The Object Model
The insight of object-oriented programming is to combine state and behavior—data and operations on data—in a high-level unit, an object, and to give it language support. An object is a group of related functions and a data structure that serves those functions. The functions are known as the object’s methods, and the fields of its data structure are its instance variables. The methods wrap around the instance variables and hide them from the rest of the program, as Figure 3-1 illustrates.

If you’ve ever tackled any kind of difficult programming problem, it’s likely that your design has included groups of functions that work on a particular kind of data—implicit “objects” without the language support. Object-oriented programming makes these function groups explicit and permits you to think in terms of the group, rather than its components. The only way to an object’s data, the only interface, is through its methods.
By combining both state and behavior in a single unit, an object becomes more than either alone; the whole really is greater than the sum of its parts. An object is a kind of self-sufficient “subprogram” with jurisdiction over a specific functional area. It can play a full-fledged modular role within a larger program design.
For example, if you were to write a program that modeled home water usage, you might invent objects to represent the various components of the water-delivery system. One might be a Faucet object that would have methods to start and stop the flow of water, set the rate of flow, return the amount of water consumed in a given period, and so on. To do this work, a Faucet object would need instance variables to keep track of whether the tap is open or shut, how much water is being used, and where the water is coming from.
Clearly, a programmatic Faucet object can be smarter than a real one (it’s analogous to a mechanical faucet with lots of gauges and instruments attached). But even a real faucet, like any system component, exhibits both state and behavior. To effectively model a system, you need programming units, like objects, that also combine state and behavior.
A program consists of a network of interconnected objects that call upon each other to solve a part of the puzzle (as illustrated in Figure 3-2). Each object has a specific role to play in the overall design of the program and is able to communicate with other objects. Objects communicate through messages, which are requests to perform methods.
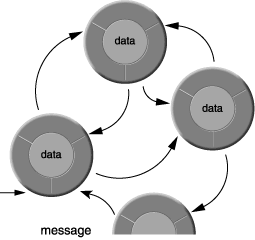
The objects in the network won’t all be the same. For example, in addition to Faucet objects, the program that models water usage might also have Pipe objects that can deliver water to the Faucet and Valve objects to regulate the flow among pipes. There could be a Building object to coordinate a set of pipes, valves, and faucets, some Appliance objects—corresponding to dishwashers, toilets, and washing machines—that can turn valves on and off, and maybe some User objects to work the appliances and faucets. When a Building object is asked how much water is being used, it might call upon each Faucet and Valve object to report its current state. When a user starts up an appliance, the appliance will need to turn on a valve to get the water it requires.
The Messaging Metaphor
Every programming paradigm comes with its own terminology and metaphors. The jargon associated with object-oriented programming invites you to think about what goes on in a program from a particular perspective.
There’s a tendency, for example, to think of objects as actors and to endow them with human-like intentions and abilities. It’s tempting sometimes to talk about an object deciding what to do about a situation, asking other objects for information, introspecting about itself to get requested information, delegating responsibility to another object, or managing a process.
Rather than think in terms of functions or methods doing the work, as you would in a procedural programming language, this metaphor asks you to think of objects as performing their methods. Objects are not passive containers for state and behavior, but are said to be the agents of the program’s activity.
This metaphor is actually very useful. An object is like an actor in a couple of respects: It has a particular role to play within the overall design of the program, and within that role it can act fairly independently of the other parts of the program. It interacts with other objects as they play their own roles, but it is self-contained and to a certain extent can act on its own. Like an actor onstage, it can’t stray from the script, but the role it plays can be multifaceted and complex.
The idea of objects as actors fits nicely with the principal metaphor of object-oriented programming—the idea that objects communicate through messages. Instead of calling a method as you would a function, you send a message to an object requesting it to perform one of its methods.
Although it can take some getting used to, this metaphor leads to a useful way of looking at methods and objects. It abstracts methods away from the particular data they act on and concentrates on behavior instead. For example, in an object-oriented programming interface, a start method might initiate an operation, an archive method might archive information, and a draw method might produce an image. Exactly which operation is initiated, which information is archived, and which image is drawn isn’t revealed by the method name. Different objects might perform these methods in different ways.
Thus, methods are a vocabulary of abstract behaviors. To invoke one of those behaviors, you have to make it concrete by associating the method with an object. This is done by naming the object as the receiver of a message. The object you choose as receiver determines the exact operation that is initiated, the data that is archived, or the image that is drawn.
