Retired Document
Important:
The Multiprocessing Services API is deprecated in OS X v10.8. In earlier versions of OS X, Multiprocessing Services allowed legacy apps to support multitasking. In apps that run in OS X v10.8 and later, you should use Grand Central Dispatch or POSIX threads to support multitasking. To learn about multiprocessing on OS X, see Concurrency Programming Guide; to learn about POSIX thread routines, see pthread.
About Multitasking on the Mac OS
This chapter describes the basic concepts underlying multitasking and how Multiprocessing Services uses them on Macintosh computers.
You should read this chapter if you are not familiar with multitasking or multiprocessing concepts. Note that this chapter covers mostly concepts rather than implementation or programming details. For information about actually using the Multiprocessing Services API in your application, see Using Multiprocessing Services.
Multitasking Basics
Multitasking is essentially the ability to do many things concurrently. For example, you may be working on a project, eating lunch, and talking to a colleague at the same time. Not everything may be happening simultaneously, but you are jumping back and forth, devoting your attention to each task as necessary.
In programming, a task is simply an independent execution path. On a computer, the system software can handle multiple tasks, which may be applications or even smaller units of execution. For example, the system may execute multiple applications, and each application may have independently executing tasks within it. Each such task has its own stack and register set.
Multitasking may be either cooperative or preemptive. Cooperative multitasking requires that each task voluntarily give up control so that other tasks can execute. An example of cooperative multitasking is an unsupervised group of children wanting to look at a book. Each child can theoretically get a chance to look at the book. However, if a child is greedy, he or she may spend an inordinate amount of time looking at the book or refuse to give it up altogether. In such cases, the other children are deprived.
Preemptive multitasking allows an external authority to delegate execution time to the available tasks. Preemptive multitasking would be the case where a teacher (or other supervisor) was in charge of letting the children look at the book. He or she would assign the book to each child in turn, making sure that each one got a chance to look at it. The teacher could vary the amount of time each child got to look at the book depending on various circumstances (for example, some children may read more slowly and therefore need more time).
The Mac OS 8 operating system implements cooperative multitasking between applications. The Process Manager can keep track of the actions of several applications. However, each application must voluntarily yield its processor time in order for another application to gain it. An application does so by calling WaitNextEvent, which cedes control of the processor until an event occurs that requires the application’s attention.
Multiprocessing Services allows you to create preemptive tasks within an application (or process). For example, you can create tasks within an application to process information in the background (such as manipulating an image or retrieving data over the network) while still allowing the user to interact with the application using the user interface.
Multitasking and Multiprocessing
Multitasking and multiprocessing are related concepts, but it is important to understand the distinctions between them. Multitasking is the ability to handle several different tasks at once. Multiprocessing is the ability of a computer to use more than one processor simultaneously. Typically, if multiple processors are available in a multitasking environment, then tasks can be divided among the processors. In such cases, tasks can run simultaneously. For example, if you have a large image that you need to manipulate with a filter, you can break up the image into sections, and then assign a task to process each section. If the user’s computer contains multiple processors, several tasks can be executed simultaneously, reducing the overall execution time. If only one processor exists, then the tasks are preempted in turn to give each access to the processor.
Multiple processor support is transparent in Multiprocessing Services. If multiple processors exist, then Multiprocessing Services divides the tasks among all the available processors to maximize efficiency (a technique often called symmetric multiprocessing). If only one processor exists, then Multiprocessing Services simply schedules the available tasks with the processor to make sure that each task receives attention.
Tasks and Address Spaces
On the Mac OS, all applications are assigned a process or application context at runtime. The process contains all the resources required by the application, such as allocated memory, stack space, plug-ins, non-global data, and so on. Tasks created with Multiprocessing Services are automatically associated with the creating application’s process, as shown in Figure 1-1.
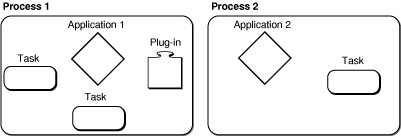
All resources within a process occupy the same address space, so tasks created by the same application are free to share memory. For example, if you want to divide an image filtering operation among multiple identical tasks, you can allocate space for the entire image in memory, and then assign each task the address and length of the portion it should process.
