy(pos_gpu[curr_read_index], host_pos_data, |
sizeof(float4)*num_bodies); |
gcl_memcpy(vel_gpu[curr_read_index], host_vel_data, |
sizeof(float4)*num_bodies);}); |
} |
void execute_cl_gl_main_loop() |
{ |
// Queue CL kernel to dispatch queue. |
dispatch_async(queue, |
^{ |
ndrange_t ndrange = { 1, {0}, {num_bodies} } ; |
// Get local workgroup size that kernel can use for |
// device associated with queue. |
gcl_get_kernel_block_workgroup_info( |
integrateNBodySystem_kernel, |
CL_KERNEL_WORK_GROUP_SIZE, |
sizeof(size_t), &nrange.local_work_size[0], |
NULL); |
// Queue CL kernel to dispatch queue. |
integrateNBodySystem_kernel(&ndrange, |
pos_gpu[curr_write_index], |
vel_gpu[curr_write_index], |
pos_gpu[curr_read_index], |
vel_gpu[curr_read_index], |
damping, softening, num_bodies, |
sizeof(float4)*ndrange.local_work_size[0]); |
// Signal the dispatch semaphore to indicate that |
// GL can now use resources. |
dispatch_semaphore_signal(cl_gl_semaphore);}); |
// Do work not related to resources being used by CL in dispatch block. |
// Need to use VBOs that are being used by CL so wait for the CL commands |
// in dispatch queue to be issued to the GPU’s command-buffer. [3] |
dispatch_semaphore_wait(cl_gl_semaphore, DISPATCH_TIME_FOREVER); |
// Bind VBO that has been modified by CL kernel. |
glBindBuffer(GL_ARRAY_BUFFER, pos_gpu[curr_write_index]); |
// Now render with GL. [4] |
// Flush GL commands. |
glFlush(); |
} |
void release_cl() |
{ |
gcl_free(pos_gpu[0]); |
gcl_free(pos_gpu[1]); |
gcl_free(vel_gpu[0]); |
gcl_free(vel_gpu[1]); |
dispatch_release(cl_gl_semaphore); |
dispatch_release(queue); |
} |
Synchronizing Multiple Queues
In Listing 11-3, the host enqueues data in two queues to GCD. The second queue waits for the first queue to complete its processing before doing its work. The host application does not wait for completion of either queue.
Listing 11-3 Synchronizing multiple queues
// Create the workgroup which will consist of just the work items |
// that must be completed first. |
dispatch_group_t group = dispatch_group_create(); |
dispatch_group_enter(group); |
// Start work on the workgroup. |
dispatch_async(q0, |
^{ |
cl_ndrange ndrange = { 1, {0}, {N/2}, {0} }; |
add_arrays_kernel(&ndrange, a, b, c); |
dispatch_group_leave(group); |
}); |
// Simultaneously enqueue data on q1, |
// but immediately wait until the workgroup on q0 completes. |
dispatch_async(q1, |
^{ |
// Wait for the work of the group to complete. |
dispatch_group_wait(group, DISPATCH_TIME_FOREVER); |
cl_ndrange ndrange = { 1, {N/2}, {N/2}, {0} }; |
add_arrays_kernel(&ndrange, a, b, c); |
}); |
// Host application does not wait. |
Copyright © 2018 Apple Inc. All Rights Reserved. Terms of Use | Privacy Policy | Updated: 2018-06-04