Because methods belong to objects, they can be invoked only through a particular receiver (the owner of the method and of the data structure the method will act on). Different receivers can have different implementations of the same method. Consequently, different receivers can do different things in response to the same message. The result of a message can’t be calculated from the message or method name alone; it also depends on the object that receives the message.
By separating the message (the requested behavior) from the receiver (the owner of a method that can respond to the request), the messaging metaphor perfectly captures the idea that behaviors can be abstracted away from their particular implementations.
Classes
A program can have more than one object of the same kind. The program that models water usage, for example, might have several faucets and pipes and perhaps a handful of appliances and users. Objects of the same kind are said to be members of the same class. All members of a class are able to perform the same methods and have matching sets of instance variables. They also share a common definition; each kind of object is defined just once.
In this, objects are similar to C structures. Declaring a structure defines a type. For example, the declaration
struct key { |
char *word; |
int count; |
}; |
defines the struct key type. Once defined, the structure name can be used to produce any number of instances of the type:
struct key a, b, c, d; |
struct key *p = malloc(sizeof(struct key) * MAXITEMS); |
The declaration is a template for a kind of structure, but it doesn’t create a structure that the program can use. It takes another step to allocate memory for an actual structure of that type, a step that can be repeated any number of times.
Similarly, defining an object creates a template for a kind of object. It defines a class of objects. The template can be used to produce any number of similar objects—instances
of the class. For example, there would be a single definition of the Faucet class. Using this definition, a program could allocate as many Faucet instances as it needed.
A class definition is like a structure definition in that it lays out an arrangement of data elements (instance variables) that become part of every instance. Each instance has memory allocated for its own set of instance variables, which store values particular to the instance.
However, a class definition differs from a structure declaration in that it also defines methods that specify the behavior of class members. Every instance is characterized by its access to the methods defined for the class. Two objects with equivalent data structures but different methods would not belong to the same class.
Modularity
To a C programmer, a module is nothing more than a file containing source code. Breaking a large (or even not-so-large) program into different files is a convenient way of splitting it into manageable pieces. Each piece can be worked on independently and compiled alone, and then integrated with other pieces when the program is linked.
Using the static storage class designator to limit the scope of names to just the files where they’re declared enhances the independence of source modules. This kind of module is a unit defined by the file system. It’s a container for source code, not a logical unit of the language. What goes into the container is up to each programmer. You can use them to group logically related parts of the code, but you don’t have to. Files are like the drawers of a dresser; you can put your socks in one drawer, underwear in another, and so on, or you can use another organizing scheme or simply choose to mix everything up.
Object-oriented programming languages support the use of file containers for source code, but they also add a logical module to the language—class definitions. As you’d expect, it’s often the case that each class is defined in its own source file—logical modules are matched to container modules.
In Objective-C, for example, it would be possible to define the part of the Valve class that interacts with Pipe objects in the same file that defines the Pipe class, thus creating a container module for Pipe-related code and splitting the Valve class into more than one file. The Valve class definition would still act as a modular unit within the construction of the program—it would still be a logical module—no matter how many files the source code was located in.
The mechanisms that make class definitions logical units of the language are discussed in some detail under Mechanisms of Abstraction.
Reusability
A principal goal of object-oriented programming is to make the code you write as reusable as possible—to have it serve many different situations and applications—so that you can avoid reimplementing, even if only slightly differently, something that’s already been done.
Reusability is influenced by factors such as these:
-
How reliable and bug-free the code is
-
How clear the documentation is
-
How simple and straightforward the programming interface is
-
How efficiently the code performs its tasks
-
How full the feature set is
These factors don’t apply just to the object model. They can be used to judge the reusability of any code—standard C functions as well as class definitions. Efficient and well-documented functions, for example, would be more reusable than undocumented and unreliable ones.
Nevertheless, a general comparison would show that class definitions lend themselves to reusable code in ways that functions do not. There are various things you can do to make functions more reusable— for example, passing data as parameters rather than assuming specifically named global variables. Even so, it turns out that only a small subset of functions can be generalized beyond the applications they were originally designed for. Their reusability is inherently limited in at least three ways:
-
Function names are global; each function must have a unique name (except for those declared
static). This naming requirement makes it difficult to rely heavily on library code when building a complex system. The programming interface would be hard to learn and so extensive that it couldn’t easily capture significant generalizations.Classes, on the other hand, can share programming interfaces. When the same naming conventions are used over and over, a great deal of functionality can be packaged with a relatively small and easy-to-understand interface.