Task Scheduling
Multitasking environments require one or more task schedulers, which control how processor time (for one or more processors) is divided among available tasks. Each task you create is added to a task queue. The task scheduler then assigns processor time to each task in turn.
As seen by the Mac OS 9.0 task scheduler, all cooperatively multitasked programs (that is, all the applications that are scheduled by the Process Manager) occupy a single preemptive task called the Mac OS task, as shown in Figure 1-2.
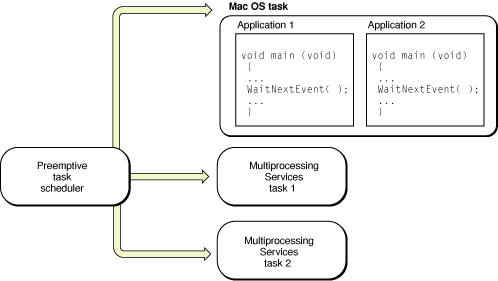
For example, if your cooperatively scheduled application creates a task, the task is preemptively scheduled. The application task (containing the main event loop) is not preemptively scheduled, but it resides within the Mac OS task, which is preemptively scheduled. Within the Mac OS task, the application must cooperatively share processor time with any other applications that are currently running.
A task executes until it completes, is blocked, or is preempted. A task is blocked when it is waiting for some event or data. For example, a task may need output from a task that has not yet completed, or it may need certain resources that are currently in use by another task.
A blocked task is removed from the task queue until it becomes eligible for execution. The task becomes eligible if either the event that it was waiting for occurs or the waiting period allowed for the event expires.
If the task does not complete or block within a certain amount of time (determined by the scheduler), the task scheduler preempts the task, placing it at the end of the task queue, and gives processor time to the next task in the queue.
Note that if the main application task is blocked while waiting for a Multiprocessing Services event, the blocking application does not get back to its event loop until the event finally occurs. This delay may be unacceptable for long-running tasks. Therefore, in general your application should poll for Multiprocessing Services events from its event loop, rather than block while waiting for them. The task notification mechanisms described in Shared Resources and Task Synchronization are ideal for this purpose.
Shared Resources and Task Synchronization
Although each created task may execute separately, it may need to share information or otherwise communicate with other tasks. For example, Task 1 may write information to memory that will be read by Task 2. In order for such operations to occur successfully, some synchronization method must exist to make sure that Task 2 does not attempt to read the memory until Task 1 has completed writing the data and until Task 2 knows that valid data actually exists in memory. The latter scenario can be an issue when using multiple processors, because the PowerPC architecture allows for writes to memory to be deferred. In addition, if multiple tasks are waiting for another task to complete, synchronization is necessary to ensure that only one task can respond at a time.
Multitasking environments offer several ways for tasks to coordinate and synchronize with each other. The sections that follow describe four notification mechanisms (or signaling mechanisms), which allow tasks to pass information between them, and one task sharing method.
Note that the time required to perform the work in a given request should be much more than the amount of time it takes to communicate the request and its results. Otherwise, delegating work to tasks may actually reduce overall performance. Typically the work performed should be greater than the intertask signaling time (20-50 microseconds).
Note that you should avoid creating your own synchronization or sharing methods, because they may work on some Mac OS implementations but not on others.
Semaphores
A semaphore is a single variable that can be incremented or decremented between zero and some specified maximum value. The value of the semaphore can communicate state information. A mail box flag is an example of a semaphore. You raise the flag to indicate that a letter is waiting in the mailbox. When the mailman picks up the letter, he lowers the flag again. You can use semaphores to keep track of how many occurrences of a particular thing are available for use.
Binary semaphores, which have a maximum value of one, are especially efficient mechanisms for indicating to some other task that something is ready. When a task or application has finished preparing data at some previously agreed to location, it raises the value of a binary semaphore that the target task waits on. The target task lowers the value of the semaphore, performs any necessary processing, and raises the value of a different binary semaphore to indicate that it is through with the data.
Semaphores are quicker and less memory intensive than other notification mechanisms, but due to their size they can convey only limited information.