-
Functions are selected from a library one at a time. It’s up to programmers to pick and choose the individual functions they need.
In contrast, objects come as packages of functionality, not as individual methods and instance variables. They provide integrated services, so users of an object-oriented library won’t get bogged down piecing together their own solutions to a problem.
-
Functions are typically tied to particular kinds of data structures devised for a specific program. The interaction between data and function is an unavoidable part of the interface. A function is useful only to those who agree to use the same kind of data structures it accepts as parameters.
Because it hides its data, an object doesn’t have this problem. This is one of the principal reasons that classes can be reused more easily than functions.
An object’s data is protected and won’t be touched by any other part of the program. Methods can therefore trust its integrity. They can be sure that external access hasn’t put data into an illogical or untenable state. As a result, an object data structure is more reliable than one passed to a function, and methods can depend on it more. Reusable methods are consequently easier to write.
Moreover, because an object’s data is hidden, a class can be reimplemented to use a different data structure without affecting its interface. All programs that use the class can pick up the new version without changing any source code; no reprogramming is required.
Mechanisms of Abstraction
To this point, objects have been introduced as units that embody higher-level abstractions and as coherent role-players within an application. However, they couldn’t be used this way without the support of various language mechanisms. Two of the most important mechanisms are encapsulation and polymorphism.
Encapsulation keeps the implementation of an object out of its interface, and polymorphism results from giving each class its own namespace. The following sections discuss each of these mechanisms in turn.
Encapsulation
To design effectively at any level of abstraction, you need to be able to leave details of implementation behind and think in terms of units that group those details under a common interface. For a programming unit to be truly effective, the barrier between interface and implementation must be absolute. The interface must encapsulate the implementation—that is, hide it from other parts of the program. Encapsulation protects an implementation from unintended actions and from inadvertent access.
In C, a function is clearly encapsulated; its implementation is inaccessible to other parts of the program and protected from whatever actions might be taken outside the body of the function. In Objective-C, method implementations are similarly encapsulated, but more importantly so are an object’s instance variables. They’re hidden inside the object and invisible outside it. The encapsulation of instance variables is sometimes also called information hiding.
It might seem, at first, that hiding the information in instance variables might constrain your freedom as a programmer. Actually, it gives you more room to act and frees you from constraints that might otherwise be imposed. If any part of an object’s implementation could leak out and become accessible or a concern to other parts of the program, it would tie the hands both of the object’s implementer and of those who would use the object. Neither could make modifications without first checking with the other.
Suppose, for example, that you’re interested in the Faucet object being developed for the program that models water use and you want to incorporate it in another program you’re writing. Once the interface to the object is decided, you don’t have to be concerned when others work on it, fix bugs, and find better ways to implement it. You get the benefit of these improvements, but none of them affects what you do in your program. Because you depend solely on the interface, nothing they do can break your code. Your program is insulated from the object’s implementation.
Moreover, although those implementing the Faucet object might be interested in how you use the class and might try to make sure it meets your needs, they don’t have to be concerned with the way you write your code. Nothing you do can touch the implementation of the object or limit their freedom to make implementation changes in future releases. The implementation is insulated from anything that you or other users of the object might do.
Polymorphism
The ability of different objects to respond, each in its own way, to identical messages is called polymorphism.
Polymorphism results from the fact that every class lives in its own namespace. The names assigned within a class definition don’t conflict with names assigned anywhere outside it. This is true both of the instance variables in an object’s data structure and of the object’s methods:
-
Just as the fields of a C structure are in a protected namespace, so are an object’s instance variables.
-
Method names are also protected. Unlike the names of C functions, method names aren’t global symbols. The name of a method in one class can’t conflict with method names in other classes; two very different classes can implement identically named methods.
Method names are part of an object’s interface. When a message is sent requesting that an object do something, the message names the method the object should perform. Because different objects can have methods with the same name, the meaning of a message must be understood relative to the particular object that receives the message. The same message sent to two different objects can invoke two distinct methods.
The main benefit of polymorphism is that it simplifies the programming interface. It permits conventions to be established that can be reused in class after class. Instead of inventing a new name for each new function you add to a program, the same names can be reused. The programming interface can be described as a set of abstract behaviors, quite apart from the classes that implement them.
For example, suppose you want to report the amount of water used by an Appliance object over a given period of time. Instead of defining an amountConsumed method for the Appliance class, an amountDispensedAtFaucet method for a Faucet class, and a cumulativeUsage method for a Building class, you can simply define a waterUsed method for each class. This consolidation reduces the number of methods used for what is conceptually the same operation.
Polymorphism also permits code to be isolated in the methods of different objects rather than be gathered in a single function that enumerates all the possible cases. This makes the code you write more extensible and reusable. When a new case comes along, you don’t have to reimplement existing code; you need only to add a new class with a new method, leaving the code that’s already written alone.
For example, suppose you have code that sends a draw message to an object. Depending on the receiver, the message might produce one of two possible images. When you want to add a third case, you don’t have to change the message or alter existing code; you merely allow another object to be assigned as the message receiver.
Inheritance
The easiest way to explain something new is to start with something understood. If you want to describe what a schooner is, it helps if your listeners already know what a sailboat is. If you want to explain how a harpsichord works, it’s best if you can assume your audience has already looked inside a piano, or has seen a guitar played, or at least is familiar with the idea of a musical instrument.
The same is true if you want to define a new kind of object; the description is simpler if it can start from the definition of an existing object.
With this in mind, object-oriented programming languages permit you to base a new class definition on a class already defined. The base class is called a superclass; the new class is its subclass. The subclass definition specifies only how it differs from the superclass; everything else is taken to be the same.
Nothing is copied from superclass to subclass. Instead, the two classes are connected so that the subclass inherits all the methods and instance variables of its superclass, much as you want your listener’s understanding of schooner to inherit what they already know about sailboats. If the subclass definition were empty (if it didn’t define any instance variables or methods of its own), the two classes would be identical (except for their names) and would share the same definition. It would be like explaining what a fiddle is by saying that it’s exactly the same as a violin. However, the reason for declaring a subclass isn’t to generate synonyms; it to create something at least a little different from its superclass. For example, you might extend the behavior of the fiddle to allow it to play bluegrass in addition to classical music.
Class Hierarchies
Any class can be used as a superclass for a new class definition. A class can simultaneously be a subclass of another class, and a superclass for its own subclasses. Any number of classes can thus be linked in a hierarchy of inheritance, such as the one depicted in Figure 3-3.
Every inheritance hierarchy begins with a root class that has no superclass. From the root class, the hierarchy branches downward. Each class inherits from its superclass and, through its superclass, from all the classes above it in the hierarchy. Every class inherits from the root class.
Each class is the accumulation of all the class definitions in its inheritance chain. In the example above, class D inherits both from C—its superclass—and the root class. Members of the D class have methods and instance variables defined in all three classes—D, C, and root.
Typically, every class has just one superclass and can have an unlimited number of subclasses. However, in some object-oriented programming languages (though not in Objective-C), a class can have more than one superclass; it can inherit through multiple sources. Instead of having a single hierarchy that branches downward as shown in Figure 3-3, multiple inheritance lets some branches of the hierarchy (or of different hierarchies) merge.
Subclass Definitions
A subclass can make three kinds of changes to the definition it inherits through its superclass:
-
It can expand the class definition it inherits by adding new methods and instance variables. This is the most common reason for defining a subclass. Subclasses always add new methods and add new instance variables if the methods require it.
-
It can modify the behavior it inherits by replacing an existing method with a new version. This is done by simply implementing a new method with the same name as one that’s inherited. The new version overrides the inherited version. (The inherited method doesn’t disappear; it’s still valid for the class that defined it and other classes that inherit it.)
-
It can refine or extend the behavior it inherits by replacing an existing method with a new version, but it still retains the old version by incorporating it in the new method. A subclass sends a message to perform the old version in the body of the new method. Each class in an inheritance chain can contribute part of a method’s behavior. In Figure 3-3, for example, class D might override a method defined in class C and incorporate C’s version, while C’s version incorporates a version defined in the root class.
Subclasses thus tend to fill out a superclass definition, making it more specific and specialized. They add, and sometimes replace, code rather than subtract it. Note that methods generally can’t be disinherited and instance variables can’t be removed or overridden.
Uses of Inheritance
The classic examples of an inheritance hierarchy are borrowed from animal and plant taxonomies. For example, there could be a class corresponding to the Pinaceae (pine) family of trees. Its subclasses could be Fir, Spruce, Pine, Hemlock, Tamarack, DouglasFir, and TrueCedar, corresponding to the various genera that make up the family. The Pine class might have SoftPine and HardPine subclasses, with WhitePine, SugarPine, and BristleconePine as subclasses of SoftPine, and PonderosaPine, JackPine, MontereyPine, and RedPine as subclasses of HardPine.