Message Queues
A message queue is a collection of data (messages) that must be processed by tasks in a first-in, first-out order. Several tasks can wait on a single queue, but only one will obtain any particular message. Messages are useful for telling a task what work to do and where to look for information relevant to the request being made. They are also useful for indicating that a given request has been processed and, if necessary, what the results are.
Typically a task has two message queues, one for input and one for output. You can think of message queues as In boxes and Out boxes. For example, your In box at work may contain a number of papers (messages) indicating work to do. After completing a job, you would place another message in the Out box. Note that if you have more than one person assigned to an In box/Out box pair, each person can work independently, allowing data to be processed in parallel.
In Multiprocessing Services, a message is 96-bits of data that can convey any desired information.
Message queues incur more overhead than the other two notification mechanisms. If you must synchronize frequently, you should try to use semaphores instead of message queues whenever possible.
Event Groups
An event group is essentially a group of binary semaphores. You can use event groups to indicate a number of simple events. For example, a task running on a server may need to be aware of multiple message queues. Instead of trying to poll each one in turn, the server task can wait on an event group. Whenever a message is posted on a queue, the poster can also set the bit corresponding to that queue in the event group. Doing so notifies the task, and it then knows which queue to access to extract the message. In Multiprocessing Services, an event group consists of thirty-two 1-bit flags, each of which may be set independently. When a task receives an event group, it receives all 32 bits at once (that is, it cannot poll individual bits), and all the bits in the event group are subsequently cleared.
Kernel Notifications
A kernel notification is a set of simple notification mechanisms (semaphores, message queues, and event groups) which can be notified with only one signal. For example, a kernel notification might contain both a semaphore and a message queue. When you signal the kernel notification, the semaphore is signaled and a message is sent to the specified queue. A kernel notification can contain one of each type of simple notification mechanism.
You use kernel notifications to hide complexity from the signaler. For example, say a server has three queues to process, ranked according to priority (queue 1 holds the most important tasks, queue 2 holds lesser priority tasks, and queue 3 holds low priority tasks). The server can wait on an event group, which indicates when a task is posted to a queue.
If you do not use a kernel notification, then when a client has a message to deliver, it must both send the message to the appropriate queue and signal the event group with the correct priority value. Doing so requires the client to keep track of which queue to send to as well as the proper event group bit to set.
A simpler method is to set up three kernel notifications, one for each priority. To signal a high priority message, the client simply loads the message and signals the high priority kernel notification.
Critical Regions
In addition to notification mechanisms, you can also specify critical regions in a multitasking environment. A critical region is a section of code that can be accessed by only one task at a time. For example, say part of a task’s job is to search a data tree and modify it. If multiple tasks were allowed to search and try to modify the tree at the same time, the tree would quickly become corrupted. An easy way to avoid the problem is to form a critical region around the tree searching and modification code. When a task tries to enter the critical region it can do so only if no other task is currently in it, thus preserving the integrity of the tree.
Critical regions differ from semaphores in that critical regions can handle recursive entries and code that has multiple entry points. For example, if three functions func1, func2, and func3 access some common resource (such as the tree described above), but never call each other, then you can use a semaphore to synchronize access. However, suppose func3 calls func1 internally. In that case, func3 would obtain the semaphore, but when it calls func1, it will deadlock. Synchronizing using a critical region instead allows the same task to enter multiple times, so func1 can enter the region again when called from func3.
Because critical regions introduce forced linearity into task execution, improper use can create bottlenecks that reduce performance. For example, if the tree search described above constituted the bulk of a task’s work, then the tasks would spend most of their time just trying to get permission to enter the critical region, at great cost to overall performance. A better approach in this case might be to use different critical regions to protect subtrees. You can then have one task search one part of the tree while others were simultaneously working on other parts of the tree.
Tasking Architectures
Determining how to divide work into tasks depends greatly on the type of work you need to do and how the individual tasks rely on each other.
For a computer running multiple processors, you should optimize your multitasking application to keep them as busy as possible. You can do so by creating a number of tasks and letting the task scheduler assign them to available processors, or you can query for the number of available processors and then create enough tasks to keep them all busy.
A simple method is to determine the number of processors available and create as many tasks as there are processors. The application can then split the work into that many pieces and have each processor work on a piece. The application can then poll the tasks from its event loop until all the work is completed.