There’s rarely a reason to program a taxonomy like this, but the analogy is a good one. Subclasses tend to specialize a superclass or adapt it to a special purpose, much as a species specializes a genus.
Here are some typical uses of inheritance:
-
Reusing code. If two or more classes have some things in common but also differ in some ways, the common elements can be put in a single class definition that the other classes inherit. The common code is shared and need only be implemented once.
For example,
Faucet,Valve, andPipeobjects, defined for the program that models water use, all need a connection to a water source and should be able to record the rate of flow. These commonalities can be encoded once, in a class that theFaucet,Valve, andPipeclasses inherit from. AFaucetobject can be said to be a kind ofValveobject, so perhaps theFaucetclass would inherit most of what it is fromValve, and add little of its own. -
Setting up a protocol. A class can declare a number of methods that its subclasses are expected to implement. The class might have empty versions of the methods, or it might implement partial versions that are to be incorporated into the subclass methods. In either case, its declarations establish a protocol that all its subclasses must follow.
When different classes implement similarly named methods, a program is better able to make use of polymorphism in its design. Setting up a protocol that subclasses must implement helps enforce these conventions.
-
Delivering generic functionality. One implementer can define a class that contains a lot of basic, general code to solve a problem but that doesn’t fill in all the details. Other implementers can then create subclasses to adapt the generic class to their specific needs. For example, the
Applianceclass in the program that models water use might define a generic water-using device that subclasses would turn into specific kinds of appliances.Inheritance is thus both a way to make someone else’s programming task easier and a way to separate levels of implementation.
-
Making slight modifications. When inheritance is used to deliver generic functionality, set up a protocol, or reuse code, a class is devised that other classes are expected to inherit from. But you can also use inheritance to modify classes that aren’t intended as superclasses. Suppose, for example, that there’s an object that would work well in your program, but you’d like to change one or two things that it does. You can make the changes in a subclass.
-
Previewing possibilities. Subclasses can also be used to factor out alternatives for testing purposes. For example, if a class is to be encoded with a particular user interface, alternative interfaces can be factored into subclasses during the design phase of the project. Each alternative can then be demonstrated to potential users to see which they prefer. When the choice is made, the selected subclass can be reintegrated into its superclass.
Dynamism
At one time in programming history, the question of how much memory a program might use was typically settled when the source code was compiled and linked. All the memory the program would ever need was set aside for it as it was launched. This memory was fixed; it could neither grow nor shrink.
In hindsight, it’s evident what a serious constraint this was. It limited not only how programs were constructed, but what you could imagine a program doing. It constrained design, not just programming technique. The introduction of functions that dynamically allocate memory as a program runs (such as malloc) opened possibilities that didn’t exist before.
Compile-time and link-time constraints are limiting because they force issues to be decided from information found in the programmer’s source code, rather than from information obtained from the user as the program runs.
Although dynamic allocation removes one such constraint, many others, equally as limiting as static memory allocation, remain. For example, the elements that make up an application must be matched to data types at compile time. And the boundaries of an application are typically set at link time. Every part of the application must be united in a single executable file. New modules and new types can’t be introduced as the program runs.
Objective-C seeks to overcome these limitations and to make programs as dynamic and fluid as possible. It shifts much of the burden of decision making from compile time and link time to runtime. The goal is to let program users decide what will happen, rather than constrain their actions artificially by the demands of the language and the needs of the compiler and linker.
Three kinds of dynamism are especially important for object-oriented design:
-
Dynamic typing, waiting until runtime to determine the class of an object
-
Dynamic binding, determining at runtime what method to invoke
-
Dynamic loading, adding new components to a program as it runs
Dynamic Typing
The compiler typically complains if the code you write assigns a value to a type that can’t accommodate it. You might see warnings like these:
incompatible types in assignment |
assignment of integer from pointer lacks a cast |
Type checking is useful, but there are times when it can interfere with the benefits you get from polymorphism, especially if the type of every object must be known to the compiler.
Suppose, for example, that you want to send an object a message to perform the start method. Like other data elements, the object is represented by a variable. If the variable’s type (its class) must be known at compile time, it would be impossible to let runtime factors influence the decision about what kind of object should be assigned to the variable. If the class of the variable is fixed in source code, so is the version of start that the message invokes.
If, on the other hand, it’s possible to wait until runtime to discover the class of the variable, any kind of object could be assigned to it. Depending on the class of the receiver, the start message might invoke different versions of the method and produce very different results.
Dynamic typing thus gives substance to dynamic binding (discussed next). But it does more than that. It permits associations between objects to be determined at runtime, rather than forcing them to be encoded in a static design. For example, a message could pass an object as a parameter without declaring exactly what kind of object it is—that is, without declaring its class. The message receiver might then send its own messages to the object, again without ever caring about what kind of object it is. Because the receiver uses the passed object to do some of its work, it is in a sense customized by an object of indeterminate type (indeterminate in source code, that is, not at runtime).
Dynamic Binding
In standard C, you can declare a set of alternative functions, such as the standard string-comparison functions,
int strcmp(const char *, const char *); /* case sensitive */ |
int strcasecmp(const char *, const char *); /*case insensitive*/ |
and declare a pointer to a function that has the same return and parameter types:
int (* compare)(const char *, const char *); |
You can then wait until runtime to determine which function to assign to the pointer,
if ( **argv == 'i' ) |
compare = strcasecmp; |
else |
compare = strcmp; |
and call the function through the pointer:
if ( compare(s1, s2) ) |
... |
This is akin to what in object-oriented programming is called dynamic binding, delaying the decision of exactly which method to perform until the program is running.
Although not all object-oriented languages support it, dynamic binding can be routinely and transparently accomplished through messaging. You don’t have to go through the indirection of declaring a pointer and assigning values to it as shown in the example above. You also don’t have to assign each alternative procedure a different name.
Messages invoke methods indirectly. Every message expression must find a method implementation to “call.” To find that method, the messaging machinery must check the class of the receiver and locate its implementation of the method named in the message. When this is done at runtime, the method is dynamically bound to the message. When it’s done by the compiler, the method is statically bound.
Dynamic binding is possible even in the absence of dynamic typing, but it’s not very interesting. There’s little benefit in waiting until runtime to match a method to a message when the class of the receiver is fixed and known to the compiler. The compiler could just as well find the method itself; the runtime result won’t be any different.
However, if the class of the receiver is dynamically typed, there’s no way for the compiler to determine which method to invoke. The method can be found only after the class of the receiver is resolved at runtime. Dynamic typing thus entails dynamic binding.
Dynamic typing also makes dynamic binding interesting, for it opens the possibility that a message might have very different results depending on the class of the receiver. Runtime factors can influence the choice of receiver and the outcome of the message.
Dynamic typing and binding also open the possibility that the code you write can send messages to objects not yet invented. If object types don’t have to be decided until runtime, you can give others the freedom to design their own classes and name their own data types and still have your code send messages to their objects. All you need to agree on are the messages, not the data types.
Dynamic Loading
Historically, in many common environments, before a program can run, all its parts had to be linked together in one file. When it was launched, the entire program was loaded into memory at once.
Some object-oriented programming environments overcome this constraint and allow different parts of an executable program to be kept in different files. The program can be launched in bits and pieces as they’re needed. Each piece is dynamically loaded and linked with the rest of program as it’s launched. User actions can determine which parts of the program are in memory and which aren’t.
Only the core of a large program needs to be loaded at the start. Other modules can be added as the user requests their services. Modules the user doesn’t request make no memory demands on the system.
Dynamic loading raises interesting possibilities. For example, an entire program does not have to be developed at once. You can deliver your software in pieces and update one part of it at a time. You can devise a program that groups several tools under a single interface, and load just the tools the user wants. The program can even offer sets of alternative tools to do the same job—the user then selects one tool from the set and only that tool would be loaded.
Perhaps the most important current benefit of dynamic loading is that it makes applications extensible. You can allow others to add to and customize a program you’ve designed. All your program needs to do is provide a framework that others can fill in, and, at runtime, find the pieces that they’ve implemented and load them dynamically.
The main challenge that dynamic loading faces is getting a newly loaded part of a program to work with parts already running, especially when the different parts were written by different people. However, much of this problem disappears in an object-oriented environment because code is organized into logical modules with a clear division between implementation and interface. When classes are dynamically loaded, nothing in the newly loaded code can clash with the code already in place. Each class encapsulates its implementation and has an independent namespace.
In addition, dynamic typing and dynamic binding let classes designed by others fit effortlessly into the program you’ve designed. Once a class is dynamically loaded, it’s treated no differently than any other class. Your code can send messages to their objects and theirs to yours. Neither of you has to know what classes the other has implemented. You need only agree on a communications protocol.
Copyright © 2010 Apple Inc. All Rights Reserved. Terms of Use | Privacy Policy | Updated: 2010-11-15