The sections that follow describe several common tasking architectures you can use to divide work among multiple processors. You might want to combine these approaches to solve specific problems or come up with your own if none described here are appropriate.
Multiple Independent Tasks
In many cases, you can break down applications into different sections that do not necessarily depend on each other but would ideally run concurrently. For example, your application may have one code section to render images on the screen, another to do graphical computations in the background, and a third to download data from a server. Each such section is a natural candidate for preemptive tasking. Even if only one processor is available, it is generally advantageous to have such independent sections run as preemptive tasks. The application can notify the tasks (using any of the three notification mechanisms) and then poll for results within its event loop.
Parallel Tasks With Parallel I/O Buffers
If you can divide the computational work of your application into several similar portions, each of which takes about the same amount of time to complete, you can create as many tasks as the number of processors and divide the work evenly among the tasks (“divide and conquer”). An example would be a filtering task on a large image. You could divide the image into as many equal sections as there are processors and have each do a fraction of the total work.
This method for using Multiprocessing Services involves creating two buffers per task: one for receiving work requests and one for posting results. You can create these buffers using either message queues or semaphores.
As shown in Figure 1-3, the application splits the data evenly among the tasks and posts a work request, which defines the work a task is expected to perform, to each task’s input buffer. Each task asks for a work request from its input buffer, and blocks if none is available. When a request arrives, the task performs the required work and then posts a message to its output buffer indicating that it has finished and providing the application with the results.
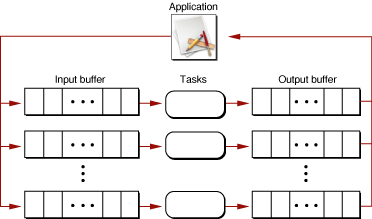
Parallel Tasks With a Single Set of I/O Buffers
If you can divide the computational work of your application into portions that can be performed by identical tasks but you can’t predict how long each computation will take, you can use a single input buffer for all your tasks. The application places each work request in the input buffer, and each free task asks for a work request. When a task finishes processing the request, it posts the result to a single output buffer shared by all the tasks and asks for a new request from the input buffer. This method is analogous to handling a queue of customers waiting in a bank line. There is no way to predict which task will process which request, and there is no way to predict the order in which results will be placed in the output buffer. For this reason, you might want to have the task include the original work request with the result so the application can determine which result is which.
As in the “divide and conquer” architecture, the application can check events, control data flow, and perform some of the calculations while the tasks are running.
Figure 1-4 illustrates this “bank line” tasking architecture.
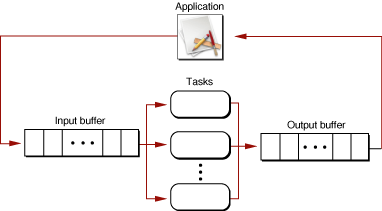
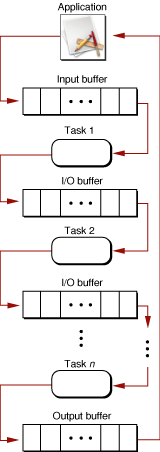
Sequential Tasks
For some applications, you may want to create several different tasks, each of which performs a different function. Some of these tasks might be able to operate in parallel, in which case you can adapt the “divide and conquer” model to perform the work. However, sometimes the output of one task is needed as the input of another. For example a sound effects application may need to process several different effects in sequence (reverb, limiting, flanging, and so on). Each task can process a particular effect, and the output of one task would feed into the input of the next. In this case, a sequential or “pipeline” architecture is appropriate.
Note that a sequential task architecture benefits from multiple processors only if several of the tasks can operate at the same time; that is, new data must be entering the pipeline while other tasks are processing data further down the line. It is harder with this architecture than with parallel task architectures to ensure that all processors are being used at all times, so you should add parallel tasks to individual stages of the pipeline whenever possible.
As shown in Figure 1-5, the sequential task architecture requires a single input buffer and a single output buffer for the pipeline, and intermediate buffers between sequential tasks.
Copyright © 2012 Apple Inc. All Rights Reserved. Terms of Use | Privacy Policy | Updated: 2012-07-23